
































































Self-hosting LLMs for Production Systems: Solving the Model Quality Challenge
In our previous post on semantic caching, we explored how orra's Plan Engine intelligently reuses execution plans to reduce costs and improve performance. Today, we're diving into another powerful capability that enhances orra's flexibility and control for production deployments: self-hosted model support. The ability to run with self-hosted models addresses several critical needs we've heard from orra users building production multi-agent applications: Data privacy and security: Keeping sensitive information within your infrastructure Cost predictability: Trading API costs for infrastructure costs with more predictable scaling Deployment flexibility: Supporting air-gapped environments and custom setups Performance tuning: Optimizing for specific workloads and hardware configurations We'll explore how orra's Plan Engine interfaces with self-hosted models, the architectural decisions that make this possible, and provide practical examples for setting up your own self-hosted model infrastructure for orra. The Challenge: Bridging Orchestration with Self-hosted Models When we first designed orra's Plan Engine, we optimized for powerful orchestration capabilities using LLMs with strong reasoning abilities. As our user base grew, we encountered a critical challenge: How can we address users' data privacy concerns without sacrificing the reliable execution plan generation that's central to orra's orchestration capabilities? Our early testing revealed a daunting reality: most open-source models struggled significantly with the complex reasoning required to generate valid execution plans. The only open-source model that consistently matched cloud API performance was DeepSeek-R1 — a massive model requiring substantial hardware resources to host and run. This created a difficult dilemma: Continue relying on cloud provider APIs (reliable but with data privacy concerns) Recommend DeepSeek-R1 self-hosting (effective but requiring expensive infrastructure and operational complexity) Support other open-source models (addressing privacy but potentially sacrificing orchestration reliability) As one user summarized it during our testing: "Is self-hosting DeepSeek-R1 really worth our time? We need data privacy, but not at the cost of months of infrastructure work." Through extensive experimentation, we discovered that a newer generation of models like Qwen/QwQ-32B could deliver reliable execution plan generation with the right guidance and validation checks. This opened the door to truly practical self-hosting options that didn't require the most expensive hardware setups. In the end we decided to support both Qwen/QwQ-32B and DeepSeek-R1 for self-hosted setups. The Solution: Universal Interfaces, Robust Validation and retries Our solution to reliable self-hosted orchestration involves two key elements: a universal interface standard and robust validation to ensure execution plan quality across models. OpenAI-compatible API: The Universal Interface The first part of our solution leverages the OpenAI-compatible API as a universal interface standard. This choice was strategic rather than just convenient: // From planengine/llm.go func (l *LLMClient) Generate(ctx context.Context, prompt string) (response string, err error) { l.logger.Trace(). Str("Prompt", prompt). Msg("Generating using prompt") request := open.ChatCompletionRequest{ Model: l.llmModel, Messages: []open.ChatCompletionMessage{ { Role: open.ChatMessageRoleUser, Content: prompt, }, }, Temperature: getModelTemperature(l.llmModel), } resp, err := l.llmClient.CreateChatCompletion(ctx, request) if err != nil { if strings.Contains(err.Error(), "401") || strings.Contains(err.Error(), "authentication") { return "", fmt.Errorf("authentication failed: API key may be required or invalid for this endpoint: %w", err) } return "", fmt.Errorf("LLM completion failed: %w", err) } // Process response... return resp.Choices[0].Message.Content, nil } This approach brought several critical benefits: Ecosystem Compatibility: Most modern model serving solutions (vLLM, TGI, Ollama) now support this standardized interface Deployment Flexibility: Organizations can switch between hosted and self-hosted options as their needs evolve Future Proofing: As new models emerge, they can be integrated without architecture changes Ensuring Reliable Execution Plans Across Models The bigger challenge was ensuring that self-hosted models could reliably generate correct execution plans. We discovered that even capable models like Qwen/QwQ-32B required additional guidance and validation compared to cloud APIs. This led us to implement a validation system with progressive retry logic and detailed feedback: func (p *PlanEngine) attemptRetryablePreparation( ctx context.Context, ......) error { // Generate execution plan with pot
In our previous post on semantic caching, we explored how orra's Plan Engine intelligently reuses execution plans to reduce costs and improve performance. Today, we're diving into another powerful capability that enhances orra's flexibility and control for production deployments: self-hosted model support.
The ability to run with self-hosted models addresses several critical needs we've heard from orra users building production multi-agent applications:
Data privacy and security: Keeping sensitive information within your infrastructure
Cost predictability: Trading API costs for infrastructure costs with more predictable scaling
Deployment flexibility: Supporting air-gapped environments and custom setups
Performance tuning: Optimizing for specific workloads and hardware configurations
We'll explore how orra's Plan Engine interfaces with self-hosted models, the architectural decisions that make this possible, and provide practical examples for setting up your own self-hosted model infrastructure for orra.
