






































































Improve Your Python Search Relevancy with Astra DB Hybrid Search
Astra DB now supports hybrid search, which can increase the accuracy of your search by up to 45%. It does this by performing both vector search and BM25 keyword search and then reranking the results from both to return the most relevant results. In this post, we'll take a look at how to use Astra DB Hybrid Search in Python. What is hybrid search? Before we get to the code, let's go over what hybrid search actually is and why it helps. You would typically build a retrieval-augmented generation (RAG) app by creating vector embeddings for your unstructured content and storing them in a database. Then, when a user makes a query, you turn the query into a vector embedding and use it to perform a similarity search to return relevant context that you can provide to a large language model (LLM) to generate an answer. The more accurate and relevant your search results from your database are, the better your RAG application will be. With better context, there’s less opportunity for the LLM to return inaccurate or hallucinated responses. To improve on the relevancy of this system, we need to focus on the search element. Vector search is great at understanding context and meaning, but it can miss results that would be returned from a keyword match. Meanwhile, keyword search can be restrictive as it doesn't understand context. Performing both searches gives us the best chance of returning the top results, but you then need to combine those results so you can pass them to an LLM. This is where reranking comes in. Reranking is performed by another machine learning model—a cross-encoder—that more accurately scores relevance because the model uses both the original query and the document to create the score. You can't use reranking models for search because it would require scoring every document in your database against the query every time; for small subsets of your data, however, this is achievable. You can actually use a reranker to help improve vector search results, by returning more results than required, reranking to adjust the order, then returning the top results. In hybrid search, we use reranking to rescore the combination of results from the vector and keyword searches and pick the top, most relevant results from the output. Astra DB can now perform hybrid search by combining vector search and BM25 keyword search, then reranking using the NVIDIA NeMo Retriever reranking microservices (including the nvidia/llama-3.2-nv-rerankqa-1b-v2 reranking model). Let's take a look at how to use Astra DB hybrid search to improve search relevancy in your Python application. Hybrid Search in Python with Astra DB Let's start by creating a database in your DataStax account. While it’s provisioning, let's get our coding environment set up. To use Hybrid Search in Python, you’ll need to install version 2 of astrapy as well as python-dotenv so that you can load environment variables from an .env file. Install the dependencies: pip install "astrapy>=2.0,
Astra DB now supports hybrid search, which can increase the accuracy of your search by up to 45%. It does this by performing both vector search and BM25 keyword search and then reranking the results from both to return the most relevant results.
In this post, we'll take a look at how to use Astra DB Hybrid Search in Python.
What is hybrid search?
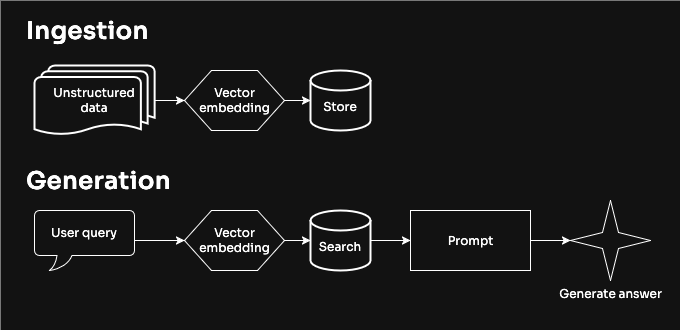
Before we get to the code, let's go over what hybrid search actually is and why it helps. You would typically build a retrieval-augmented generation (RAG) app by creating vector embeddings for your unstructured content and storing them in a database. Then, when a user makes a query, you turn the query into a vector embedding and use it to perform a similarity search to return relevant context that you can provide to a large language model (LLM) to generate an answer.
The more accurate and relevant your search results from your database are, the better your RAG application will be. With better context, there’s less opportunity for the LLM to return inaccurate or hallucinated responses.
