









































































AMD RDNA 4 para las RX 9000: estas son las novedades en cuanto a instrucciones para la arquitectura
Presentada la arquitectura, presentadas las gráficas, lanzadas las reviews y ya a la venta, solo nos queda hablar de una cosa: el set de instrucciones que trae consigo RDNA 4. Lo curioso de esto es que aquí los cambios son pocos, pero afectan directamente a la parte de la arquitectura en sí, la cual, ha La entrada AMD RDNA 4 para las RX 9000: estas son las novedades en cuanto a instrucciones para la arquitectura aparece primero en El Chapuzas Informático.

Presentada la arquitectura, presentadas las gráficas, lanzadas las reviews y ya a la venta, solo nos queda hablar de una cosa: el set de instrucciones que trae consigo RDNA 4. Lo curioso de esto es que aquí los cambios son pocos, pero afectan directamente a la parte de la arquitectura en sí, la cual, ha implementado más novedades que instrucciones, algunas vistas anteriormente, por ejemplo, con lo que vimos en RDNA 3.5. Aquí, AMD da un paso más, pero realmente no es nada disruptivo, y por ello, aunque pocas, deben entenderse correctamente al unirse a las mejoras de la arquitectura. Estas son las novedades en el set de instrucciones de RDNA 4.
Vamos a explicar los cambios de forma puntualizada y pormenorizada, para una vez entendidos, nos iremos directamente a introducirlos en los correspondientes apartados de la arquitectura. Así será un poco más fácil comprender los motivos de dichos cambios, pero sobre todo qué están mejorando.
AMD RDNA 4, set de instrucciones de la arquitectura para las RX 9000, ¿qué cambios hay?
Para sorpresa de muchos, que esperarían algo revolucionario, nada de eso. Como vimos brevemente en la arquitectura en diversos artículos, los cambios no son mayores, sino menores, por eso se dice que RDNA 4 es una arquitectura intermedia entre RDNA 3 y UDNA, no es un verdadero salto más allá del Ray Tracing y los cuatro puntos que vamos a ver a continuación.
Instruction Skipping: EXEC=0
Son unas instrucciones que se han añadido a la arquitectura para el llamado Shader Hardware. Su función es simple: omitir el vector de instrucción cuando EXEC==0. Dicho en otras palabras, ahora la arquitectura puede omitir esta instrucción en varios parámetros de manera más eficiente cuando no hay hilos activos en una Wave.
RDNA 3 tenía un problema aquí, puesto que cuando dichos hilos de una Wave estaban inactivos, es decir, EXEC==0, la GPU gastaba ciclos ejecutando instrucciones que no debía. Por lo tanto, RDNA 4, si detecta EXEC==0, omite dichas instrucciones y no las procesa, no consumiendo dichos ciclos, lo que repercute en una mejor eficiencia y rendimiento.
Dynamic VGPR Allocation & Deallocation
Es, posiblemente, el apartado más clave del set de instrucciones y más fácilmente entendible dentro de lo que es la arquitectura. Es un mecanismo para los Vector General-Purpose Registers, es decir, los registros vectoriales (192 KB en RDNA 4, 128 KB en RDNA 3 y RDNA 3.5), donde los Compute Shaders ahora pueden ejecutarse en un nuevo modo donde asignan y liberan estos VGPR de forma dinámica, de ahí su nombre.
Realmente hay que hacer una distinción aquí para comprenderlo y no liarnos. AMD diferencia entre Compute Shaders y Graphic Shaders, donde los primeros se usan para GPGPU, como IA, mientras que los segundos están pensados para los gráficos 3D, es decir, Vertex, Pixel y demás.
Sabiendo esto, y que esta instrucción no está disponible para los Graphic Shaders, solo debemos saber que la Wave de turno que se inició debe hacerse en este modo si se quiere aprovechar (lógico), porque el resto serán ignoradas, no podrán modificar los VGPR. Además, AMD incide en el hecho de que solo se podrán usar en Wave32, no en Wave64, que no es lo ideal, pero es comprensible en esta primera etapa.
Esto es crítico, puesto que una vez que un WorkGroup usa Dynamic VGPR, este toma el control de todo el WGP al completo, lo mismo si es para todo un CU. El apartado de Allocation & Deallocation se hace en base a 16 o 32 registros, los cuales son configurables en números más altos con secuencias contiguas desde un VGPR0.
Memory Alignment and Out-of-Range Behavior

