















_Yuri_Arcurs_Alamy.jpg?#)



















![Watch a SpaceX rocket launch Crew-10 relief mission March 14 for NASA astronauts on ISS after delay [updated]](https://cdn.mos.cms.futurecdn.net/TBuLj3rJngaWrbyogNud9H.jpg?#)































From Sparse Rewards to Precise Mastery: How DEMO3 is Revolutionizing Robotic Manipulation
Long-horizon robotic manipulation tasks are a serious challenge for reinforcement learning, caused mainly by sparse rewards, high-dimensional action-state spaces, and the challenge of designing useful reward functions. Conventional reinforcement learning is not well-suited to handle efficient exploration since the lack of feedback hinders learning optimal policies. This issue is significant in robotic control tasks of […] The post From Sparse Rewards to Precise Mastery: How DEMO3 is Revolutionizing Robotic Manipulation appeared first on MarkTechPost.

Long-horizon robotic manipulation tasks are a serious challenge for reinforcement learning, caused mainly by sparse rewards, high-dimensional action-state spaces, and the challenge of designing useful reward functions. Conventional reinforcement learning is not well-suited to handle efficient exploration since the lack of feedback hinders learning optimal policies. This issue is significant in robotic control tasks of multi-stage reasoning, where the achievement of sequential subgoals is essential to overall success. Poorly designed reward structures can cause agents to get stuck in local optima or exploit spurious shortcuts, leading to suboptimal learning processes. Additionally, most of the existing methods have high sample complexity, requiring large amounts of training data to generalize to diverse manipulation tasks. Such constraints render reinforcement learning impossible for real-world tasks, where data efficiency and well-structured learning signals are key to success.
Earlier research that has addressed these issues has explored model-based reinforcement learning, demonstration-based learning, and inverse reinforcement learning. Model-based methods, including TD-MPC2, improve sample efficiency by exploiting predictive world models but require large amounts of exploration to optimally optimize policies. Demonstration-based methods, including MoDem and CoDER, mitigate exploration problems by exploiting expert trajectories but lack good scaling to high-dimensional, long-horizon tasks due to the need for large datasets. Inverse reinforcement learning methods attempt to learn reward functions from demonstrations but lack good generalization ability and computational complexity. Further, most approaches in this field do not exploit the inherent structure of multi-stage tasks and hence do not exploit the possibility of decomposing complex objectives into more tractable subgoals.
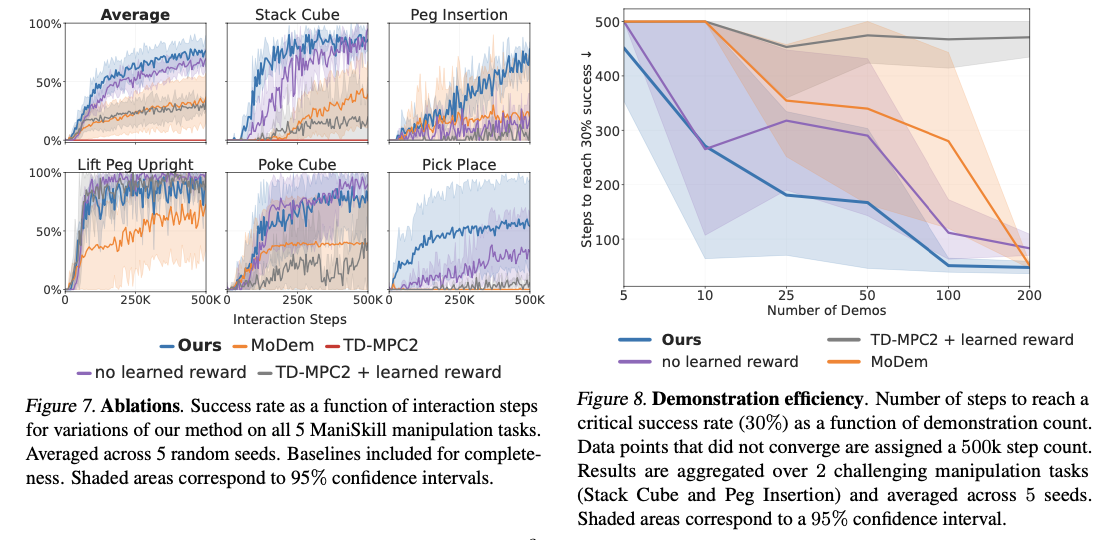
To overcome these challenges, researchers have introduced Demonstration-Augmented Reward, Policy, and World Model Learning (DEMO3), a reinforcement learning framework that integrates structured reward acquisition, policy optimization, and model-based decision-making. The framework introduces three main innovations: the transformation of sparse stage indicators to continuous, structured rewards providing more reliable feedback; a bi-phasic training schedule that initially uses behavioral cloning followed by an interactive reinforcement learning process; and the integration of online world model learning, allowing dynamic penalty adaptation during training. Unlike current approaches, this method allows real-time structured reward acquisition through stage-specific discriminators evaluating the probability of progress toward subgoals. As a result, the framework focuses on the attainment of task goals rather than demonstration imitation, significantly improving sample efficiency and generalization across tasks in robotic manipulation.
