































































数据科学中的数据清理
在本数据科学博文系列中,我们探讨了从哪里获取数据以及如何使用 pandas 探索数据,不过虽然这些数据对于学习非常有用,但它与我们所说的真实世界数据并不相似。 用于学习的数据通常已经过清理和整理,方便您快速学习而不必考虑数据清理,但真实世界数据存在问题并且很混乱。 真实世界数据需要清理才能提供有用的洞察,这就是本文的主题。 数据问题可能来自数据本身的行为、数据收集方式,甚至是数据输入方式。 流程的每个阶段都可能发生错误和疏忽。 我们在这里专门讨论数据清理而不是数据转换。 数据清理可以确保您从数据中得出的结论可以泛化到您定义的总体。 数据转换则涉及转换数据格式、对数据进行归一化和聚合数据等任务。 数据清理为什么重要? 关于数据集,我们首先需要了解的是它们代表什么。 大多数数据集都是代表更广泛总体的样本,通过处理此样本,您能够将发现外推(或泛化)到该总体。 例如,我们在前两篇博文中使用了一个数据集。 这个数据集广泛涉及房屋销售,但只覆盖一小块地理区域、一小段时间,并且可能不是该区域和时间段内的所有房屋;它是一个更大总体的样本。 您的数据需要是更广泛总体的代表性样本,例如该地区在一段规定时间内的所有房屋销售情况。 为了确保我们的数据是更广泛总体的代表性样本,我们必须首先定义总体的边界。 您可能会想到,除了人口普查数据以外,使用整个总体往往不切实际,因此您需要确定您的边界。 这些边界可能是地理的、人口统计的、基于时间的、基于行动的(例如事务性)或特定于行业的。 您可以通过多种方式定义总体,但要可靠地泛化数据,必须在清理数据之前进行定义。 总体而言,如果您计划将数据用于任何类型的分析或机器学习,您都需要花时间清理数据,确保您可以依赖您的洞察并将其泛化到真实世界。 清理数据可以获得更准确的分析,并且在机器学习方面也可以提高性能。 如果不清理数据,您会面临许多风险,例如无法将研究结果可靠地泛化到更广泛的总体、不准确的汇总统计信息和不正确的可视化效果。 如果您使用数据训练机器学习模型,这也可能导致错误和不准确的预测。 免费试用 PyCharm Professional 数据清理示例 我们将介绍可用于清理数据的五项任务。 这份列表并不完整,但对于处理真实世界数据是一个很好的起点。 对数据去重 重复问题会扭曲您的数据。 假设,您正在绘制一个使用销售价格频率的直方图。 如果有相同值的重复项,最终会得到一个基于重复价格的不准确模式的直方图。 另外,当我们谈论数据集中的重复问题时,我们谈论的是整行的重复,每一行都是一个单独的观察值。 列中将有重复值,如我们所预料。 我们只谈论重复观察值。 好在我们可以使用一种 pandas 方法帮助我们检测数据中是否存在重复项。 如果需要提醒,我们可以使用 JetBrains AI 聊天编写提示,例如: Code to identify duplicate rows 得到代码: duplicate_rows = df[df.duplicated()] duplicate_rows 此代码假定您的 […]

在本数据科学博文系列中,我们探讨了从哪里获取数据以及如何使用 pandas 探索数据,不过虽然这些数据对于学习非常有用,但它与我们所说的真实世界数据并不相似。 用于学习的数据通常已经过清理和整理,方便您快速学习而不必考虑数据清理,但真实世界数据存在问题并且很混乱。 真实世界数据需要清理才能提供有用的洞察,这就是本文的主题。
数据问题可能来自数据本身的行为、数据收集方式,甚至是数据输入方式。 流程的每个阶段都可能发生错误和疏忽。
我们在这里专门讨论数据清理而不是数据转换。 数据清理可以确保您从数据中得出的结论可以泛化到您定义的总体。 数据转换则涉及转换数据格式、对数据进行归一化和聚合数据等任务。
数据清理为什么重要?
关于数据集,我们首先需要了解的是它们代表什么。 大多数数据集都是代表更广泛总体的样本,通过处理此样本,您能够将发现外推(或泛化)到该总体。 例如,我们在前两篇博文中使用了一个数据集。 这个数据集广泛涉及房屋销售,但只覆盖一小块地理区域、一小段时间,并且可能不是该区域和时间段内的所有房屋;它是一个更大总体的样本。
您的数据需要是更广泛总体的代表性样本,例如该地区在一段规定时间内的所有房屋销售情况。 为了确保我们的数据是更广泛总体的代表性样本,我们必须首先定义总体的边界。
您可能会想到,除了人口普查数据以外,使用整个总体往往不切实际,因此您需要确定您的边界。 这些边界可能是地理的、人口统计的、基于时间的、基于行动的(例如事务性)或特定于行业的。 您可以通过多种方式定义总体,但要可靠地泛化数据,必须在清理数据之前进行定义。
总体而言,如果您计划将数据用于任何类型的分析或机器学习,您都需要花时间清理数据,确保您可以依赖您的洞察并将其泛化到真实世界。 清理数据可以获得更准确的分析,并且在机器学习方面也可以提高性能。
如果不清理数据,您会面临许多风险,例如无法将研究结果可靠地泛化到更广泛的总体、不准确的汇总统计信息和不正确的可视化效果。 如果您使用数据训练机器学习模型,这也可能导致错误和不准确的预测。
数据清理示例
我们将介绍可用于清理数据的五项任务。 这份列表并不完整,但对于处理真实世界数据是一个很好的起点。
对数据去重
重复问题会扭曲您的数据。 假设,您正在绘制一个使用销售价格频率的直方图。 如果有相同值的重复项,最终会得到一个基于重复价格的不准确模式的直方图。
另外,当我们谈论数据集中的重复问题时,我们谈论的是整行的重复,每一行都是一个单独的观察值。 列中将有重复值,如我们所预料。 我们只谈论重复观察值。
好在我们可以使用一种 pandas 方法帮助我们检测数据中是否存在重复项。 如果需要提醒,我们可以使用 JetBrains AI 聊天编写提示,例如:
Code to identify duplicate rows
得到代码:
duplicate_rows = df[df.duplicated()] duplicate_rows
此代码假定您的 DataFrame 名为 df,因此如果不是这个名字,应该将其更改为 DataFrame 的名称。
我们一直在使用的 Ames Housing 数据集中没有重复数据,但如果您想尝试,可以选择 CITES Wildlife Trade Database 数据集,看看是否可以使用上述 pandas 方法找到重复项。
在数据集中发现重复项后,必须将其移除,避免扭曲结果。 您同样可以使用 JetBrains AI 为此获取代码,提示如下:
Code to drop duplicates from my dataframe
生成的代码会删除重复项,重置 DataFrame 的索引,然后将其显示为名为 df_cleaned 的新 DataFrame:
df_cleaned = df.drop_duplicates() df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
还有其他 pandas 函数可用于更高级的重复项管理,但这已经足以让您开始对数据集进行去重。
处理不合理值