Es otro de los grandes apartados, en este caso, para la memoria. Si miramos el set de instrucciones de RDNA 3 frente al de RDNA 4, nos daremos cuenta de que AMD lo ha movido de sitio, no está donde estaba, y esto es debido a que está dentro de una nueva jerarquía de memoria para mejorar la comprensión de cómo se manejan ahora los accesos.
Esto es debido a la arquitectura y sus cambios, puesto que ahora RDNA 4 introduce out-of-order memory queues, que no es más que una mejora en las peticiones y cola de memoria para impulsar la ejecución según el nuevo orden establecido, no por el de la solicitud original.
Esto afecta a cualquier acceso a la memoria y es un cambio importantísimo. El motivo es la mejor gestión de la memoria privada en base a una nueva Scratch Private Memory. Este nuevo apartado dentro del Out-of-order-memory queues no es más que una manera de asignar bloques de memoria global cuando la Wave es lanzada, lo que ahora le otorga la capacidad para ser utilizada como datos privados en un subproceso.
Por lo tanto, cada subproceso tiene esta nueva memoria privada donde su transferencia está optimizada para, si se diese el caso, donde cada uno de los subprocesos tuviese el mismo espacio de trabajo dentro del CU. En otras palabras, cada subproceso para la Wave ahora tiene su parte de memoria privada y no compartida, lo que garantiza su integridad.
Cambios en los registros de las Waves

Es el último apartado y el más obvio y lógico después de leer los otros tres. No es más que un cambio en los registros del estado de cada Wave, de manera que hay tres reoganizaciones para mejorar los estados de control y gestión en la ejecución de las instrucciones. Hay tres modificaciones:
- STATUS Register, donde se añaden DYN_VGPR_EN, que como supondrás, indica que la Wave en uso está usando los VGPR dinámicos comentados arriba. Además, hay un segundo valor, NO_VGPRS, que informa sobre el hecho de que la Wave ha liberado sus VGPRS.
- STATE_PRIV Register, realmente no tiene mucho que decir más allá de incluir bits adicionales como WG_RR_EN (arbitraje round-robin de workgroups) y BARRIER_COMPLETE. Se usan para informar sobre si la barrera está completa y finalizada para la Wave de turno.
- EXEC Initialization. Totalmente relacionado con el primer punto que hemos visto. Sirve para indicar cómo se inicia el registro EXEC, donde ahora tiene la capacidad de ser inicializado a cero para Waves nulas que termina su ejecución de inmediato, ahorrando recursos y energía.
El set de instrucciones de RDNA 4 para las RX 9000 y su importancia en la arquitectura

Ni que decir tiene que estos cambios, aunque no son demasiados, afectan directamente a la arquitectura de una manera totalmente directa.
Por ejemplo, entendiendo la evolución del CU de RDNA 4, donde se mantienen muchas de las unidades de RDNA 3 y se mejoran las unidades escalares con Float32 y los nuevos Scheduler, los nuevos VGPR tienen mucho que decir aquí.

