









































































Implementación de Modelos de Alto Rendimiento en Salesforce con AI de Amazon SageMaker
En un esfuerzo por expandir los límites de la inteligencia artificial y el procesamiento del lenguaje natural dentro de las […]
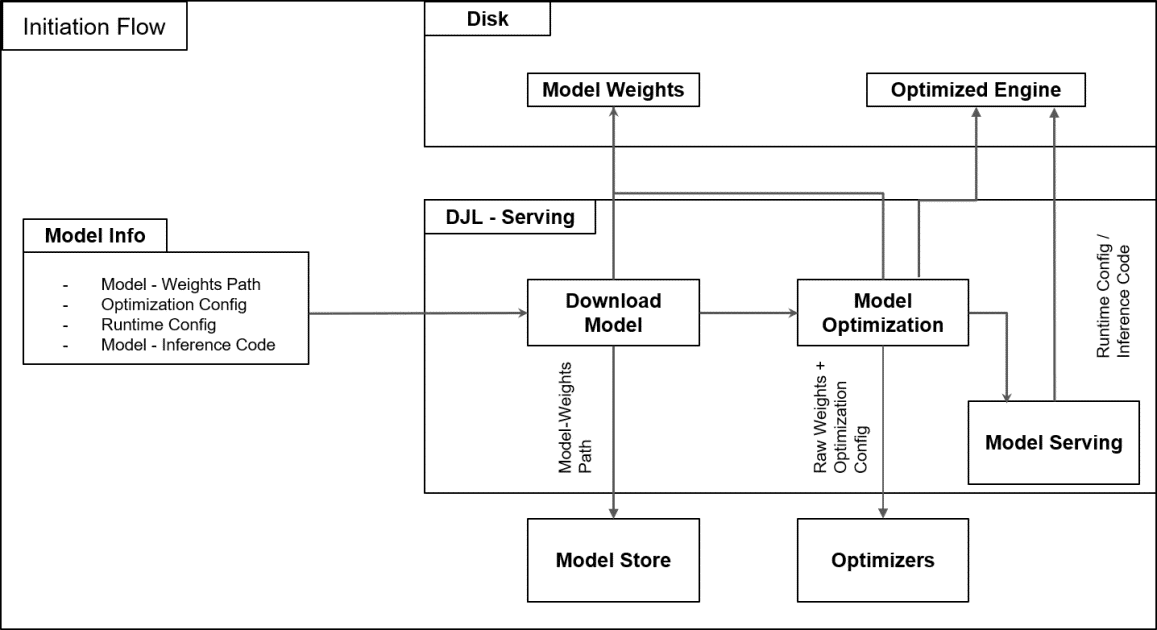
En un esfuerzo por expandir los límites de la inteligencia artificial y el procesamiento del lenguaje natural dentro de las aplicaciones empresariales, el equipo de Model Serving de Salesforce ha intensificado su enfoque en la optimización de modelos de lenguaje de gran tamaño mediante la integración de soluciones avanzadas y una estrecha colaboración con proveedores tecnológicos líderes. Este equipo no solo se centra en los modelos tradicionales de aprendizaje automático, sino que también explora áreas como la inteligencia artificial generativa, el reconocimiento de voz y la visión por computadora.
Una de las principales responsabilidades de este grupo de expertos es la gestión completa del ciclo de vida de los modelos, abarcando desde la recopilación de requisitos hasta la optimización y el escalado de las soluciones de IA, desarrolladas por los equipos de ciencia de datos e investigación de Salesforce. El objetivo primordial es lograr niveles elevados de rendimiento, priorizando la reducción de la latencia y la maximización del rendimiento mientras los modelos se lanzan en múltiples regiones de Amazon Web Services (AWS).
No obstante, Salesforce se enfrenta a desafíos significativos en esta implementación. Uno de los retos más grandes es equilibrar la latencia con el rendimiento sin comprometer la eficiencia de costos, en un contexto empresarial que exige respuestas precisas y rápidas. Además, la optimización del rendimiento debe ir de la mano con la seguridad y protección de los datos del cliente.
Para afrontar estos desafíos, el equipo ha desarrollado un marco de alojamiento en AWS que facilita la gestión del ciclo de vida de los modelos. Hacen uso de Amazon SageMaker AI, el cual proporciona herramientas para soportar inferencias distribuidas y despliegues de múltiples modelos, evitando cuellos de botella de memoria y reduciendo los costos de hardware. SageMaker también simplifica el uso de contenedores de aprendizaje profundo, acelerando tanto el desarrollo como la implementación y liberando a los ingenieros para enfocarse en optimizar los modelos en lugar de en la configuración de la infraestructura.
Salesforce ha adoptado además una serie de prácticas de configuración recomendadas para el despliegue en SageMaker AI, logrando así una utilización óptima de las GPU y una mejor asignación de memoria. Esto garantiza un despliegue rápido y eficiente de modelos optimizados que satisfacen los requisitos de alta disponibilidad y baja latencia.
Mediante un enfoque modular en el desarrollo, el equipo asegura que las mejoras en un proyecto no interfieran con otros. Continúan explorando técnicas de optimización y nuevas tecnologías para mejorar la eficiencia en costos y energía. Las colaboraciones continuas con la comunidad de código abierto y con proveedores en la nube como AWS aseguran que las últimas innovaciones sean incorporadas en sus procesos.
En cuanto a la seguridad, Salesforce implementa desde el inicio del ciclo de desarrollo altos estándares, con mecanismos de encriptación y controles de acceso para proteger los datos. Las pruebas automatizadas garantizan que la velocidad de implementación no comprometa la seguridad.
Conforme crecen las necesidades de IA generativa en Salesforce, el equipo se compromete con la mejora continua de su infraestructura de despliegue, explorando nuevas metodologías y tecnologías para mantenerse a la vanguardia en esta emocionante área de la inteligencia artificial.