
























































Building a Recipe-Sharing Application
Taming the Traffic Spikes: How I Built a Recipe Sharing Platform That Scales Automatically Picture this: you've built a beautiful recipe website that gets modest traffic most of the day. But when 5 PM rolls around, suddenly 20,000 concurrent users are desperately searching for dinner inspiration. Will your infrastructure buckle under the pressure? This was exactly the challenge I faced when building a recipe sharing application on AWS. Today, I'm going to walk you through how I tackled the specific technical challenge of handling unpredictable, spiky traffic patterns while keeping costs under control. The Problem: Unpredictable Traffic Patterns Recipe websites have a peculiar traffic pattern – relatively quiet most of the day, then massive spikes around meal planning times. Our requirements specifically called for: Supporting up to 20,000 concurrent users during peak hours Maintaining performance during these spikes Keeping costs down during low-traffic periods Global distribution for users across different time zones Traditional "fixed capacity" architectures would either be overprovisioned (wasting money) or underprovisioned (crashing during peaks). Main layers showing presentation, compute, and data layers First Attempt: Single EC2 Instance Architecture My initial approach was straightforward: host everything on a single EC2 instance running both the frontend and backend. # Example FastAPI endpoint in our initial architecture @app.get("/recipes") async def get_recipes(): # Fetch directly from database recipes = await db.fetch_all("SELECT * FROM recipes") return {"recipes": recipes} This setup worked fine during development but had clear limitations: Single point of failure Fixed capacity regardless of actual demand No geographic distribution for global users Limited scaling options When load testing with simulated traffic spikes, the instance CPU would max out, and response times would increase dramatically. Not acceptable! The Breakthrough: Decoupled Architecture with Auto-scaling The solution came from rethinking the entire architecture. Instead of a monolithic design, I decoupled the components: Static Frontend Separated from Dynamic Backend: The React.js frontend is now hosted on S3 and distributed through CloudFront Backend API Behind a Load Balancer: The FastAPI application runs on EC2 instances in private subnets NoSQL Database for Scalable Data Access: DynamoDB provides consistent performance regardless of scale Here's a simplified diagram of the architecture: ┌─────────────┐ │ Users │ └──────┬──────┘ │ ┌─────────────┴─────────────┐ ▼ ▼ ┌─────────────────┐ ┌─────────────────┐ │ CloudFront │ │ ALB │ │ (Frontend CDN) │ │ (Load Balancer) │ └────────┬────────┘ └────────┬────────┘ │ │ ┌────────┴────────┐ ┌────────┴────────┐ │ S3 Bucket │ │ Auto Scaling │ │ (Frontend) │ │ Group │ └─────────────────┘ └────────┬────────┘ │ ┌────────┴────────┐ │ EC2 Instance │ │ (Backend) │ └────────┬────────┘ │ ┌────────┴────────┐ │ DynamoDB │ │ (Database) │ └─────────────────┘ AWS Architecture Diagram for Recipe Sharing Application The Implementation: Infrastructure as Code Rather than manual configuration, I used CloudFormation templates to define the entire infrastructure: # Snippet from CloudFormation template showing the EC2 Auto Scaling Group RecipeApiAutoScalingGroup: Type: AWS::AutoScaling::AutoScalingGroup Properties: VPCZoneIdentifier: !Ref PrivateSubnets LaunchConfigurationName: !Ref LaunchConfig MinSize: '1' MaxSize: '4' DesiredCapacity: '2' TargetGroupARNs: - !Ref TargetGroup Tags: - Key: Name Value: !Sub ${AWS::StackName}-api-instance PropagateAtLaunch: true CLOUDFORMATION STACK CREATION This template creates an Auto Scaling Group that can adjust between 1 and 4 instances based on actual demand. The connection between the backend API and DynamoDB was implemented with AWS SDK for Python: # Example API code accessing DynamoDB import boto3 from fastapi import FastAPI app = FastAPI() dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('recipes') @app.get("/recipes") async def get_recipes(): response = table.scan() return {"recipes": response['Items']}
Taming the Traffic Spikes: How I Built a Recipe Sharing Platform That Scales Automatically
Picture this: you've built a beautiful recipe website that gets modest traffic most of the day. But when 5 PM rolls around, suddenly 20,000 concurrent users are desperately searching for dinner inspiration. Will your infrastructure buckle under the pressure?
This was exactly the challenge I faced when building a recipe sharing application on AWS. Today, I'm going to walk you through how I tackled the specific technical challenge of handling unpredictable, spiky traffic patterns while keeping costs under control.
The Problem: Unpredictable Traffic Patterns
Recipe websites have a peculiar traffic pattern – relatively quiet most of the day, then massive spikes around meal planning times. Our requirements specifically called for:
- Supporting up to 20,000 concurrent users during peak hours
- Maintaining performance during these spikes
- Keeping costs down during low-traffic periods
- Global distribution for users across different time zones
Traditional "fixed capacity" architectures would either be overprovisioned (wasting money) or underprovisioned (crashing during peaks).
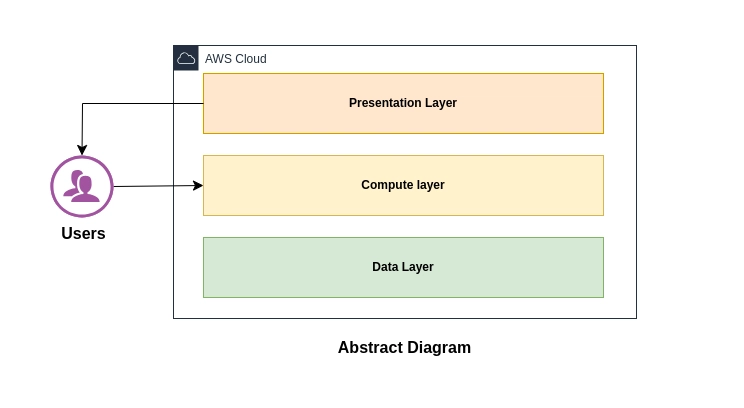
Main layers showing presentation, compute, and data layers
First Attempt: Single EC2 Instance Architecture
My initial approach was straightforward: host everything on a single EC2 instance running both the frontend and backend.
# Example FastAPI endpoint in our initial architecture
@app.get("/recipes")
async def get_recipes():
# Fetch directly from database
recipes = await db.fetch_all("SELECT * FROM recipes")
return {"recipes": recipes}
This setup worked fine during development but had clear limitations:
- Single point of failure
- Fixed capacity regardless of actual demand
- No geographic distribution for global users
- Limited scaling options
When load testing with simulated traffic spikes, the instance CPU would max out, and response times would increase dramatically. Not acceptable!
The Breakthrough: Decoupled Architecture with Auto-scaling
The solution came from rethinking the entire architecture. Instead of a monolithic design, I decoupled the components:
- Static Frontend Separated from Dynamic Backend: The React.js frontend is now hosted on S3 and distributed through CloudFront
- Backend API Behind a Load Balancer: The FastAPI application runs on EC2 instances in private subnets
- NoSQL Database for Scalable Data Access: DynamoDB provides consistent performance regardless of scale
Here's a simplified diagram of the architecture:
┌─────────────┐
│ Users │
└──────┬──────┘
│
┌─────────────┴─────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ CloudFront │ │ ALB │
│ (Frontend CDN) │ │ (Load Balancer) │
└────────┬────────┘ └────────┬────────┘
│ │
┌────────┴────────┐ ┌────────┴────────┐
│ S3 Bucket │ │ Auto Scaling │
