















![Life in Startup Pivot Hell with Ex-Microsoft Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)





















































Building Scalable Data Pipelines: Apache SeaTunnel Meets Cloudberry
In the data-driven digital era, enterprises face unprecedented data growth and system complexity. Data is distributed across different systems, formats, and platforms, resulting in increasingly serious "information silos." Breaking these silos and achieving efficient data integration and sharing has become the key to driving intelligent decision-making and business innovation in enterprises. Apache SeaTunnel has emerged under such demands. Its simple usage, powerful plugin capabilities, and strong support for heterogeneous systems are gradually becoming a significant force in the open-source data integration field. This article starts with the challenges of data integration, delves into SeaTunnel’s design philosophy and architectural evolution, and explores its practical integration with the Cloudberry database, while discussing future directions for high-performance scenarios. The Core Value of Data Integration In the course of their development, enterprises often form multiple independent IT subsystems. Each system uses different databases, message queues, or storage engines, resulting in a complex heterogeneous environment. This kind of data fragmentation not only increases the difficulty of system integration but also hinders the efficient use of data. Data integration technology serves as the bridge connecting these systems. By abstracting, cleansing, and synchronizing data from different sources, formats, and granularities, enterprises can achieve centralized data management and multidimensional analysis, thereby unlocking the true value of their data assets. SeaTunnel: A Unified Platform for Large-Scale Heterogeneous Synchronization Apache SeaTunnel is a distributed, high-performance, pluggable data integration platform. It supports both batch and streaming data processing scenarios, making it suitable for data synchronization tasks across various heterogeneous data sources. The platform is led by Chinese developers and donated to the Apache Foundation. Its name originates from the “Waterdrop” in The Three-Body Problem, symbolizing its ability to operate efficiently even in complex environments. The core capabilities of SeaTunnel include: Unified batch and stream processing: A single data processing model; Multi-engine compatibility: Supports Spark, Flink, and the self-developed Zeta engine; Rich connector ecosystem: Supports 100+ data sources including databases, file systems, message queues, and data lakes; Pluggable architecture: Uses SPI to dynamically load plugins, offering strong extensibility; Lightweight deployment: The self-developed engine reduces external dependencies; Native CDC support: Adapts to real-time change data capture requirements. Architectural Philosophy and Technical Principles SeaTunnel’s architectural design follows the principles of “Inversion of Control (IoC)” and “Dependency Injection (DI),” abstracting the core process into three main components: Source → Transform → Sink Each component is implemented as a plugin, and the platform uses Java SPI to dynamically register and manage plugins at runtime. The data processing workflow is highly modular, allowing users to freely compose task logic and quickly build complex data integration pipelines. In the SeaTunnel architecture, thanks to the backing of the Spark and Flink distributed computing frameworks, data source abstraction is already well-handled—Flink’s DataStream and Spark’s DataFrame are highly abstracted representations of data sources. On this basis, we only need to handle these data abstractions in the plugins. Moreover, with the SQL interfaces provided by Flink and Spark, each processed dataset can be registered as a table, making SQL-based processing possible and reducing code development effort. In SeaTunnel’s latest architecture, a custom type abstraction has been implemented to achieve decoupling from specific engines. SeaTunnel has also undergone a significant architectural evolution from V1 to V2: Apache SeaTunnel V1 architecture Apache SeaTunnel V2 architecture Feature V1 V2 Engine Dependency Strong dependency on Spark, Flink No dependency Connector Implementation Need to implement multiple times for different engines Implement only once Difficulty of Engine Version Upgrade Difficult, connectors are highly coupled with the engine Easy, develop different translation layers for different versions Uniformity of Connector Parameters Parameters may differ for different engines Parameters are uniform Custom Partition Logic Relies on pre-implemented data connectors in Spark, Flink, partition logic is uncontrollable Partition logic can be customized Architecture upgrade comparison After the upgrade, Apache SeaTunnel gained new features: It not only supports multiple versions of the Flink engine and fully supports Flink’s checkpoint mechanism, but also supports Spark’s micro-batch processing mode and its batch commit cap

In the data-driven digital era, enterprises face unprecedented data growth and system complexity.
Data is distributed across different systems, formats, and platforms, resulting in increasingly serious "information silos."
Breaking these silos and achieving efficient data integration and sharing has become the key to driving intelligent decision-making and business innovation in enterprises.
Apache SeaTunnel has emerged under such demands. Its simple usage, powerful plugin capabilities, and strong support for heterogeneous systems are gradually becoming a significant force in the open-source data integration field.
This article starts with the challenges of data integration, delves into SeaTunnel’s design philosophy and architectural evolution, and explores its practical integration with the Cloudberry database, while discussing future directions for high-performance scenarios.
The Core Value of Data Integration
In the course of their development, enterprises often form multiple independent IT subsystems.
Each system uses different databases, message queues, or storage engines, resulting in a complex heterogeneous environment.
This kind of data fragmentation not only increases the difficulty of system integration but also hinders the efficient use of data.
Data integration technology serves as the bridge connecting these systems. By abstracting, cleansing, and synchronizing data from different sources, formats, and granularities, enterprises can achieve centralized data management and multidimensional analysis, thereby unlocking the true value of their data assets.

