



















_ElenaBs_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






















![Bitten By Bed Bugs At Luxor—Rushed To Hospital, All They Did Was Waive Her Resort Fee. Now She’s Suing [Roundup]](https://viewfromthewing.com/wp-content/uploads/2025/05/luxor.jpg?#)




















Vision Language models: towards multi-modal deep learning
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL
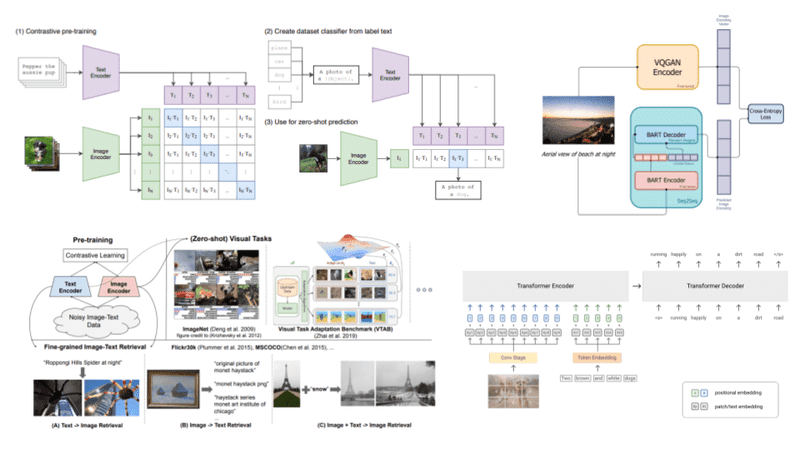
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL







