























































.jpg)
















Google apresenta TPU Ironwood, sua 1ª primeira focada em inferência de IA
O Google anunciou nesta quarta-feira (9), durante o Google Cloud Next 2025, sua nova geração de TPUs batizada de Ironwood. Trata-se da primeira unidade de processamento de tensores da companhia projetada especificamente para workloads de inferência de IA, representando a sétima geração da tecnologia e prometendo ser a mais potente, eficiente e escalável até o momento. Qualcomm e IBM anunciam parceria para levar IA para a "borda"; entenda Vale a pena pagar por uma IA? Entenda os benefícios de assinar um chatbot A chegada da Ironwood marca uma mudança na estratégia do Google para infraestrutura de IA, sinalizando a transição para o que a empresa está chamando de "era da inferência". Enquanto as gerações anteriores de TPUs foram desenvolvidas principalmente para treinamento e implementação de modelos de inteligência artifical, a nova solução foi arquitetada do zero com foco especial no processo de inferência — quando os modelos de IA já treinados são efetivamente colocados em uso para gerar respostas, insights e análises. Especificações impressionantes para demandas crescentes A TPU Ironwood apresenta um salto significativo nas especificações técnicas em relação à sua antecessora, a Trillium. Cada chip individual oferece impressionantes 4.614 teraflops de capacidade computacional de pico, com memória HBM (High Bandwidth Memory) de 192 GB por chip — seis vezes maior que a geração anterior. -Entre no Canal do WhatsApp do Canaltech e fique por dentro das últimas notícias sobre tecnologia, lançamentos, dicas e tutoriais incríveis.- O componente também traz melhorias substanciais em largura de banda, alcançando 7,2 Tbps por chip, 4,5 vezes superior à Trillium. A conexão entre chips (Inter-Chip Interconnect) também foi aprimorada, com largura de banda bidirecional de 1,2 Tbps — um aumento intergeração de 50%. A Ironwood conta ainda com um SparseCore aprimorado, acelerador especializado para processamento de embeddings ultragrandes comuns em cargas de trabalho avançadas de classificação e recomendação. Isso permite que a TPU expanda seu alcance para além dos domínios tradicionais de IA, conseguindo abranger aplicações financeiras e científicas. Para os clientes do Google Cloud, a Ironwood será disponibilizada em duas configurações: pods com 256 chips ou pods com 9.216 chips. Na configuração máxima, a TPU entrega impressionantes 42,5 exaflops de poder computacional — mais de 24 vezes a capacidade do El Capitan, considerado o maior supercomputador do mundo com seus 1,7 exaflops. Incremento do pico de desempenho por watt em FP8 em relação ao v2, primeiro TPU do Google, chega a ser de 3600% (Imagem: Divulgação/Google) Foco estratégico na inferência de IA A decisão do Google de criar uma TPU focada em inferência não é ao acaso. Ao anunciá-la, a empresa explicou que estamos entrando na "era da inferência", onde modelos de IA não apenas fornecem informações em tempo real para serem interpretadas por pessoas, mas proativamente geram insights e interpretações. "É uma mudança de modelos de IA responsivos que fornecem informações em tempo real para serem interpretadas por pessoas, para modelos que proporcionam a geração proativa de insights e interpretação", explicou Amin Vahdat, VP e GM de ML, Sistemas e Cloud AI do Google, durante o anúncio. Essa mudança de paradigma exige infraestrutura especialmente projetada para lidar com "modelos pensantes" — como Grandes Modelos de Linguagem (LLMs), Mixture of Experts (MoEs) e tarefas avançadas de raciocínio