SeaTunnel: A Unified Platform for Large-Scale Heterogeneous Synchronization
Apache SeaTunnel is a distributed, high-performance, pluggable data integration platform.
It supports both batch and streaming data processing scenarios, making it suitable for data synchronization tasks across various heterogeneous data sources.
The platform is led by Chinese developers and donated to the Apache Foundation.
Its name originates from the “Waterdrop” in The Three-Body Problem, symbolizing its ability to operate efficiently even in complex environments.
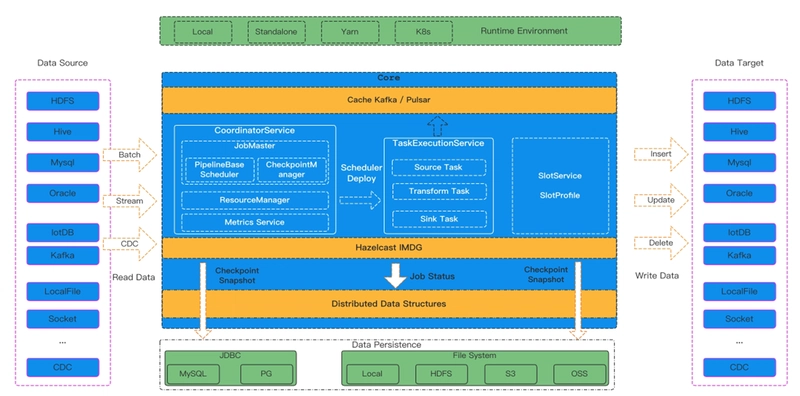
The core capabilities of SeaTunnel include:
- Unified batch and stream processing: A single data processing model;
- Multi-engine compatibility: Supports Spark, Flink, and the self-developed Zeta engine;
- Rich connector ecosystem: Supports 100+ data sources including databases, file systems, message queues, and data lakes;
- Pluggable architecture: Uses SPI to dynamically load plugins, offering strong extensibility;
- Lightweight deployment: The self-developed engine reduces external dependencies;
- Native CDC support: Adapts to real-time change data capture requirements.
Architectural Philosophy and Technical Principles
SeaTunnel’s architectural design follows the principles of “Inversion of Control (IoC)” and “Dependency Injection (DI),” abstracting the core process into three main components:
Source → Transform → Sink

Each component is implemented as a plugin, and the platform uses Java SPI to dynamically register and manage plugins at runtime.
The data processing workflow is highly modular,
allowing users to freely compose task logic and quickly build complex data integration pipelines.
In the SeaTunnel architecture, thanks to the backing of the Spark and Flink distributed computing frameworks, data source abstraction is already well-handled—Flink’s DataStream and Spark’s DataFrame are highly abstracted representations of data sources. On this basis, we only need to handle these data abstractions in the plugins.
Moreover, with the SQL interfaces provided by Flink and Spark, each processed dataset can be registered as a table, making SQL-based processing possible and reducing code development effort.
In SeaTunnel’s latest architecture, a custom type abstraction has been implemented to achieve decoupling from specific engines.
SeaTunnel has also undergone a significant architectural evolution from V1 to V2:


Apache SeaTunnel V1 architecture

Apache SeaTunnel V2 architecture
| Feature | V1 | V2 |
|---|---|---|
| Engine Dependency | Strong dependency on Spark, Flink | No dependency |
| Connector Implementation | Need to implement multiple times for different engines | Implement only once |
| Difficulty of Engine Version Upgrade | Difficult, connectors are highly coupled with the engine | Easy, develop different translation layers for different versions |
| Uniformity of Connector Parameters | Parameters may differ for different engines | Parameters are uniform |
| Custom Partition Logic | Relies on pre-implemented data connectors in Spark, Flink, partition logic is uncontrollable | Partition logic can be customized |
Architecture upgrade comparison
After the upgrade, Apache SeaTunnel gained new features:
It not only supports multiple versions of the Flink engine and fully supports Flink’s checkpoint mechanism, but also supports Spark’s micro-batch processing mode and its batch commit capabilities.
The V2 architecture further introduces the self-developed Zeta engine and an independent type system, achieving decoupling between execution logic and engine.
Plugins can now be developed once and adapted to multiple engines, offering an optional solution for enterprises lacking a big data ecosystem or seeking an optimal data synchronization experience.
On this basis, Apache SeaTunnel achieves high throughput, low latency, and accuracy, with greatly improved performance.
Principles of Data Integration
The principles of data integration can be analyzed from the following aspects.
From Configuration to Execution: Task Scheduling and Execution Mechanism
SeaTunnel's task execution flow features strong controllability and fault tolerance.
- Overall process of data transfer:
- Retrieve task parameters from configuration files or Web interfaces;
- Parse Table Schema, Options, etc., from the Catalog using the parameters;
- Use SPI to start SeaTunnel connectors and inject Table information;
- Translate SeaTunnel connectors into engine-native connectors;
- Execute the task through Source → Transform → Sink.

- Execution flow of data transmission:
-
SourceCoordinatoris responsible for discovering splits and coordinatingSourceReader; -
SourceReaderperforms the actual data reading, passes the data toTransform, which then sends it toSinkWriter; -
SinkWriterwrites the data or pre-commits it, then sends the commit information toSinkCoordinator; -
SinkAggregatedCommittercoordinatesSinkWriterto perform final commit or trigger abort; -
SinkWritercompletes the final commit or aborts the operation.

This mechanism ensures transactional consistency, data reliability, and horizontal scalability during task execution.
Guaranteeing Concurrency Performance: Intelligent Sharding Strategy
In scenarios involving massive data volumes, the ability to execute tasks in parallel becomes critical.
SeaTunnel designs two efficient sharding algorithms for different types of data fields:
FixedChunkSplitter
FixedChunkSplitter uses a predefined method to generate data shards, featuring simplicity and clarity:
- Range determination
- Obtain min and max values of the partition column
- Calculate the overall range (range = max - min)
- Shard computation
- Based on the configured
numPartitions, compute step size (step = range / numPartitions) - Each shard range: [min + step * i, min + step * (i+1)), where i is the shard index
- Boundary handling
- Handle the last shard specially to ensure it includes the upper bound
- Address potential overflow issues
- NULL value handling
- Special handling for NULLs to ensure completeness

This method is suitable for scenarios with evenly distributed data and simple field types, dividing ranges based on fixed steps derived from the field min/max.
DynamicChunkSplitter
DynamicChunkSplitter uses an intelligent sharding algorithm, adapting to data distribution:
- Data distribution assessment
- Calculate distribution factor: (max - min + 1) / rowCount
- Determine whether data is evenly distributed based on configured thresholds
- Shard generation strategy
- For evenly distributed data: use dynamically calculated step sizes for sharding
-
For skewed data:
- If the row count is low, determine the shard boundaries via database queries
- If the row count is high, determine boundaries through sampling
- Special data type handling
- Date fields: adjust date range step sizes dynamically based on data volume
- String fields: use charset-based sharding

This approach dynamically defines boundaries through sampling and distribution evaluation,
suitable for skewed data or large tables.
Sharding Strategy Comparison
These two sharding strategies each have their advantages and disadvantages:
| Characteristic | Fixed Sharding | Dynamic Sharding |
|---|---|---|
| Algorithm Complexity | Low | High |
| Applicable Scenarios | Uniform data distribution | Various data distribution situations |
| Shard Uniformity | Possibly uneven | Highly uniform |
| Resource Consumption | Low | Relatively high (requires data sampling) |
- Data transmission sampling principle: In Apache SeaTunnel, data transmission sampling follows certain principles:
Sample one data point every
samplingRate, and sort the sample data points into an array.Calculate shard density
Calculate how many sample points each logical shard should contain:
Total sample points ÷ number of shards
Formula:
approxSamplePerShard = sampleData.length / shardCountDetermine shard boundaries based on shard density
- **Low-Density Mode** (fewer than 1 sample per shard): Each sample point independently forms a shard to avoid repeated boundary values and ensure unique shard boundaries.
Sharding pattern: `null → sample1, sample1 → sample2, sample2 → sample3, ..., sampleN → null`
- **Normal-Density Mode** (1 or more samples per shard): Distribute shards evenly based on the sample array.
Use `sampleData[i * approxSamplePerShard]` to determine boundaries.
The last shard's upper bound is set to `null` (indicating no upper limit). This prevents repeated boundary values across shards.
**Example**:
Sample data: `[10, 15, 22, 28, 35, 50, 65, 84, 92, 99]` (10 sample points)
Expected shards: 5, density = 2.6 samples per shard
* Shard 1 upper bound = sample[2] = 22
* Shard 2 upper bound = sample[5] = 58
* Shard 3 upper bound = sample[10.4 ≈ 10] = 84
* Shard 4 upper bound = sample[13 exceeds length] = null
**Shard results**:
null → 22, 22 → 58, 58 → 84, 84 → null
String Field Sharding
When dealing with evenly distributed string fields, traditional methods often rely on database-based progressive LIMIT queries or hash-modulo of field values.
However, LIMIT-based shard generation is highly inefficient for big data environments.
Hash-based methods, while fast, often hinder the use of indexes during actual data reading, degrading query performance.
To improve performance, SeaTunnel introduces a charset-based string sharding algorithm.
The core idea is: map strings to integer ranges based on charset order, apply numeric sharding, then convert back to strings.
This “charset encoding → numeric sharding → charset decoding” approach ensures both even sharding and efficient large-scale data processing.