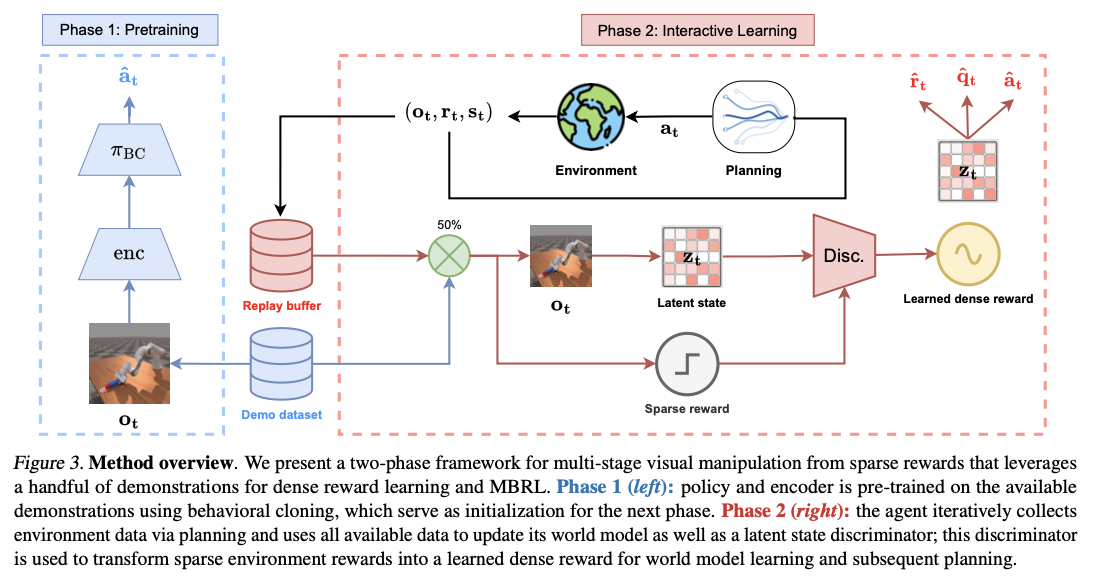
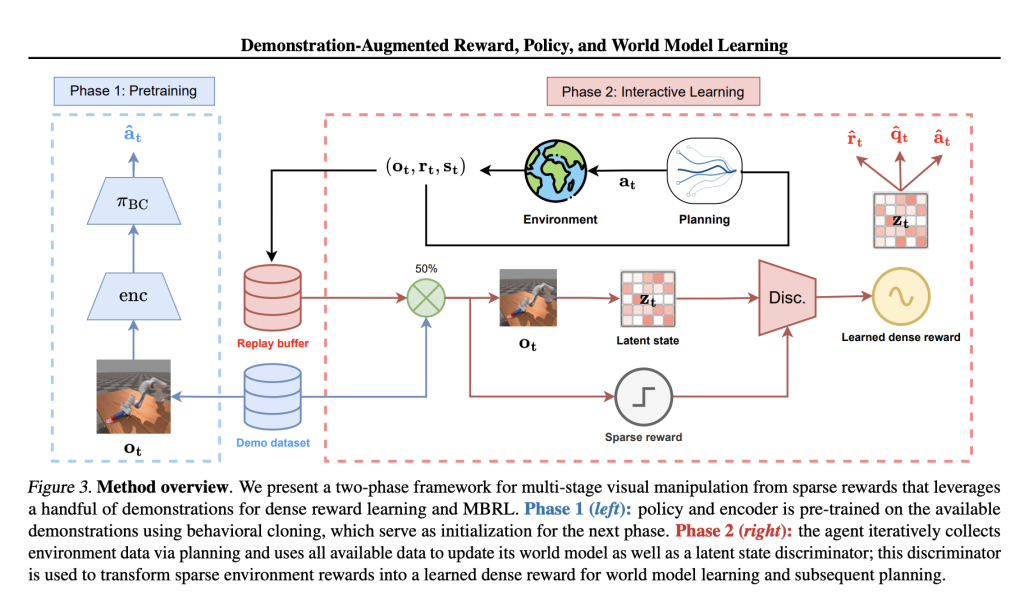
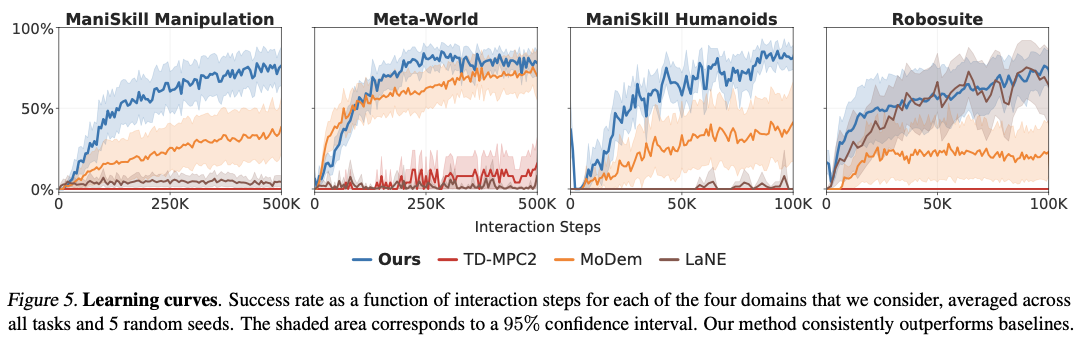
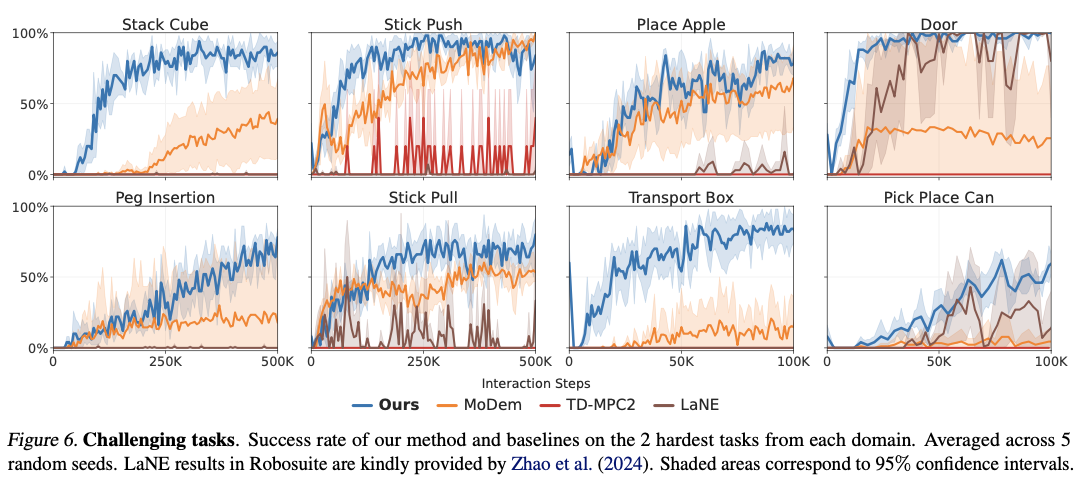
DEMO3 is constructed from the foundation of the TD-MPC2 approach, which learns a latent-space world model for augmenting planning and control steps. The strategy is based on numerous stage-specific discriminators that each learns to forecast the chance of successful transitioning to the upcoming task stage. These discriminators are fine-tuned using the binary cross-entropy loss criterion and assist with online reward shaping, generating richer learning signals compared to sparse conventional rewards. Training adheres to a systematic two-phase process. First, in the pre-training stage, a policy and an encoder are learned using behavioral cloning from a partial set of expert demonstrations. Secondly, the agent engaged in continuous reinforcement learning processes learns to adjust and refine the policy through the process of environment interactions while depending on the derived dense rewards. An annealing process is introduced to improve the efficiency of operations through the transfer of dependence gradually from behavioral cloning to autonomous learning. This smooth transfer enables the