The Challenge: Bridging Orchestration with Self-hosted Models
When we first designed orra's Plan Engine, we optimized for powerful orchestration capabilities using LLMs with strong reasoning abilities. As our user base grew, we encountered a critical challenge:
How can we address users' data privacy concerns without sacrificing the reliable execution plan generation that's central to orra's orchestration capabilities?
Our early testing revealed a daunting reality: most open-source models struggled significantly with the complex reasoning required to generate valid execution plans. The only open-source model that consistently matched cloud API performance was DeepSeek-R1 — a massive model requiring substantial hardware resources to host and run.
This created a difficult dilemma:
Continue relying on cloud provider APIs (reliable but with data privacy concerns)
Recommend DeepSeek-R1 self-hosting (effective but requiring expensive infrastructure and operational complexity)
Support other open-source models (addressing privacy but potentially sacrificing orchestration reliability)
As one user summarized it during our testing: "Is self-hosting DeepSeek-R1 really worth our time? We need data privacy, but not at the cost of months of infrastructure work."
Through extensive experimentation, we discovered that a newer generation of models like Qwen/QwQ-32B could deliver reliable execution plan generation with the right guidance and validation checks. This opened the door to truly practical self-hosting options that didn't require the most expensive hardware setups.
In the end we decided to support both Qwen/QwQ-32B and DeepSeek-R1 for self-hosted setups.
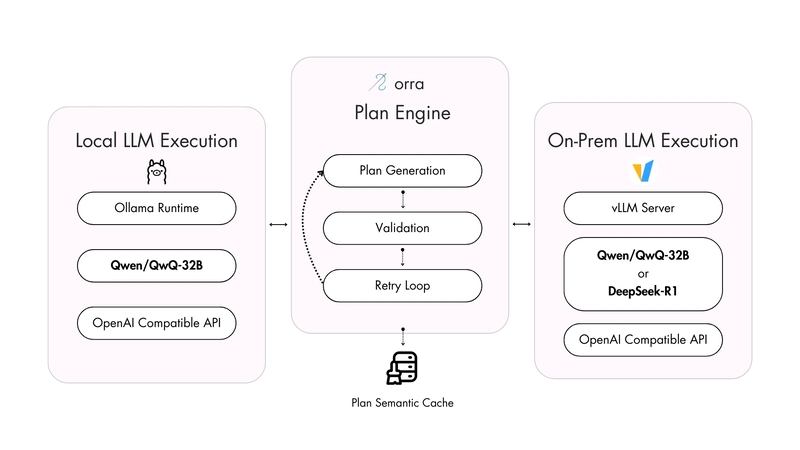
The Solution: Universal Interfaces, Robust Validation and retries
Our solution to reliable self-hosted orchestration involves two key elements: a universal interface standard and robust validation to ensure execution plan quality across models.
OpenAI-compatible API: The Universal Interface
The first part of our solution leverages the OpenAI-compatible API as a universal interface standard. This choice was strategic rather than just convenient:
// From planengine/llm.go
func (l *LLMClient) Generate(ctx context.Context, prompt string) (response string, err error) {
l.logger.Trace().
Str("Prompt", prompt).
Msg("Generating using prompt")
request := open.ChatCompletionRequest{
Model: l.llmModel,
Messages: []open.ChatCompletionMessage{
{
Role: open.ChatMessageRoleUser,
Content: prompt,
},
},
Temperature: getModelTemperature(l.llmModel),
}
resp, err := l.llmClient.CreateChatCompletion(ctx, request)
if err != nil {
if strings.Contains(err.Error(), "401") || strings.Contains(err.Error(), "authentication") {
return "", fmt.Errorf("authentication failed: API key may be required or invalid for this endpoint: %w", err)
}
return "", fmt.Errorf("LLM completion failed: %w", err)
}
// Process response...
return resp.Choices[0].Message.Content, nil
}
This approach brought several critical benefits:
Ecosystem Compatibility: Most modern model serving solutions (vLLM, TGI, Ollama) now support this standardized interface
Deployment Flexibility: Organizations can switch between hosted and self-hosted options as their needs evolve
Future Proofing: As new models emerge, they can be integrated without architecture changes
Ensuring Reliable Execution Plans Across Models
The bigger challenge was ensuring that self-hosted models could reliably generate correct execution plans. We discovered that even capable models like Qwen/QwQ-32B required additional guidance and validation compared to cloud APIs.
This led us to implement a validation system with progressive retry logic and detailed feedback:
func (p *PlanEngine) attemptRetryablePreparation(
ctx context.Context,
......) error {
// Generate execution plan with potential feedback from previous attempts
callingPlan, cachedEntryID, isCacheHit, err := p.decomposeAction(
ctx,
orchestration,
orchestration.Action.Content,
actionParams,
serviceDescriptions,
retryCauseIfAny,
)
// Various validation stages...