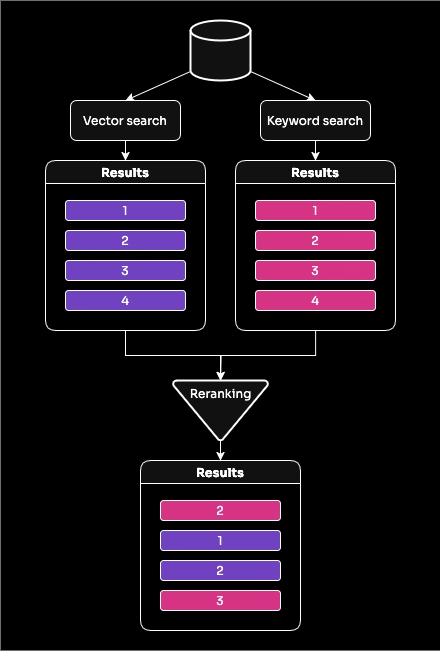
To improve on the relevancy of this system, we need to focus on the search element. Vector search is great at understanding context and meaning, but it can miss results that would be returned from a keyword match. Meanwhile, keyword search can be restrictive as it doesn't understand context. Performing both searches gives us the best chance of returning the top results, but you then need to combine those results so you can pass them to an LLM. This is where reranking comes in.
Reranking is performed by another machine learning model—a cross-encoder—that more accurately scores relevance because the model uses both the original query and the document to create the score. You can't use reranking models for search because it would require scoring every document in your database against the query every time; for small subsets of your data, however, this is achievable.
You can actually use a reranker to help improve vector search results, by returning more results than required, reranking to adjust the order, then returning the top results.
In hybrid search, we use reranking to rescore the combination of results from the vector and keyword searches and pick the top, most relevant results from the output.
Astra DB can now perform hybrid search by combining vector search and BM25 keyword search, then reranking using the NVIDIA NeMo Retriever reranking microservices (including the nvidia/llama-3.2-nv-rerankqa-1b-v2 reranking model). Let's take a look at how to use Astra DB hybrid search to improve search relevancy in your Python application.
Hybrid Search in Python with Astra DB
Let's start by creating a database in your DataStax account. While it’s provisioning, let's get our coding environment set up.
To use Hybrid Search in Python, you’ll need to install version 2 of astrapy as well as python-dotenv so that you can load environment variables from an .env file. Install the dependencies:
pip install "astrapy>=2.0,<3.0" python-dotenv
Create a file called .env and add your database API endpoint, access token and choose a name for your collection.
ASTRA_DB_API_ENDPOINT=
ASTRA_DB_APPLICATION_TOKEN=
ASTRA_DB_COLLECTION_NAME=
Creating a collection for hybrid search
Once the database is created, we'll need to create a collection to store our data in. We'll do this in code, because we want to create some settings that aren't yet available in the dashboard.
Create a file called create_collection.py and add this code:
import os
from astrapy import DataAPIClient
from astrapy.info import CollectionDefinition
from astrapy.constants import VectorMetric
from dotenv import load_dotenv
load_dotenv()
client = DataAPIClient()
db = client.get_database(
os.environ["ASTRA_DB_API_ENDPOINT"],
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
)
collection_definition = (
CollectionDefinition.builder()
.set_vector_dimension(1024)
.set_vector_metric(VectorMetric.DOT_PRODUCT)
.set_vector_service(
provider="nvidia",
model_name="NV-Embed-QA",
)
.set_lexical(
{
"tokenizer": {"name": "standard", "args": {}},
"filters": [
{"name": "lowercase"},
{"name": "stop"},
{"name": "porterstem"},
{"name": "asciifolding"},
],
}
)
)
collection = db.create_collection(
os.environ["ASTRA_DB_COLLECTION_NAME"],
definition=collection_definition,
)
In this code we create a definition for our collection and then create the collection. The definition includes details on how we want the collection to create vectors for our data as well as how it should treat the keyword search.
For vector search, we are using Astra Vectorize with the built-in NVIDIA NeMo Retriever nv-embed-qa model to create vector embeddings on insert and search. The model creates vectors with 1024 dimensions, and we configure the collection to use the dot product to calculate similarity between vectors.
For the keyword search, the default performs exact keyword matching, but we can tweak this a bit with settings like this. First, we define the tokenizer, which is how the collection breaks up the text into words. We'll use the standard tokenizer, which divides based on word boundaries and strips out punctuation. We then add filters, which transform the text to make it easier to match searches. In this case, we add four filters:
- lowercase - converts all the text to lowercase
- stop - removes English stop words
- porterstem - applies the Porter Stemming algorithm for English, which translates different forms of words to a common stem, e.g. "search", "searches", and "searched" will all translate to the token "search"
- asciifolding - translates characters into ASCII, that is it turns accented characters into an ASCII equivalent if it exists, e.g. "café" becomes "cafe"
Note that both the stop and porterstem filters are specific to English texts.
You can choose to include the filters that will work best for your data. There is more on the available filters and links to further information in the Astra DB documentation.