TIenen Prefetch de instrucciones mejorado, lo que les permite traer instrucciones a la caché de instrucciones en base a la dirección relativa, se ha mejorado la resolución de dependencia de datos, por no hablar de las barreras ya vistas. Todo ello sumado a las mejoras de los VGPR hacen que un Shader en RDNA 4 pueda solicitar registros cuando lo necesite, es obvio, pero también que los liberen cuanto terminen.
Esto ayuda a reducir la fragmentación de los mismos, permite ejecutar más hilos en paralelo, y con ello, logran impulsar el rendimiento en Ray Tracing e IA de cara a los AI Accelerator y Ray Accelerator. No olvidemos que ahora los primeros pueden trabajar con 8b Float, 2x16b y 4x8b, o bien, 4b dense como tipos de datos. Los segundos también han mejorado mucho, con instance transforms, 2xbox con unidades para intersección de triángulos en Ray Tracing y soporte para BVH8.
El apartado de memoria es, sin duda, la gran clave de RDNA 4

RDNA 3 tenía un problema clave aquí que limitaba su rendimiento: las peticiones de la memoria estaban totalmente ordenadas, es decir, no había forma de cambiar dicho orden por parte de la GPU, y no hay que ser muy inteligente para entender que esto es una limitación importante en gaming.
Si las solicitudes de memoria tenían que cumplirse en el orden concreto, imaginemos una operación con una latencia muy alta dentro de la memoria, sobre todo en Ray Tracing. Imaginad un árbol BVH realmente complejo. RDNA 3 tenía que resolverlo para pasar a la siguiente operación, es decir, bloqueaba todas las operaciones de menor calado de la Wave.
Por eso el añadir las colas para out of order en memoria. La diferencia de RDNA 4 frente a RDNA 3 es que la primera coge las solicitudes de memoria y las completa tan pronto como los datos estén listos, le da igual que el resto de solicitudes más complejas y lentas no lo estén, procesa los datos y reduce la latencia general, mejorando de paso la eficiencia energética.
Ahora entendemos por qué esto es realmente la clave de RDNA 4, pero hay más. Esto tiene más tela que cortar por pura obviedad. Pensad en las Waves que vienen de diferentes Shaders. Estas pueden ahora recibir y tramitar, resolver y completar sus datos sin ningún tipo de bloqueo entre sí, donde las más rápidas terminarán antes y las más lentas después.
Esto es super útil para impulsar el rendimiento en Ray Tracing, porque el acceso a la memoria de un BVH fuera de caché comienza a trabajarse mientras el resto de operaciones en memoria para vectores y escalares sigue su curso. Por todo lo dicho es fácil llegar a la conclusión de que RDNA 4 con este set de instrucciones de nueva factura y las mejoras en la arquitectura puede procesar más operaciones de memoria en paralelo, lo que ayuda a impulsar el rendimiento en todas las áreas, siendo esta, con diferencia la más importante de todas.
Mejoras en Ray Tracing
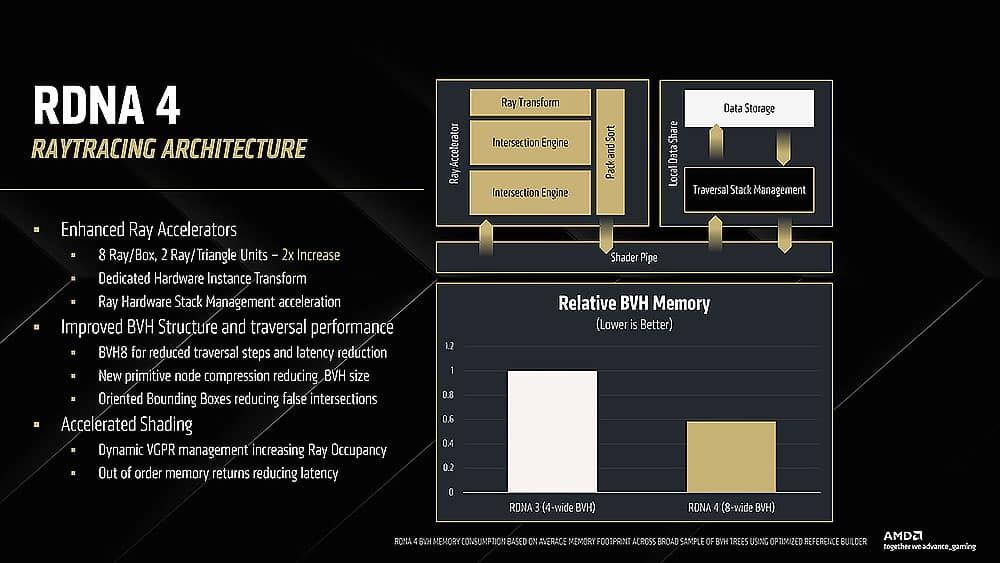


