IOT: Debugging InfluxDB Storage Errors
Over the course of the last articles, I introduced InfluxDB and showed how to store system and application log files coming from FluentBit inside InfluxDB. About two weeks later, the InfluxDB container would suddenly not start any more. The root cause was insufficient memory during compaction of large databases containing the log files. This troubleshoot article describe my approach to identify, understand and resolve this particular error. Follow along to learn more about InfluxDB, or head to the conclusion, read about the solution in a nutshell, and skim the sections that detail the solution steps. The technical context of this article is Raspberry Pi OS 2024-11-19 and InfluxDB v1.8.10. This article originally appeared at my blog admantium.com InfluxDB Error Messages When trying to start the container, I could see several error messages. Around 04:08:54, a compaction for the logfile database started. ts=2024-11-16T04:08:54.590589Z lvl=info msg="TSM compaction (start)" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 op_event=start ts=2024-11-16T04:08:54.590656Z lvl=info msg="Beginning compaction" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_files_n=8 ts=2024-11-16T04:08:54.591006Z lvl=info msg="Compacting file" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_index=7 tsm1_file=/var/lib/influxdb/data/fluent/autogen/964/000000073-000000001.tsm runtime: out of memory: cannot allocate 17547264-byte block (1625686016 in use) fatal error: out of memory runtime stack: runtime.throw(0xfebdde, 0xd) /usr/local/go/src/runtime/panic.go:774 +0x5c So, there is some process that compacts the stored logfiles. Interestingly, just some moments ago, at 04:07:57 the very same file could be compacted successfully: ts=2024-11-16T04:07:57.591439Z lvl=info msg="Compacting file" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzLFaW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_index=7 tsm1_file=/var/lib/influxdb/data/fluent/autogen/964/000000073-000000001.tsm ts=2024-11-16T04:08:54.349673Z lvl=info msg="TSM compaction (end)" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzLFaW000 op_name=tsm1_compact_group db_shard_id=964 op_event=end op_elapsed=56759.149ms Looking at other log messages occurring around this time, I noticed that the HTTP endpoint of InfluxDB received and processed several messages too: [httpd] 172.18.0.11 - telegraf [16/Nov/2024:04:09:08 +0000] "POST /write?consistency=any&db=telegraf HTTP/1.1 " 204 0 "-" "telegraf" 5148c005-b58b-11ed-8139-0242ac120007 99282 ts=2024-11-16T04:09:13.605706Z lvl=warn msg="max-values-per-tag limit may be exceeded soon" log_id=0gEyQZ1W000 service=store perc=98% n=98482 max=100000 db_instance=fluent measurement=nexus tag=_seq Overall, my first impression was that InfluxDB tries to compact the same file several times, almost without pause, while still receiving and processing new data that should be stored. Then the container runs out of memory, restarts the same procedure, retries compactions, and fails again. But which memory is meant? Hard drive or RAM? Available on the machine, allocated for the Docker daemon, or allocated specifically for the Docker container of InfluxDB? Questions are plenty, lets dig into it. Understanding the Error Finding well-versed search engine queries to understand application errors is essential. My very first query was InfluxDB out of memory during compaction and lead me to an issue in influxdata that points exactly to InfluxDB running as a Docker container on a Raspberry Pi 4! The proposed solution starts with this message: Yes, this is an InfluxDB ARM 32bit bug. Influx insists on mapping the whole database into memory, which fails if the database size is larger than the addressable memory size [...] I could not believe how relevant this is - that’s exactly the error I was having! The issue also details the solution: Applying a specific patch to the InfluxDB binary that fixes the memory error. Caveat for me: My IOT stack is based on external Docker images, so applying a patch would require to manually build the container or to map the binaries that the patch produces inside the container. Let’s try this. Build Patched Binaries To build the patched InfluxDB binary, we need to install the most recent Go compiler first. To get the most up to date version, download the binary directly from the official homepage, unzip, then copy the binary to a folder that is part of your $PATH environment variable. curl -L -o go1.20.1.linux-armv6l.tar.gz https://go.dev/dl/go1.20.1.linux-armv6l.tar.gz sudo rm -rf /usr/local/go && sudo tar -C /usr/local -xzf go1
Over the course of the last articles, I introduced InfluxDB and showed how to store system and application log files coming from FluentBit inside InfluxDB. About two weeks later, the InfluxDB container would suddenly not start any more. The root cause was insufficient memory during compaction of large databases containing the log files.