当数据输入错误或数据收集过程中出现问题时,可能会出现不合理值。 对于我们的 Ames Housing 数据集,不合理值可能是负的 SalePrice,或者 Roof Style 的数字值。
要发现数据集中的不合理值,需要采取广泛的方式,包括查看汇总统计信息、检查收集器为每列定义的数据验证规则、注意不在验证范围内的任何数据点,以及使用可视化效果确定模式和看起来可能异常的情况。
您需要处理不合理值,因为它们会增加噪音并给分析带来问题。 不过,如何处理这些值则需要视情况而定。 如果相对于数据集大小没有太多不合理值,您可以移除包含它们的记录。 例如,如果在数据集的第 214 行中发现了一个不合理值,您可以使用 pandas drop 函数从数据集中移除该行。
同样,我们可以使用提示让 JetBrains AI 生成我们需要的代码:
Code that drops index 214 from #df_cleaned
注意,在 PyCharm 的 Jupyter Notebook 中,我可以在单词前加上 # 符号,向 JetBrains AI Assistant 表明我正在提供额外上下文,在本例中,DataFrame 被称为 df_cleaned。
生成的代码将从 DataFrame 中移除该观察值,重置索引并显示:
df_cleaned = df_cleaned.drop(index=214) df_cleaned.reset_index(drop=True, inplace=True) df_cleaned
处理不合理值的另一种常用策略是插补,即根据定义的策略用不同的合理值替换该值。 最常见的策略之一是使用中位值替换不合理值。 由于中位数不受异常值影响,数据科学家通常为此目的选择它,但同样,在某些情况下,数据的平均值或众数值可能更合适。
或者,如果您具有关于数据集以及数据收集方式的领域知识,可以用更有意义的值替换不合理值。 如果您参与或了解数据收集流程,这个选项可能更合适。
不合理值的处理取决于它们在数据集中的普遍性、数据的收集方式和您打算如何定义总体以及领域知识等其他因素。
格式化数据
您经常可以在汇总统计信息或为了解数据形状而执行的早期可视化中发现格式设置问题。 格式不一致的一些例子包括数字值没有全部定义到相同的小数位,或拼写方面的差异,例如“first”和“1st”。 不正确的数据格式设置也会对数据的内存占用产生影响。
发现数据集中的格式设置问题后,就需要将值标准化。 根据面临的问题,这通常涉及定义您自己的标准和应用更改。 同样,pandas 库在这里有一些有用的函数,例如 round。 如果要将 SalePrice 列四舍五入到小数点后 2 位,我们可以让 JetBrains AI 生成代码:
Code to round #SalePrice to two decimal places
生成的代码将执行舍入,然后打印出前 10 行以供检查:
df_cleaned['SalePrice'] = df_cleaned['SalePrice].round(2) df_cleaned.head()
再举一个拼写可能不一致的例子 – 例如,HouseStyle 列同时包含“1Story”和“OneStory”,并且您确信它们是同一个意思。 可以使用以下提示获取代码:
Code to change all instances of #OneStory to #1Story in #HouseStyle