The key to this algorithm lies in converting string fields into numeric forms suitable for computation, thus achieving efficient and even sharding.
The process includes:
First, using sorted SQL to obtain the charset order of the target field and calculate the charset size (charsetSize);
Then, encode the field’s min and max values into base-charsetSize numbers and convert them to decimal;
Next, apply standard numeric sharding on the decimal range to derive sub-ranges;
Finally, convert the decimal boundaries back into base-charsetSize numbers, and decode them into strings based on charset order, thus obtaining evenly divided string ranges.
This method effectively solves the traditional problems of poor precision and efficiency in string sharding.

Charset-based sharding is suitable for fields within the ASCII visible character range.
It requires that the selected sharding field be evenly distributed to maintain precision and improve concurrency.
Cloudberry Integration Practice: High-Efficiency Compatibility via JDBC Mode
Cloudberry is a PostgreSQL-compatible distributed database. SeaTunnel integrates with it seamlessly by extending the PostgreSQL plugin and using the JDBC driver.
The connector design follows an elegant reuse strategy, directly inheriting the core logic of the PostgreSQL connector, including connection management and data read/write mechanisms.
This design greatly reduces development costs,
allowing users to interact with Cloudberry just like with PostgreSQL.

Users only need to configure the following key parameters to achieve high-performance parallel data reads:
partition_column- Auto-sharding based on primary key or unique index
table_listfor multi-table readsUpper and lower boundary control to optimize concurrency


- Sharding configuration options
split.size: Controls the number of rows in each split, determining the granularity of table splitting.
split.even-distribution.factor.lower-bound: Lower bound factor for data distribution uniformity (0.05)
split.even-distribution.factor.upper-bound: Upper bound factor for data distribution uniformity (100.0)
split.sample-sharding.threshold: Threshold for triggering the sampling sharding strategy (1000)
split.inverse-sampling.rate: Inverse of the sampling rate, controls sampling granularity (1000)
partition_column: Name of the column used for data partitioning
partition_upper_bound: Maximum value of the partition column to be scanned
partition_lower_bound: Minimum value of the partition column to be scanned
partition_num: Number of partitions (not recommended; it's suggested to use split.size instead)

- Simple example

-
Parallel reading via
partition_columnRead table data in parallel using the configured sharding column. If you want to read the entire table, you can do so this way.

-
Parallel reading via primary key or unique index
Configure
table_pathto enable auto-sharding. You can configuresplit.*to adjust the sharding strategy.

- Parallel boundaries Reading data sources with configured upper and lower limits is more efficient.

-
Multi-table reading
Configure
table_listto enable auto-sharding. You can configuresplit.*to adjust the sharding strategy.

Looking Ahead: Connector Design Based on gpfdist
The currently implemented Cloudberry connector in SeaTunnel is built on JDBC, which, although fully functional, faces performance bottlenecks in large-scale data transmission scenarios.
To better support large-scale data synchronization tasks, SeaTunnel is building the next-generation high-performance connector based on the gpfdist protocol and external table mechanism:
- For data reads: SeaTunnel will create a writable external table in Cloudberry to extract data efficiently.
- For data writes: SeaTunnel will create a readable external table in Cloudberry to achieve high-performance data loading.
This connector will leverage Cloudberry’s parallel computing capabilities, offering ultra-fast transmission in both pull and push modes—especially suitable for TB/PB-scale data scenarios.
Conclusion
Apache SeaTunnel is demonstrating strong momentum in the data integration field with its modular architecture, flexible plugin ecosystem, and powerful execution capabilities. Its deep integration with Cloudberry further validates its compatibility and practicality across heterogeneous systems.
With ongoing architectural evolution and new connector implementations, Apache SeaTunnel is poised to become a core component of intelligent data platforms for enterprises.