This troubleshoot article describe my approach to identify, understand and resolve this particular error. Follow along to learn more about InfluxDB, or head to the conclusion, read about the solution in a nutshell, and skim the sections that detail the solution steps.
The technical context of this article is Raspberry Pi OS 2024-11-19 and InfluxDB v1.8.10.
This article originally appeared at my blog admantium.com
InfluxDB Error Messages
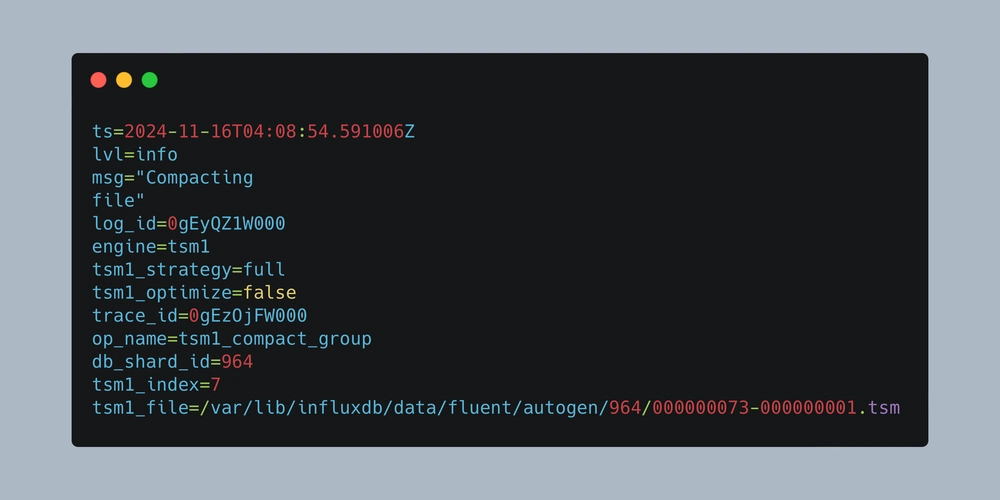
When trying to start the container, I could see several error messages. Around 04:08:54, a compaction for the logfile database started.
ts=2024-11-16T04:08:54.590589Z lvl=info msg="TSM compaction (start)" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 op_event=start
ts=2024-11-16T04:08:54.590656Z lvl=info msg="Beginning compaction" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_files_n=8
ts=2024-11-16T04:08:54.591006Z lvl=info msg="Compacting file" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzOjFW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_index=7 tsm1_file=/var/lib/influxdb/data/fluent/autogen/964/000000073-000000001.tsm
runtime: out of memory: cannot allocate 17547264-byte block (1625686016 in use)
fatal error: out of memory
runtime stack:
runtime.throw(0xfebdde, 0xd)
/usr/local/go/src/runtime/panic.go:774 +0x5c
So, there is some process that compacts the stored logfiles. Interestingly, just some moments ago, at 04:07:57 the very same file could be compacted successfully:
ts=2024-11-16T04:07:57.591439Z lvl=info msg="Compacting file" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzLFaW000 op_name=tsm1_compact_group db_shard_id=964 tsm1_index=7 tsm1_file=/var/lib/influxdb/data/fluent/autogen/964/000000073-000000001.tsm
ts=2024-11-16T04:08:54.349673Z lvl=info msg="TSM compaction (end)" log_id=0gEyQZ1W000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gEzLFaW000 op_name=tsm1_compact_group db_shard_id=964 op_event=end op_elapsed=56759.149ms
Looking at other log messages occurring around this time, I noticed that the HTTP endpoint of InfluxDB received and processed several messages too:
[httpd] 172.18.0.11 - telegraf [16/Nov/2024:04:09:08 +0000] "POST /write?consistency=any&db=telegraf HTTP/1.1 " 204 0 "-" "telegraf" 5148c005-b58b-11ed-8139-0242ac120007 99282
ts=2024-11-16T04:09:13.605706Z lvl=warn msg="max-values-per-tag limit may be exceeded soon" log_id=0gEyQZ1W000 service=store perc=98% n=98482 max=100000 db_instance=fluent measurement=nexus tag=_seq
Overall, my first impression was that InfluxDB tries to compact the same file several times, almost without pause, while still receiving and processing new data that should be stored. Then the container runs out of memory, restarts the same procedure, retries compactions, and fails again. But which memory is meant? Hard drive or RAM? Available on the machine, allocated for the Docker daemon, or allocated specifically for the Docker container of InfluxDB? Questions are plenty, lets dig into it.
Understanding the Error
Finding well-versed search engine queries to understand application errors is essential. My very first query was InfluxDB out of memory during compaction and lead me to an issue in influxdata that points exactly to InfluxDB running as a Docker container on a Raspberry Pi 4! The proposed solution starts with this message:
Yes, this is an InfluxDB ARM 32bit bug. Influx insists on mapping the whole database into memory, which fails if the database size is larger than the addressable memory size [...]
I could not believe how relevant this is - that’s exactly the error I was having! The issue also details the solution: Applying a specific patch to the InfluxDB binary that fixes the memory error. Caveat for me: My IOT stack is based on external Docker images, so applying a patch would require to manually build the container or to map the binaries that the patch produces inside the container. Let’s try this.
Build Patched Binaries
To build the patched InfluxDB binary, we need to install the most recent Go compiler first. To get the most up to date version, download the binary directly from the official homepage, unzip, then copy the binary to a folder that is part of your $PATH environment variable.
curl -L -o go1.20.1.linux-armv6l.tar.gz https://go.dev/dl/go1.20.1.linux-armv6l.tar.gz
sudo rm -rf /usr/local/go && sudo tar -C /usr/local -xzf go1.20.1.linux-armv6l.tar.gz
Then test that the installation is successfull:
go version
go version go1.20.1 linux/arm
The next step is to clone the InfluxDB GitHub repository, checkout a specific branch, and build the binaries. These steps are taken from a description in this GitHub issue:
git clone https://github.com/simonvetter/influxdb.git
cd influxdb && git checkout origin/1.8.10+big_db_32bit
mkdir build
export GOARCH=arm
go build -o build/influx_stress cmd/influx_stress/*.go
go build -o build/influx_tools cmd/influx_tools/*.go
go build -o build/influx_inspect cmd/influx_inspect/*.go
go build -o build/influxd cmd/influxd/main.go
go build -o build/influx cmd/influx/main.go
The installation can take some time because several libraries need to be downloaded. Here is an excerpt from the installation log:
go build -o build/influx_tools cmd/influx_tools/*.go
go: downloading go.uber.org/zap v1.9.1
go: downloading github.com/influxdata/usage-client v0.0.0-20160829180054-6d3895376368
go: downloading golang.org/x/text v0.3.3
go: downloading golang.org/x/crypto v0.0.0-20210322153248-0c34fe9e7dc2
go: downloading github.com/jsternberg/zap-logfmt v1.0.0
go: downloading github.com/mattn/go-isatty v0.0.4
go: downloading golang.org/x/time v0.0.0-20190308202827-9d24e82272b4
When the build is finished, following binaries are produced:
ls build/
influx influx_inspect influx_stress influx_tools influxd
Map Binaries inside the Docker container
Now I need to figure out how these binaries are included in the default InfluxDB Docker image and replace them. Let’s start a container and explore it.
docker run -it influxdb:1.8.10 bash
root@c497f1bf2f6e:/# which influx
/usr/bin/influx
root@c497f1bf2f6e:/# which influxd
/usr/bin/influxd
Ok, all binaries are residing in /usr/bin. This leads to the following modified docker-compose.yml:
influxdb:
container_name: influxdb
image: influxdb:1.8.10
# ...
volumes:
# ...
- ./volumes/influxdb_fix/influx:/usr/bin/influx
- ./volumes/influxdb_fix/influxd:/usr/bin/influxd
- ./volumes/influxdb_fix/influx_inspect:/usr/bin/influx_inspect
- ./volumes/influxdb_fix/influx_stress:/usr/bin/influx_stress
- ./volumes/influxdb_fix/influx_tools:/usr/bin/influx_tools
With these changes, start the container and see its logfiles:
ts=2024-11-16T09:30:56.839386Z lvl=info msg="InfluxDB starting" log_id=0gFGp3ml000 version=unknown branch=unknown commit=unknown
ts=2024-11-16T09:30:56.839445Z lvl=info msg="Go runtime" log_id=0gFGp3ml000 version=go1.20.1 maxprocs=4
ts=2024-11-16T09:30:56.864545Z lvl=info msg="Using data dir" log_id=0gFGp3ml000 service=store path=/var/lib/influxdb/data
ts=2024-11-16T09:30:56.864715Z lvl=info msg="Compaction settings" log_id=0gFGp3ml000 service=store max_concurrent_compactions=2 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2024-11-16T09:30:56.864839Z lvl=info msg="Open store (start)" log_id=0gFGp3ml000 service=store trace_id=0gFGp3t0000 op_name=tsdb_open op_event=start
panic: unaligned 64-bit atomic operation
goroutine 36 [running]:
runtime/internal/atomic.panicUnaligned()
/usr/local/go/src/runtime/internal/atomic/unaligned.go:8 +0x24
runtime/internal/atomic.Xadd64(0x34ec0d4, 0x1)
/usr/local/go/src/runtime/internal/atomic/atomic_arm.s:258 +0x14
github.com/influxdata/influxdb/tsdb/engine/tsm1.(*accessor).incAccess(...)