que demandam processamento paralelo massivo e acesso eficiente à memória. Por que focar em inferência agora? O foco do Google na inferência reflete um momento de inflexão na evolução da IA. Com o aumento da complexidade dos modelos e a expansão das janelas de contexto, o custo computacional está cada vez mais concentrado no momento da inferência, não apenas no treinamento. À medida que as aplicações de IA se tornam mais sofisticadas — realizando raciocínios em múltiplas etapas e processando contextos mais longos e variáveis —, a eficiência no processamento de inferência torna-se estrategicamente mais importante que a velocidade de treinamento. O Google parece ter percebido isso antes da concorrência. Enquanto a maioria do mercado ainda se concentra predominantemente na aceleração do treinamento de modelos cada vez maiores, Mountain View antecipa uma mudança: o verdadeiro gargalo será colocar esses modelos em produção de maneira eficiente e econômica. A Ironwood chega para resolver exatamente esse problema. Ganho de performance por watt medido em TDP mostra eficiência quase 30x maior em relação ao TPU v2, de 2008 (Imagem: Divulgação/Google) Impacto nos serviços de cloud e ecossistema de IA do Google A Ironwood já estreia como um componente fundamental na estratégia mais ampla do Google Cloud para IA. Integrada à arquitetura AI Hypercomputer, o novo componente permitirá à empresa oferecer serviços mais inteligentes e eficientes através de toda s


O Google anunciou nesta quarta-feira (9), durante o Google Cloud Next 2025, sua nova geração de TPUs batizada de Ironwood. Trata-se da primeira unidade de processamento de tensores da companhia projetada especificamente para workloads de inferência de IA, representando a sétima geração da tecnologia e prometendo ser a mais potente, eficiente e escalável até o momento.
- Qualcomm e IBM anunciam parceria para levar IA para a "borda"; entenda
- Vale a pena pagar por uma IA? Entenda os benefícios de assinar um chatbot
A chegada da Ironwood marca uma mudança na estratégia do Google para infraestrutura de IA, sinalizando a transição para o que a empresa está chamando de "era da inferência". Enquanto as gerações anteriores de TPUs foram desenvolvidas principalmente para treinamento e implementação de modelos de inteligência artifical, a nova solução foi arquitetada do zero com foco especial no processo de inferência — quando os modelos de IA já treinados são efetivamente colocados em uso para gerar respostas, insights e análises.
Especificações impressionantes para demandas crescentes
A TPU Ironwood apresenta um salto significativo nas especificações técnicas em relação à sua antecessora, a Trillium. Cada chip individual oferece impressionantes 4.614 teraflops de capacidade computacional de pico, com memória HBM (High Bandwidth Memory) de 192 GB por chip — seis vezes maior que a geração anterior.
-
Entre no Canal do WhatsApp do Canaltech e fique por dentro das últimas notícias sobre tecnologia, lançamentos, dicas e tutoriais incríveis.
-
O componente também traz melhorias substanciais em largura de banda, alcançando 7,2 Tbps por chip, 4,5 vezes superior à Trillium. A conexão entre chips (Inter-Chip Interconnect) também foi aprimorada, com largura de banda bidirecional de 1,2 Tbps — um aumento intergeração de 50%.
A Ironwood conta ainda com um SparseCore aprimorado, acelerador especializado para processamento de embeddings ultragrandes comuns em cargas de trabalho avançadas de classificação e recomendação. Isso permite que a TPU expanda seu alcance para além dos domínios tradicionais de IA, conseguindo abranger aplicações financeiras e científicas.