// Validate action parameters are properly included in TaskZero
if status, err := p.validateTaskZeroParams(callingPlan, actionParams, retryCount); err != nil {
p.VectorCache.Remove(orchestration.ProjectID, cachedEntryID)
return PreparationError{
Status: status,
Err: fmt.Errorf("execution plan action parameters validation failed: %w", err),
}
}
// Validate no composite references to task0 which indicates poor reasoning
if status, err := p.validateNoCompositeTaskZeroRefs(callingPlan, retryCount); err != nil {
p.VectorCache.Remove(orchestration.ProjectID, cachedEntryID)
return PreparationError{
Status: status,
Err: fmt.Errorf("execution plan contains invalid composite task0 references: %w", err),
}
}
// More validation steps...
}
This strategy to prompt engineering and validation feedback worked in our favour. When a model fails to generate a valid execution plan, instead of simply rejecting it, we:
Analyze exactly what went wrong (missing parameters, invalid references, etc.)
Provide specific guidance back to the model explaining the issue
Allow the model to retry with this additional context
For example, when parameters aren't properly incorporated into the execution plan, our validateTaskZeroParams method generates precise error messages that become feedback for the next attempt:
Validation Errors:
- Task0 input field 'order_id' doesn't match any action parameter
- Action parameter 'orderId' is missing from Task0 input
This feedback loop significantly improved success rates with models like Qwen/QwQ-32B, making self-hosted orchestration practical without requiring massive models like DeepSeek-R1.
Developer Root Cause Analysis Feedback
Going further, instead of just reporting validation failures with generic errors, we built specific diagnostics that help developers understand the issues they're encountering. Sometimes the model is trying too hard to do the right thing - but essentially this is a
developer error.
Let review an example of this might and how we implemented solution to handle it.
Here's a badly generated plan, which after consecutive retries could not be fixed:
{
"tasks": [
{
"id": "task0",
"input": {
"query": "I need a used laptop for college that is powerful enough for programming",
"budget": "800",
"category": "laptop"
}
},
{
"id": "task1",
"service": "s_aodlipsfcgzmnirkyhyrlmdavwag",
"input": {
"query": "$task0.query budget: $task0.budget category: $task0.category"
}
}
],
"parallel_groups": [
[
"task1"
]
]
}
The budget and category are extra action parameters that the model is trying to do the right thing by. It doesn't ignore them, instead its injecting them into odd contexts inside task1.input.query creating an invalid input entry.
Larger reasoning models handle this elegantly but smaller ones not so much.
But, actually this is a developer error, budget and category are extra action parameters not required by this job.
The Plan Engine knows this because the service selected to complete the work does not require the params as input. So the final rejection error flags this:
// Final execution plan comprehensive error with root cause analysis
// ORCHESTRATION ERROR: Found invalid task0 references in downstream tasks.
// PROBLEM: The generated execution plan has parameters with invalid task0 references.
// Each input parameter should reference exactly one task0 field without additional text.
// ...
// ...
// HOW TO FIX:
// 1. If required, update each task's service's input schema to accept these parameters
// 2. OR if these parameters aren't needed, remove them from your orchestration request
This approach to error handling and retry logic is what makes reliable self-hosted orchestration possible with models like Qwen/QwQ-32B. You get data privacy without giving up reliable orchestration.
Semantic Caching Impact
The Plan Engine's semantic caching becomes even more valuable with self-hosted models by:
Reducing computational load on your infrastructure
Minimizing memory pressure on GPU resources
Increasing throughput capacity for concurrent users
Providing consistent performance regardless of model location
Future Directions
The addition of self-hosted model support opens up several exciting possibilities for orra:
1. Local Streaming Capabilities
We're working on streaming support for self-hosted models, which will enable real-time feedback during long-running orchestrations without increased API costs.
2. Custom Model Fine-tuning
With self-hosted models, organisations can potentially fine-tune models for specific domains and tasks, creating specialised orchestration engines for their particular use cases.
3. Hardware-specific Optimizations
As orra evolves, we'll provide more guidance on optimizing deployments for specific hardware configurations, including Apple Silicon, AMD GPUs, and specialized AI accelerators.
Conclusion: Flexibility Without Compromise
The addition of self-hosted model support represents a significant milestone in our evolution as a production-ready orchestration platform. By supporting both cloud APIs and self-hosted models through a consistent interface, we've created a system that offers flexibility without compromising on capability or developer experience.
Be sure to check out orra if you want to build production-ready multi-agent applications that handle complex real-world interactions.
For more information on setting up self-hosted models, check out our documentation on model configuration.