生成的代码会将 OneStory 的所有实例替换为 1Story:
df_cleaned[HouseStyle'] = df_cleaned['HouseStyle'].replace('OneStory', '1Story')
解决异常值
异常值在数据集中非常常见,但如何处理它们(如果有)则非常依赖于具体情况。 发现异常值的最简单方式之一是使用箱线图,它使用 seaborn 和 matplotlib 库。 如果您需要快速回顾,我先前在关于使用 pandas 探索数据的博文中探讨过箱线图。
对于这个箱线图,我们将查看 Ames Housing 数据集中的 SalePrice。 同样,我将使用 JetBrains AI 生成代码,给出如下提示:
Code to create a box plot of #SalePrice
以下是我们需要运行的代码:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=df_cleaned['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
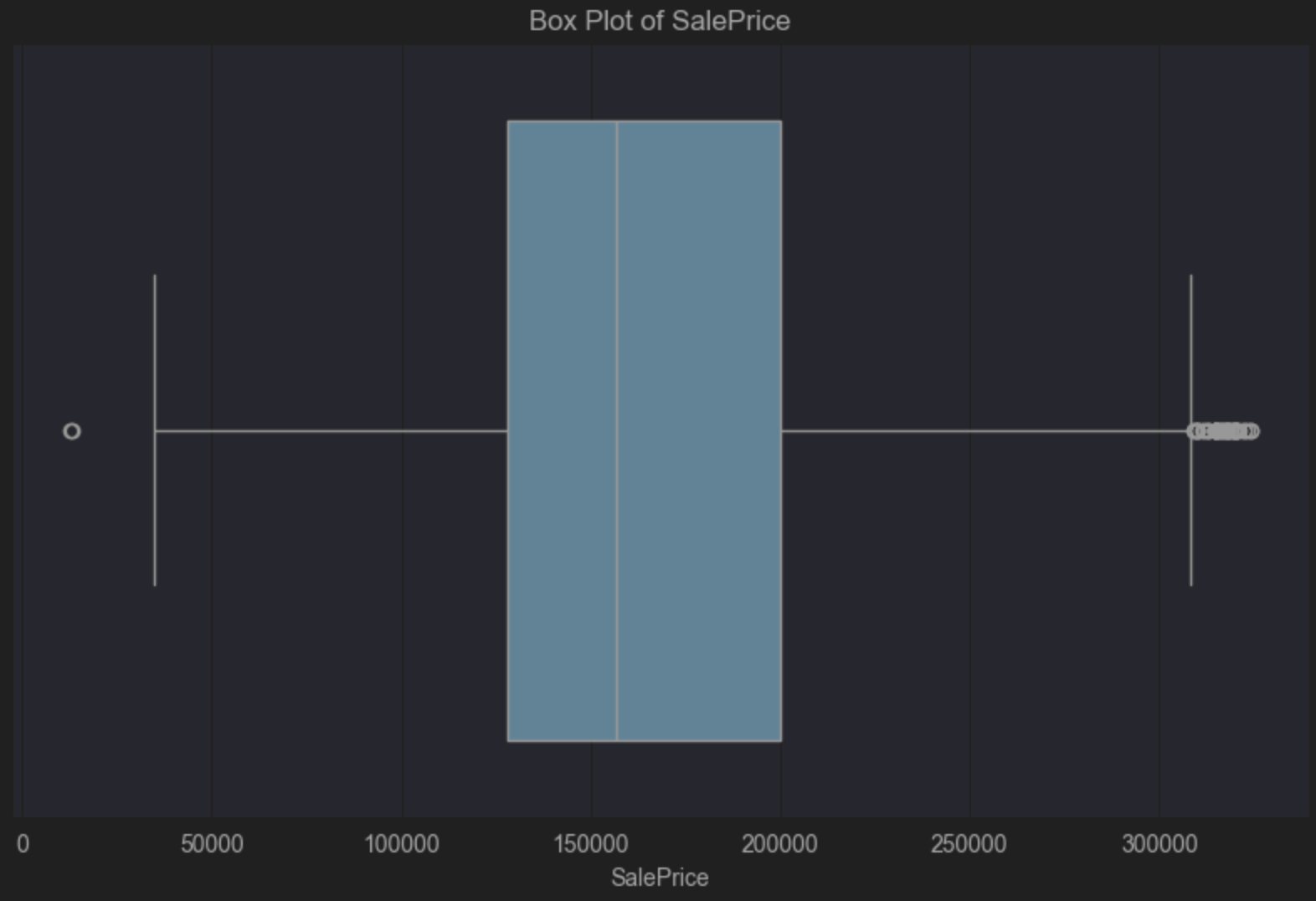
箱线图告诉我们有一个正偏斜,因为蓝色框内的垂直中线位于中心的左侧。 正偏斜告诉我们,较低端的房价更多,这并不奇怪。 箱线图还直观地告诉我们右侧有很多异常值。 这些房屋的数量很少,但其价格却远高于中位价格。
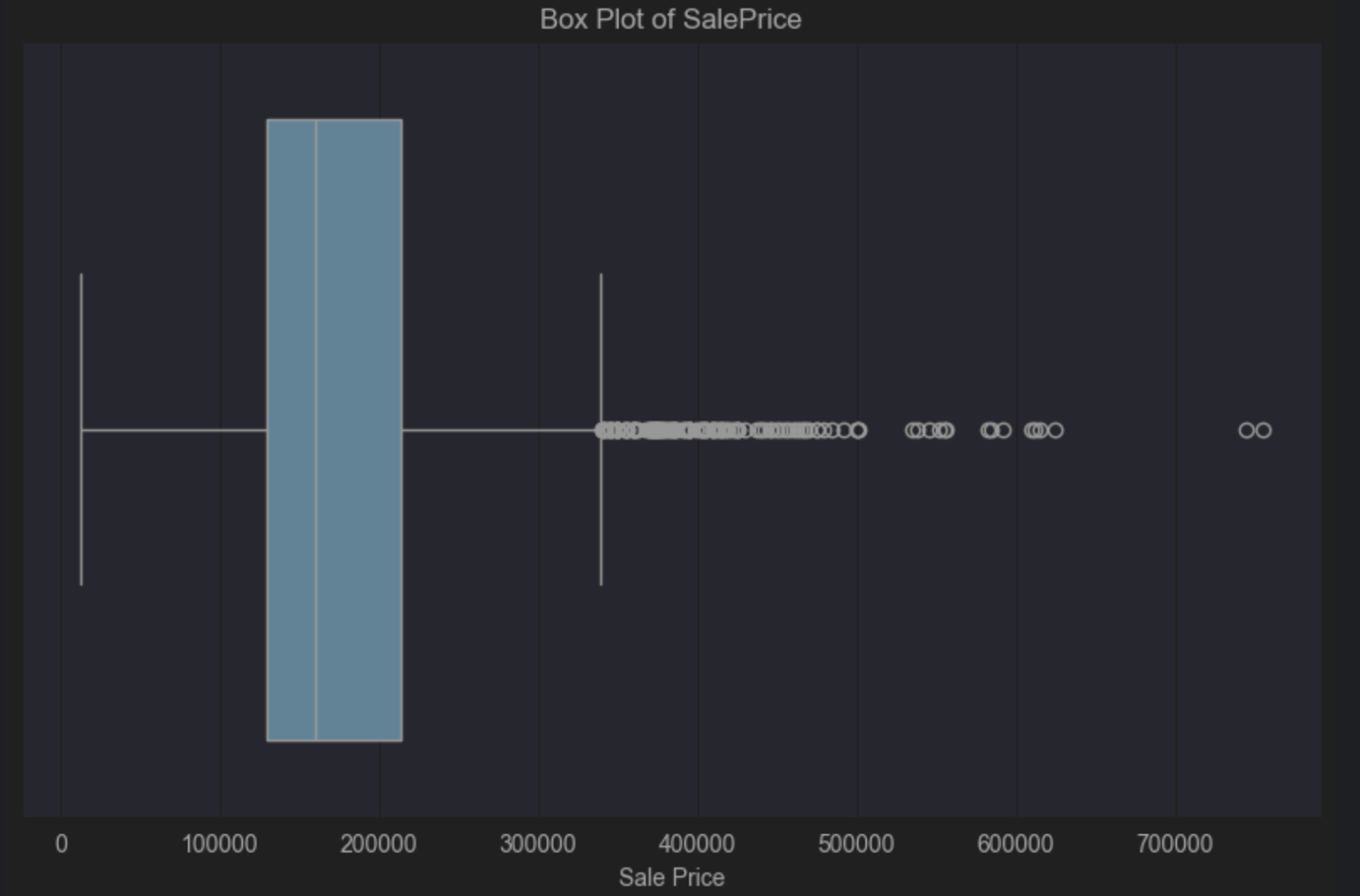
您可能会接受这些异常值,因为预计少数房屋的价格高于大多数房屋的价格是很正常的。 不过,这完全取决于您想要泛化到的总体以及您想要从数据中得出的结论。 明确界定什么是总体的一部分、什么不是总体的一部分,可以让您做出明智的决定,判断数据中的异常值是否会成为问题。
例如,如果总体由不会购买昂贵豪宅的人群组成,那么您可能可以删除这些异常值。 如果总体人口结构中包括可能购买这些昂贵房屋的人群,那么您可能应该将它们保留,因为它们与您的总体相关。
我在这里讲解了箱线图作为发现异常值的方式,但散点图和直方图等选项也可以快速显示数据中是否存在异常值,让您做出明智的决定,判断是否需要对它们采取任何措施。
解决异常值通常分为两类 – 将其删除或使用不易出现异常值的汇总统计信息。 首先,我们需要确切知道它们是哪些行。
到目前为止,我们只讨论了如何通过视觉识别。 还有不同的方式来确定哪些观察值是异常值,哪些不是异常值。 一种常见的方式是使用修正 Z 分数。 在我们了解如何以及为何修正之前,Z 分数定义为:
Z 分数 = (数据点值 – 平均值) / 标准差
修正 Z 分数来检测异常值的原因是,平均值和标准差由于计算方式都容易受到异常值的影响。 修正 Z 分数定义为:
修正 Z 分数 = (数据点值 – 中位数) / 绝对偏差中位数
正如我们在讨论汇总统计信息时所了解到的,中位数不受异常值影响。 绝对偏差中位数是数据集与中位数的绝对偏差的中位值。 例如,如果数据集包含以下值:
1, 2, 2, 2, 3, 3, 3, 5,9
那么中位数就是 3,即数据集中间的值。 与中位值 3 的偏差按上面列出的顺序如下:
2, 1, 1, 1, 0, 0, 0, 2, 5
按升序排列:
0, 0, 0, 1, 1, 1, 2, 2, 5