Unfortunately, in the first try, the program crashes with this error: panic: unaligned 64-bit atomic operation. After some trial and error, I saw that you only need to substitute the influxd binary. The docker-compose.yml file should look like this:
influxdb:
container_name: influxdb
image: influxdb:1.8.10
# ...
volumes:
# ...
- ./volumes/influxdb_fix/influxd:/usr/bin/influxd
With this change, the container starts and works as expected:
docker logs -f influxdb
...
ts=2024-11-16T09:34:15.300851Z lvl=info msg="InfluxDB starting" log_id=0gFH0B10000 version=1.8.10 branch=1.8 commit=688e697c51fd
ts=2024-11-16T09:34:15.300932Z lvl=info msg="Go runtime" log_id=0gFH0B10000 version=go1.13.8 maxprocs=4
ts=2024-11-16T09:34:15.450423Z lvl=info msg="Using data dir" log_id=0gFH0B10000 service=store path=/var/lib/influxdb/data
ts=2024-11-16T09:34:15.450647Z lvl=info msg="Compaction settings" log_id=0gFH0B10000 service=store max_concurrent_compactions=2 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2024-11-16T09:34:15.466108Z lvl=info msg="Open store (start)" log_id=0gFH0B10000 service=store trace_id=0gFH0BfW000 op_name=tsdb_open op_event=start
ts=2024-11-16T09:34:17.855182Z lvl=info msg="Reading file" log_id=0gFH0B10000 engine=tsm1 service=cacheloader path=/var/lib/influxdb/wal/_internal/monitor/978/_00001.wal size=7448751
...
ts=2024-11-16T09:34:35.496809Z lvl=info msg="Compacting file" log_id=0gFH0B10000 engine=tsm1 tsm1_strategy=full tsm1_optimize=false trace_id=0gFH1Pv0000 op_name=tsm1_compact_group db_shard_id=964 tsm1_index=7 tsm1_file=/var/lib/influxdb/data/fluent/autogen/964/000000073-000000001.tsm
ts=2024-11-16T09:34:35.559465Z lvl=info msg="Continuous query execution (start)" log_id=0gFH0B10000 service=continuous_querier trace_id=0gFH1Q9l000 op_name=continuous_querier_execute op_event=start
Use Retention Policies to Trim Log Files
With InfluxDB running again, I did another optimization. Instead of keeping the log files for an unlimited amount of time, I will delete them after two weeks. The most comfortable solution for this is to use a retention policy, a rule that is applied to your data.
To create a retention policy that deletes all logs older than 14 days, run the following command:
> CREATE RETENTION POLICY "keep_two_weeks" ON "fluent" DURATION 14d REPLICATION 1 DEFAULT
Ensure that the policy is applied:
> show retention policies
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
keep_two_weeks 336h0m0s 24h0m0s 1 true
With these changes, Influx runs smooth again.
Conclusion
Troubleshooting applications is a surprising source of learning. Better understanding how an application works, discovering new configuration options, and overall ensure a more fault-tolerant operations are achievements in itself. This article showed you how to solve an InfluxDB error about compacting large databases. The error is specific to InfluxDB on Docker and happens on small scale single board computers with a limited amount of RAM. The key issue is that InfluxDB tries to put a complete copy of the to be compactified database into the RAM, and this leads to Docker container constantly stopping and restarting. To solve this, the community provides a patched InfluxDB version which you need to compile and use. If you use InfluxDB as a Docker container, you need to mount the binary influxd into the container. Finally, to further prevent too large databases, use retention policies to delete no longer relevant data.