Aunque hemos comentado más arriba las bondades de los Ray Accelerator de 3ª generación y las AI Accelerator (Matrix Acceleration) tenemos que hablar, aunque sea brevemente, de los nuevos algoritmos para los BVH con optimización para Bounding Boxes Orientadas, u OBB.
Al duplicar las unidades de intersección de rayos y triángulos, se mejora la gestión del stack de hardware para Ray Tracing, y por eso se usa BVH8.

Esto reduce el tamaño del árbol y mejora la eficiencia de la gráfica y GPU cuando se usa Ray Tracing. Además, como dejamos caer más arriba, los Dynamic VGPR mejora e incrementan el llamado Ray Occupancy y las mejoras de out-of-order de la memoria reducen la latencia en la pipeline híbrida.
No es la panacea, pero junto a todo lo dicho impulsa, y mucho, en rendimiento de los Ray Accelerator y los CU en general en los juegos.
Un paso importante en IA para impulsar a FSR 4

En cuanto a la IA, otro punto importante para AMD ahora, introduce operaciones WMMA (Wave Matrix Multiply Accumulate), es decir, ahora permite multiplicaciones de matrices de manera optimizada con una mejor coordinación entre el flujo de datos y las mejoras vistas en los VGPR y la memoria con out-of-order, mejorando con ello eficiencia y energía en la GPU.
Como todo está vinculado en un paquete muy bien pensado, la latencia es otro de los factores que mejora, lo cual impulsa el rendimiento de los algoritmos de inferencia, las redes neuronales y deep learning. Esto es crucial para FSR 4, y como ya especulamos en octubre de 2024 con las llamadas AI Matrix Accelerators dedicados, ahora tenemos las Wave Matrix Multiply Accumulate, así que no íbamos nada mal encaminados de hecho.
Además, AMD ha incluido una técnica de sparsity donde solo 2 de cada 4 valores en una matriz se almacenan y procesan activamente. Esto debería duplicar el rendimiento teórico máximo de la inferencia mientras reduce el consumo, al mismo tiempo que optimiza la ejecución de modelos de redes neuronales, que es precisamente en lo que se basa FSR 4 con su Neural SuperSampling.

Además de esto, y ya para terminar, hay un nuevo sistema de Load & Transpose, que optimiza, otra vez más, siendo crucial por todo lo que hemos visto, la transferencia de datos entre memoria y VGPR. Al usar SIMD más anchas para FMA, las operaciones de matrices se aceleran y se reduce la latencia todavía más en IA, lo que mejora una vez más el rendimiento.
Visto todo, ahora entendemos un poco mejor el salto de rendimiento de RDNA 4, que, aunque está un poco por detrás de NVIDIA, y esto también hay que decirlo (al César lo que es del César) las mejoras breves, pero concisas de la arquitectura solo nos hacen soñar con una UDNA para 2027 que sea realmente algo disruptivo que puede cercar, por fin, a NVIDIA en todos los segmentos del mercado.
Si RDNA 4 ya ha puesto contra las cuerdas a los verdes con un rendimiento sólido, un consumo muy aceptable y un precio más bajo, no podemos esperar para saber qué preparan los rojos en su próxima arquitectura, pero hasta entonces, quedan modelos por ver en el mercado y disfrutarlos.
La entrada AMD RDNA 4 para las RX 9000: estas son las novedades en cuanto a instrucciones para la arquitectura aparece primero en El Chapuzas Informático.