这意味着此示例中的绝对偏差中位数为 1。
如何计算 SalePrice 数据集的修正 Z 分数? 向 JetBrains AI 提供以下提示:
Given:
Modified Z-score = (data point value – median) / median absolute deviation
Calculate the Modified Z-score for #SalePrice
这会产生以下代码:
import pandas as pd from scipy.stats import median_abs_deviation # Assuming 'data' is your DataFrame and it contains the 'SalePrice' column # Calculate the median for the SalePrice column median_sale_price = data['SalePrice'].median() # Calculate the Median Absolute Deviation (MAD) for the SalePrice column mad_sale_price = median_abs_deviation(data['SalePrice'], scale='normal') # Calculate the Modified Z-scores for the SalePrice column data['Modified_Z_Score'] = (data['SalePrice'] - median_sale_price) / mad_sale_price # Display the first few rows with the Modified Z-scores print(data[['SalePrice', 'Modified_Z_Score']].head())
安装所需软件包并运行此代码后,我们可以看到我们已经完成了一部分,但现在我们需要根据修正 Z 分数来确定 SalePrice 的异常值。 一般观点是,异常值是任何 >=3 或 <=-3 的值,不过,值得注意的是,像大多数统计决策一样,它可以并且应当根据您的数据集进行调整。 <=-3 however, it’s worth noting that like most statistical decisions, it can and should be tailored to your dataset.
我们再给 JetBrains AI 传递一个提示,进一步定制输出:
Just list those that have a #Modified_Z_Score of 3 or above or -3 or below
我将选取这段代码,把它替换为上面的相关行:
# Filter the rows where the Modified Z-score is 3 or above, or -3 or below outliers = data[(data['Modified_Z_Score'] >= 3) | (data['Modified_Z_Score'] <= -3)] # Print all the filtered rows, showing their index and SalePrice outliers = (outliers[['SalePrice', 'Modified_Z_Score']]) outliers
我修改了这段代码,将异常值保存在名为 outliers 的新 DataFrame 中并将其打印出来以供查看。