progressive transfer of behavior from demonstration-induced imitation to policy improvement independently. The approach is tested on sixteen difficult robotic manipulation tasks, involving Meta-World, Robosuite, and ManiSkill3, and realizes substantial advances in learning efficiency as well as robustness when compared to existing state-of-the-art alternatives.

DEMO3 outperforms state-of-the-art reinforcement learning algorithms by far, garnering significant improvements in sample efficiency, learning time, and overall task completion success rates. The method records an average of 40% improved data efficiency over competing methods, with as much as 70% improvement reported for very difficult, long-horizon challenges. The system always reports high success rates with as few as five demonstrations, compared to competing methods that require much larger datasets to achieve comparable success. By being capable of processing multi-stage sparse reward instances appropriately, the system outperforms accurate robotic manipulation tasks like peg insertion and cube stacking with improved success rates within tight interaction budgets. The computational costs are also comparable, averaging around 5.19 hours for every 100,000 interaction steps, hence making it more efficient than competing reinforcement learning models while yielding superior results in learning complex robotic skills.
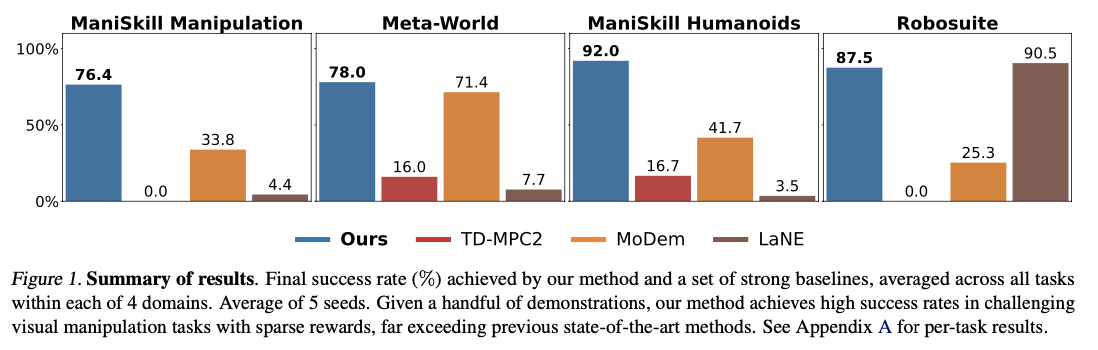
DEMO3 is a significant advance in reinforcement learning tailored for robotic control and is effective in addressing the challenges of dealing with long-horizon tasks with sparse rewards. By leveraging online dense reward learning, structured policy optimization, and model-based decision-making, this framework can achieve high performance and efficiency. The inclusion of a two-phase training procedure and dynamic reward adaptation helps in obtaining spectacular data efficiency improvements with success rates being 40-70% higher compared to existing methodologies on a variety of manipulation tasks. With the improvement of reward shaping, policy learning optimization, and reducing dependence on large demonstration datasets, this method provides the basis for more efficient and scalable robotic learning methods. Future research can be directed towards more advanced demonstration sampling approaches and adaptive reward-shaping techniques to further enhance data efficiency and accelerate reinforcement learning in real-world robotic tasks.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.