Now we've created our collection, we can ingest some data to search against.
Indexing data for hybrid search
Save this list of made up restaurant descriptions that we'll use as our example data as a JSON file called restaurants.json. Create a new file called ingest.py and add the following code:
import os
from astrapy import DataAPIClient
from dotenv import load_dotenv
import json
load_dotenv()
client = DataAPIClient()
db = client.get_database(
os.environ["ASTRA_DB_API_ENDPOINT"],
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
)
collection = db.get_collection(os.environ["ASTRA_DB_COLLECTION_NAME"])
with open("restaurants.json", "r") as file:
restaurant_data = json.load(file)
restaurants = [{"$hybrid": restaurant} for restaurant in restaurant_data]
collection.insert_many(restaurants)
In this code we load the restaurant descriptions and then create each as a document in Astra DB passing in the description as the $hybrid property. Creating documents with the $hybrid property does two things.
It will use the NVIDIA NeMo Retriever embedding model that we configured when we created the collection to create vector embeddings of the content. This is the same as using Astra Vectorize to generate embeddings.
It will also index the text for the new BM25 keyword search.
Run the code with:
python ingest.py
Check your collection in the DataStax dashboard, you should find both $vectorize and $lexical properties.
Performing a hybrid search
Having indexed using $hybrid, we can now perform vector and hybrid searches against this collection. Create a file called search.py and enter the following code:
import os
from astrapy import DataAPIClient
from dotenv import load_dotenv
load_dotenv()
client = DataAPIClient()
db = client.get_database(
os.environ["ASTRA_DB_API_ENDPOINT"],
token=os.environ["ASTRA_DB_APPLICATION_TOKEN"],
)
collection = db.get_collection(os.environ["ASTRA_DB_COLLECTION_NAME"])
cursor = collection.find(
sort={"$vectorize": "salads"},
limit=5,
projection={"_id": 0, "$vectorize": 1},
)
for document in cursor:
print(document)
This will perform a vector search on the collection using Astra Vectorize when you run:
python search.py
When you run this search you will see five results. In position four is "The Green Leaf Eatery," which is the most "salads" sounding place on the list to me. Positions one and two do mention salads, and, because it is vector search and not keyword search, position three, "Fusion Flavors Bistro," doesn't mention salads at all.
Now, let's update the search to use Hybrid Search and perform reranking on the results. You will need to change the find method to the new find_and_rerank method and pass {"$hybrid": query} as your sort field. You can add other arguments too, like hybrid_limits, which sets the number of documents to retrieve from each inner query before reranking, and include_scores, which shows the various scores used to rank documents along the way.
cursor = collection.find_and_rerank(
sort={"$hybrid": "salads"},
limit=5,
hybrid_limits=10,
projection={"_id": 0, "$vectorize": 1},
include_scores=True,
)
for result in cursor:
print(result.document)
print(result.scores)
Now you will see these results:
{'$vectorize': "The Green Leaf Eatery: A bright and airy vegetarian and vegan restaurant focusing on fresh, seasonal produce. Their innovative menu features creative plant-based dishes, from vibrant salads and grain bowls to hearty vegetable curries and decadent vegan desserts. It's a celebration of healthy and delicious eating."}
{'$rerank': -3.6972656, '$vector': 0.67285335, '$vectorRank': 4, '$bm25Rank': 2, '$rrf': 0.03175403}
{'$vectorize': 'The Bohemian Brew & Bites: A quirky and eclectic cafe offering a relaxed atmosphere and a diverse menu. Enjoy gourmet sandwiches on artisanal bread, creative salads with house-made dressings, and a selection of globally inspired small plates. Their extensive coffee and craft beer menu makes it the perfect spot for a casual bite or a leisurely hangout.'}
{'$rerank': -4.5507812, '$vector': 0.6813005, '$vectorRank': 2, '$bm25Rank': 3, '$rrf': 0.032002047}
{'$vectorize': 'The Olive Grove Mediterranean: Transport yourself to the sunny shores of the Mediterranean at this charming restaurant. Their menu features flavorful Greek and Turkish dishes, from grilled kebabs and savory spanakopita to creamy hummus and vibrant salads. Enjoy the fresh herbs, olive oil, and sun-drenched flavors.'}
{'$rerank': -5.1210938, '$vector': 0.68404347, '$vectorRank': 1, '$bm25Rank': 1, '$rrf': 0.032786883}
{'$vectorize': 'Fusion Flavors Bistro: A contemporary restaurant that creatively blends different culinary traditions. Expect unexpected and exciting flavor combinations, innovative presentations, and a menu that constantly evolves. This is a place for adventurous palates seeking a unique dining experience.'}
{'$rerank': -11.375, '$vector': 0.67336804, '$vectorRank': 3, '$bm25Rank': None, '$rrf': 0.015873017}
{'$vectorize': 'The Farmhouse Kitchen: A rustic and charming restaurant celebrating the bounty of the local farm. Their menu changes seasonally, featuring dishes made with the freshest ingredients sourced directly from nearby farms. Expect simple yet elegant preparations that highlight the natural flavors of the ingredients.'}
{'$rerank': -11.375, '$vector': 0.6582356, '$vectorRank': 7, '$bm25Rank': None, '$rrf': 0.014925373}
In this output, you can see the results and also the various scores that were used to rank them. You can see that "The Green Leaf Eatery" now ranks first on the list having been ranked in fourth by vector search and second by the BM25 search. The reranker lifted it up to first place.