│ (Frontend) │ │ Group │
└─────────────────┘ └────────┬────────┘
│
┌────────┴────────┐
│ EC2 Instance │
│ (Backend) │
└────────┬────────┘
│
┌────────┴────────┐
│ DynamoDB │
│ (Database) │
└─────────────────┘
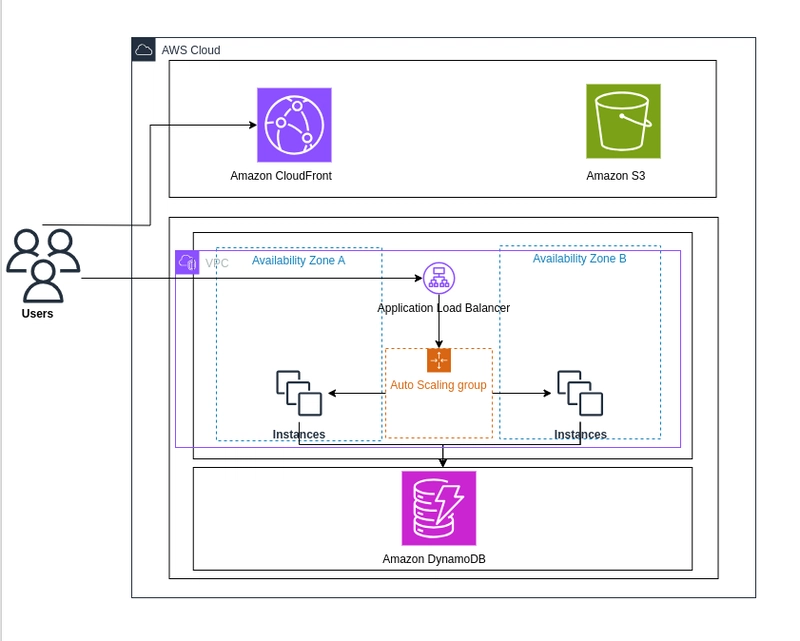
AWS Architecture Diagram for Recipe Sharing Application
The Implementation: Infrastructure as Code
Rather than manual configuration, I used CloudFormation templates to define the entire infrastructure:
# Snippet from CloudFormation template showing the EC2 Auto Scaling Group
RecipeApiAutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
VPCZoneIdentifier: !Ref PrivateSubnets
LaunchConfigurationName: !Ref LaunchConfig
MinSize: '1'
MaxSize: '4'
DesiredCapacity: '2'
TargetGroupARNs:
- !Ref TargetGroup
Tags:
- Key: Name
Value: !Sub ${AWS::StackName}-api-instance
PropagateAtLaunch: true
CLOUDFORMATION STACK CREATION
This template creates an Auto Scaling Group that can adjust between 1 and 4 instances based on actual demand. The connection between the backend API and DynamoDB was implemented with AWS SDK for Python:
# Example API code accessing DynamoDB
import boto3
from fastapi import FastAPI
app = FastAPI()
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('recipes')
@app.get("/recipes")
async def get_recipes():
response = table.scan()
return {"recipes": response['Items']}
Real Examples of Implementation Decisions
1. Database Choice: SQL vs NoSQL
When designing the data layer, I had to choose between traditional relational databases and NoSQL solutions. The decision came down to our data access patterns:
- No complex joins or relationships between entities
- Read-heavy workload (users view recipes far more than they create)
- Need for automatic scaling with no manual intervention
- Simple document structure for recipes
DynamoDB's document model was perfect for storing recipe objects as simple JSON documents:
{
"ID": "550e8400-e29b-41d4-a716-446655440000",
"Title": "Chocolate Chip Cookies",
"Ingredients": [
"2 cups all-purpose flour",
"1/2 teaspoon baking soda",
"1 cup unsalted butter",
"1 cup packed brown sugar",
"1/2 cup white sugar",
"2 eggs",
"2 teaspoons vanilla extract",
"2 cups semisweet chocolate chips"
],
"Steps": [
"Preheat oven to 350°F (175°C).",
"Cream together butter and sugars until smooth.",
"Beat in eggs one at a time, then stir in vanilla.",
"Dissolve baking soda in hot water, add to batter.",
"Mix in flour, chocolate chips, and nuts.",
"Drop by large spoonfuls onto ungreased pans.",
"Bake for about 10 minutes, until edges are browned."