Para os clientes do Google Cloud, a Ironwood será disponibilizada em duas configurações: pods com 256 chips ou pods com 9.216 chips. Na configuração máxima, a TPU entrega impressionantes 42,5 exaflops de poder computacional — mais de 24 vezes a capacidade do El Capitan, considerado o maior supercomputador do mundo com seus 1,7 exaflops. 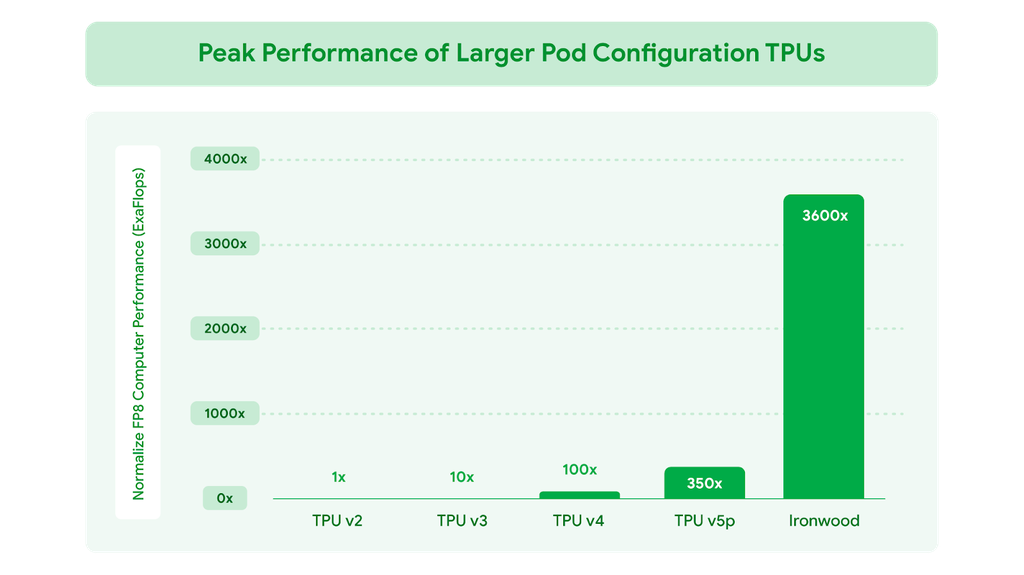
Foco estratégico na inferência de IA
A decisão do Google de criar uma TPU focada em inferência não é ao acaso. Ao anunciá-la, a empresa explicou que estamos entrando na "era da inferência", onde modelos de IA não apenas fornecem informações em tempo real para serem interpretadas por pessoas, mas proativamente geram insights e interpretações.
"É uma mudança de modelos de IA responsivos que fornecem informações em tempo real para serem interpretadas por pessoas, para modelos que proporcionam a geração proativa de insights e interpretação", explicou Amin Vahdat, VP e GM de ML, Sistemas e Cloud AI do Google, durante o anúncio.
Essa mudança de paradigma exige infraestrutura especialmente projetada para lidar com "modelos pensantes" — como Grandes Modelos de Linguagem (LLMs), Mixture of Experts (MoEs) e tarefas avançadas de raciocínio que demandam processamento paralelo massivo e acesso eficiente à memória.
Por que focar em inferência agora?
O foco do Google na inferência reflete um momento de inflexão na evolução da IA. Com o aumento da complexidade dos modelos e a expansão das janelas de contexto, o custo computacional está cada vez mais concentrado no momento da inferência, não apenas no treinamento.
À medida que as aplicações de IA se tornam mais sofisticadas — realizando raciocínios em múltiplas etapas e processando contextos mais longos e variáveis —, a eficiência no processamento de inferência torna-se estrategicamente mais importante que a velocidade de treinamento. O Google parece ter percebido isso antes da concorrência.