There are other similar movements in the list, plus in the fifth position was a restaurant that was initially ranked seventh by the vector search and doesn't contain the search term "salads." Hybrid Search initially returns more results than we need, reranks them and then returns the most relevant, so this result was lifted up into a position to be returned. Positions four and five also received the same rerank score, so were placed in their order based on one more score that is calculated, reciprocal rank fusion (RRF). RRF isn't great for reranking, but is very quick, so is useful to help with tie-breaks here.
Try running vector and hybrid searches with other search terms to get a feel for the results. In our testing, we’ve seen Hybrid Search improve relevance by up to 45%.
Next, we'll take a look at a couple of other things you will need to consider when using Hybrid Search.
Providing your own vectors
The example above used Astra Vectorize to automatically create vector embeddings, but you can always use a different model and provide your own vectors.
If you do use your own vector embedding model, then you will need to provide both the vector and the text that will be indexed for keyword search. You can do this with the special property $lexical.
Imagine you have a method that creates a vector embedding called create_embedding. You might then ingest the data like this:
with open("restaurants.json", "r") as file:
restaurant_data = json.load(file)
restaurants = [
{
"$vector": create_embedding(restaurant),
"$lexical": restaurant,
"description": restaurant,
}
for restaurant in restaurant_data
]
collection.insert_many(restaurants)
Now, when you perform a hybrid search, you need to provide a $vector with which to search. Also, the default property on which the content is reranked is $vectorize, so you need to tell the database which property to rerank on too.
You also need to set the query that you want to use to perform the reranking. It can be the same query that you use for the vector search and the keyword search, or something else. You can see more about using different searches below.
You can define the query with the rerank_query argument and the field on which to perform the reranking with the rerank_on argument. For example:
query = "salad"
cursor = collection.find_and_rerank(
sort={
"$hybrid": {"$vector": create_embedding(query), "$lexical": query},
},
rerank_query=query,
rerank_on="description",
limit=5,
hybrid_limits=10,
)
for result in cursor:
print(result.document)
print(result.scores)
Performing different searches
You can also use different terms to perform your initial searches. This is useful because BM25 keyword search acts as a filter on the query keywords.
In our Hybrid Search example above, only three restaurant descriptions mentioned "salads" so only three results had a $bm25Rank in the results.
That worked fine for our example, but when we're dealing with a RAG application, the search queries are often in natural language rather than keyword focused. We already set up our collection to use word stems and translate accented characters into ASCII. You may also want to perform keyword extraction, using something like NLTK, SpaCy or keyBERT, on the user query so you can then use the keywords for the lexical search. This would look like:
query = "I'm looking for a restaurant that serves the best salad"
cursor = collection.find_and_rerank(
sort={
"$hybrid": {
"$vector": create_embedding(query),
"$lexical": extract_keywords(query),
},
},
rerank_query=query,
rerank_on="description",
limit=5,
hybrid_limits=10,
)
for result in cursor:
print(result.document)
print(result.scores)
The above code will now perform the vector search with your own vector embedding model, keyword search using keywords extracted from the user query and then rerank the results based on the initial query.
Try hybrid search for better search and RAG relevancy
Combining vector search with keyword search and a reranking model like NVIDIA NeMo Retriever nvidia/llama-3.2-nv-rerankqa-1b-v2 produces more relevant results, improving the output of your RAG application. You can get started with hybrid search and reranking in Astra DB today by signing up and using AstraPy or with Langflow.
If you want to chat more about improving retrieval accuracy, drop into the DataStax Devs Discord or drop me an email at phil.nash@datastax.com.