]
}
DYNAMODB TABLE EXPLORATION
2. Frontend Content Delivery: S3 + CloudFront
For the frontend, I needed a solution that would:
- Scale globally
- Require zero maintenance
- Provide fast load times worldwide
- Support HTTPS securely
The S3 + CloudFront combination perfectly solved this requirement, automatically distributing content to edge locations closest to users:
// Example React component configuration pointing to our API endpoint
// in src/config.js
export const config = {
API_URL: 'https://api.example.com',
CONFIG_MAX_INGREDIENTS: 20,
CONFIG_MAX_STEPS: 15,
CONFIG_MAX_RECIPES: 100,
CONFIG_USER_PAGE_TITLE: 'Discover Amazing Recipes',
CONFIG_ADMIN_PAGE_TITLE: 'Recipe Management'
};
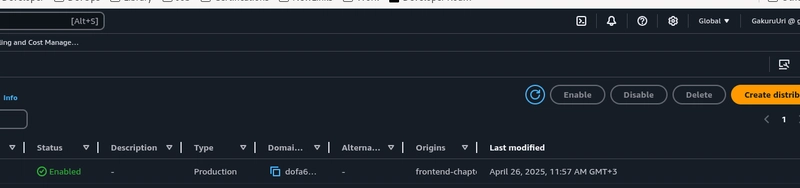
CLOUDFRONT DISTRIBUTION URL
The Results: Performance Under Pressure
After implementation, the architecture handled simulated traffic spikes gracefully:
- During low-traffic periods, a single instance serves all requests (minimizing costs)
- As traffic increases, Auto Scaling adds instances based on CPU metrics
- Read operations on DynamoDB remain consistent even with thousands of concurrent users
- Global users experience fast loading times thanks to CloudFront's global edge locations
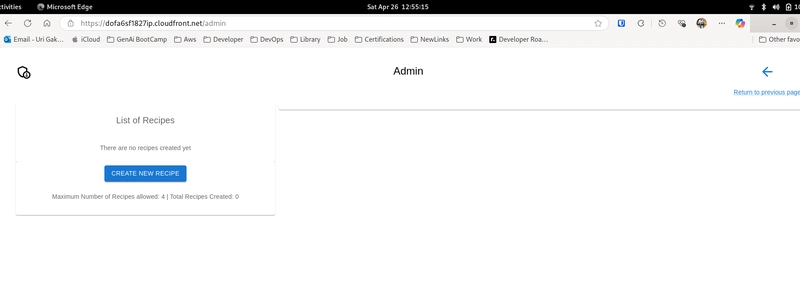
RECIPE SHARING APPLICATION ADMIN PAGE
Questions for Discussion
- Have you experienced similar traffic spike challenges? How did you address them?
- What's your preferred approach to auto-scaling – CPU-based or traffic-based metrics?
- Do you use Infrastructure as Code in your projects, or do you prefer manual configuration?
- What strategies have you found effective for keeping cloud costs down while maintaining scalability?
- How do you handle database scaling in applications with unpredictable traffic patterns?
I'd love to hear about your experiences in the comments!
Tags: #aws, #cloud-architecture, #serverless, #devops, #web-development, #infrastructure-as-code, #scalability
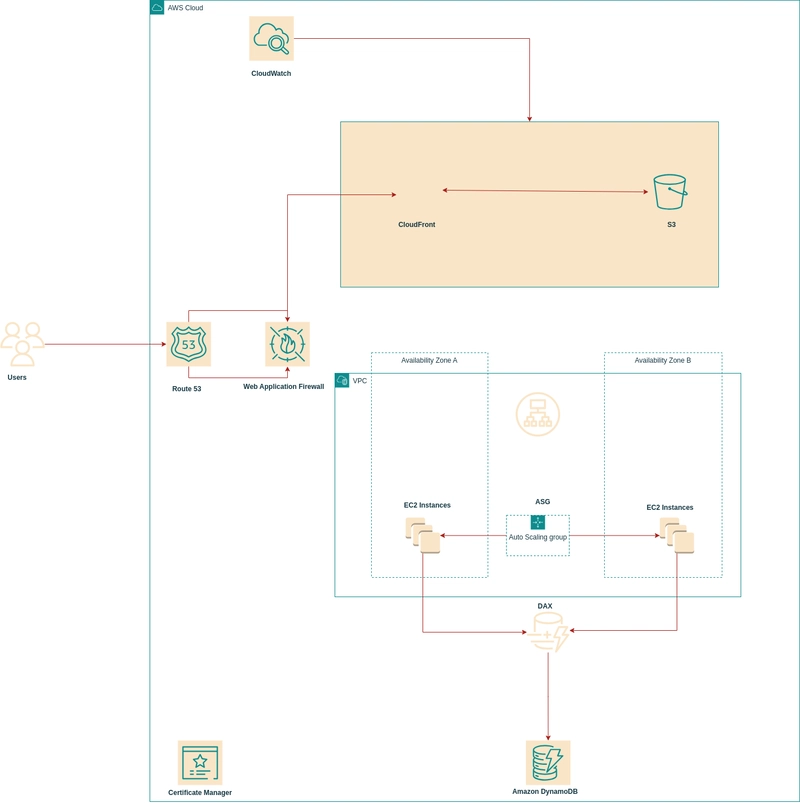
Final Architecture diagram