









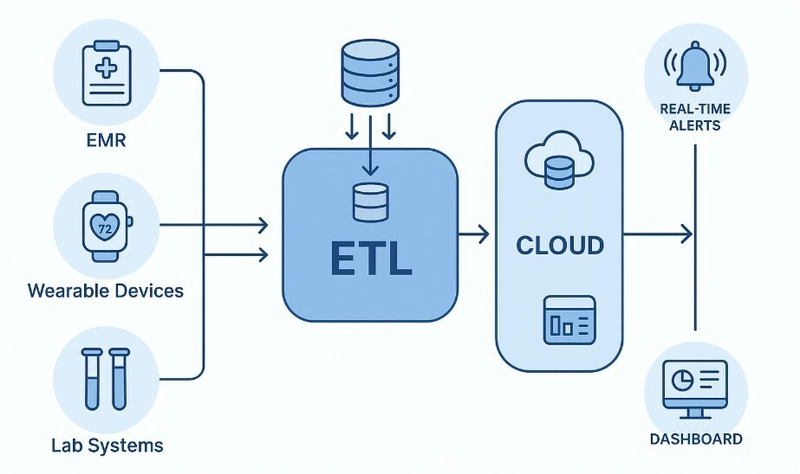


























































JSON to CSV - 01
I'll write a Python script to convert your large JSON file to CSV format. Based on the snippet you've shared, I can see it's a complex JSON with nested structures that needs careful handling for efficient processing. Here's a Python script optimized for handling large JSON files: import json import csv import os import gc from itertools import islice import ijson # You'll need to install this: pip install ijson def flatten_json(y): """Flatten a nested json structure into a single level dictionary""" out = {} def flatten(x, name=''): if type(x) is dict: for a in x: flatten(x[a], name + a + '_') elif type(x) is list: for i, a in enumerate(x): flatten(a, name + str(i) + '_') else: out[name[:-1]] = x flatten(y) return out def process_json_to_csv(json_file, csv_file, batch_size=1000): """Process large JSON file to CSV with batching for memory efficiency""" # Use ijson to parse the JSON file as a stream with open(json_file, 'rb') as f: # For an array of objects objects = ijson.items(f, 'item') # Process the first object to get the headers first_batch = list(islice(objects, batch_size)) if not first_batch: print("No data found in JSON file") return # Flatten the first batch to get all possible headers flattened_batch = [flatten_json(obj) for obj in first_batch] all_headers = set() for item in flattened_batch: all_headers.update(item.keys()) headers = sorted(list(all_headers)) # Write to CSV with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile: writer = csv.DictWriter(csvfile, fieldnames=headers) writer.writeheader() # Write the first batch for item in flattened_batch: writer.writerow(item) # Process the rest of the file in batches batch = [] for obj in objects: batch.append(flatten_json(obj)) if len(batch) >= batch_size: writer.writerows(batch) batch = [] gc.collect() # Force garbage collection # Write any remaining items if batch: writer.writerows(batch) def main(): json_file = 'your_large_file.json' # Replace with your JSON file path csv_file = 'output.csv' print(f"Converting {json_file} to {csv_file}...") process_json_to_csv(json_file, csv_file) print(f"Conversion complete! Output saved to {csv_file}") print(f"CSV file size: {os.path.getsize(csv_file) / (1024 * 1024):.2f} MB") if __name__ == "__main__": main() Key optimization techniques used in this script: Stream parsing with ijson: Instead of loading the entire JSON into memory, ijson parses the file as a stream, which is crucial for large files. Batch processing: Processing the data in batches (1000 records at a time) to control memory usage. Flattening nested structures: The flatten_json function converts nested JSON objects into a flat structure suitable for CSV. Garbage collection: Explicitly calling gc.collect() after processing each batch to free up memory. Optimized CSV writing: Using DictWriter for efficient CSV creation. You may need to adjust the script based on the exact structure of your JSON. If your JSON is not an array at the root level but has a different structure, you'll need to modify the ijson path in ijson.items(f, 'item') to match your structure. Also, if your JSON has deeply nested structures, the flattened column names could get very long. You might want to customize the flatten_json function to handle the naming scheme differently if needed. Would you like me to explain any specific part of this script in more detail?

I'll write a Python script to convert your large JSON file to CSV format. Based on the snippet you've shared, I can see it's a complex JSON with nested structures that needs careful handling for efficient processing.
Here's a Python script optimized for handling large JSON files:
import json
import csv
import os
import gc
from itertools import islice
import ijson # You'll need to install this: pip install ijson
def flatten_json(y):
"""Flatten a nested json structure into a single level dictionary"""
out = {}
def flatten(x, name=''):
if type(x) is dict:
for a in x:
flatten(x[a], name + a + '_')
elif type(x) is list:
for i, a in enumerate(x):
flatten(a, name + str(i) + '_')
else:
out[name[:-1]] = x
flatten(y)
return out
def process_json_to_csv(json_file, csv_file, batch_size=1000):
"""Process large JSON file to CSV with batching for memory efficiency"""
# Use ijson to parse the JSON file as a stream
with open(json_file, 'rb') as f:
# For an array of objects
objects = ijson.items(f, 'item')
# Process the first object to get the headers
first_batch = list(islice(objects, batch_size))
if not first_batch:
print("No data found in JSON file")
return
# Flatten the first batch to get all possible headers
flattened_batch = [flatten_json(obj) for obj in first_batch]
all_headers = set()
for item in flattened_batch:
all_headers.update(item.keys())
headers = sorted(list(all_headers))
# Write to CSV
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=headers)
writer.writeheader()
# Write the first batch
for item in flattened_batch:
writer.writerow(item)
# Process the rest of the file in batches
batch = []
for obj in objects:
batch.append(flatten_json(obj))
if len(batch) >= batch_size:
writer.writerows(batch)
batch = []
gc.collect() # Force garbage collection
# Write any remaining items
if batch:
writer.writerows(batch)
def main():
json_file = 'your_large_file.json' # Replace with your JSON file path
csv_file = 'output.csv'
print(f"Converting {json_file} to {csv_file}...")
process_json_to_csv(json_file, csv_file)
print(f"Conversion complete! Output saved to {csv_file}")
print(f"CSV file size: {os.path.getsize(csv_file) / (1024 * 1024):.2f} MB")
if __name__ == "__main__":
main()
Key optimization techniques used in this script:
Stream parsing with ijson: Instead of loading the entire JSON into memory, ijson parses the file as a stream, which is crucial for large files.
Batch processing: Processing the data in batches (1000 records at a time) to control memory usage.
Flattening nested structures: The
flatten_jsonfunction converts nested JSON objects into a flat structure suitable for CSV.Garbage collection: Explicitly calling
gc.collect()after processing each batch to free up memory.Optimized CSV writing: Using
DictWriterfor efficient CSV creation.
You may need to adjust the script based on the exact structure of your JSON. If your JSON is not an array at the root level but has a different structure, you'll need to modify the ijson path in ijson.items(f, 'item') to match your structure.
Also, if your JSON has deeply nested structures, the flattened column names could get very long. You might want to customize the flatten_json function to handle the naming scheme differently if needed.
Would you like me to explain any specific part of this script in more detail?