Enquanto a maioria do mercado ainda se concentra predominantemente na aceleração do treinamento de modelos cada vez maiores, Mountain View antecipa uma mudança: o verdadeiro gargalo será colocar esses modelos em produção de maneira eficiente e econômica. A Ironwood chega para resolver exatamente esse problema. 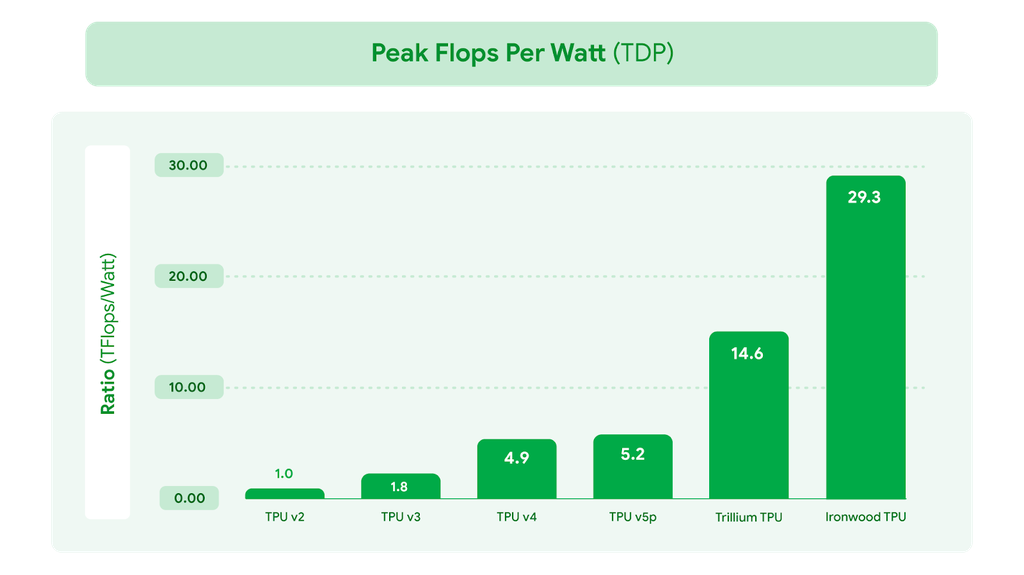
Impacto nos serviços de cloud e ecossistema de IA do Google
A Ironwood já estreia como um componente fundamental na estratégia mais ampla do Google Cloud para IA. Integrada à arquitetura AI Hypercomputer, o novo componente permitirá à empresa oferecer serviços mais inteligentes e eficientes através de toda sua plataforma de nuvem.
Um dos principais benefícios destacados pela companhia é a eficiência energética, que oferece performance por watt duas vezes superior à Trillium. Em um momento em que a disponibilidade energética é uma das principais restrições para a expansão da infraestrutura de IA, esta TPU promete entregar significativamente mais capacidade por watt para cargas de trabalho dos clientes.
O sistema de refrigeração líquida avançada e o design otimizado do chip podem sustentar de forma confiável até o dobro do desempenho da refrigeração a ar padrão, mesmo sob cargas de trabalho pesadas e contínuas. De acordo com o Google, a Ironwood é quase 30 vezes mais eficiente em termos energéticos do que sua primeira TPU em nuvem, lançada em 2018.
Para os desenvolvedores, as vantagens incluem mais poder computacional e um ecossistema de software otimizado. Com o runtime Pathways disponível pela primeira vez no Google Cloud, os usuários poderão aproveitar recursos como inferência desagregada, permitindo o escalonamento dinâmico das etapas de "prefill" e "decode" dos workloads de inferência em unidades de computação separadas, cada uma escalando de forma independente para fornecer latência ultrabaixa e alto throughput.
Os modelos mais avançados do Google, como o Gemini 2.5 e o AlphaFold (premiado com o Nobel), já são executados em TPUs hoje; com a Ironwood, a expectativa é que novos avanços significativos em IA sejam impulsionados tanto pelos próprios desenvolvedores do Google quanto pelos clientes do Google Cloud. 
Disponibilidade ainda para 2025
Embora o Google não tenha divulgado uma data exata, confirmou que a Ironwood estará disponível para clientes do Google Cloud ainda em 2025. O componente será integrado à arquitetura AI Hypercomputer do serviço de nuvem, otimizada para as cargas de trabalho de IA mais exigentes.
Vale destacar que a nova TPU será acessível através de frameworks populares como PyTorch e JAX, e os desenvolvedores poderão utilizar o sistema de runtime Pathways, desenvolvido pelo Google DeepMind, para distribuir eficientemente o processamento entre múltiplos chips.
Leia mais no Canaltech:
- O que é aprendizado de máquina?
- Ex-CEO da Intel critica preço de GPUs da NVIDIA para IA: "tiveram sorte"
- 8 cursos gratuitos do Google sobre IA generativa
Leia a matéria no Canaltech.