下一步是从 DataFrame 中移除这些异常值。 我们再次使用 JetBrains AI 生成代码,提示如下:
Create a new dataframe without the outliers
data_without_outliers = data.drop(index=outliers.index) # Display the new DataFrame without outliers print(data_without_outliers)
我们的新 DataFrame (data_without_outliers) 排除了那些 SalePrice 变量被视为异常值的值。
我们可以更新箱线图代码来查看新的 DataFrame。 如我们的预期,它仍然显示出正偏斜,但被视为异常值的值已被移除:
import seaborn as sns
import matplotlib.pyplot as plt
# Create a box plot for SalePrice
plt.figure(figsize=(10, 6))
sns.boxplot(x=data_without_outliers['SalePrice'])
plt.title('Box Plot of SalePrice')
plt.xlabel('SalePrice')
plt.show()
在结束之前,我们看一下从 DataFrame 中移除的观察值占比是多少,因为我们根据 SalePrice 将它们视为异常值。
我们可以使用如下提示:
Calculate the percentage of observations removed between #data and #data_without_outliers
# Calculate the number of observations in the original and filtered DataFrames
original_count = len(data)
filtered_count = len(data_without_outliers)
# Calculate the number of removed observations
removed_count = original_count - filtered_count
# Calculate the percentage of observations removed
percentage_removed = (removed_count / original_count) * 100
# Display the percentage
print(f"Percentage of observations removed: {percentage_removed:.2f}%")
PyCharm 告诉我们 5.67% 的观察值已被移除。
如前所述,如果要保留异常值,可以使用中位数和四分位距等不易受异常值影响的汇总值。 如果您知道处理的数据集包含未移除的异常值,因为它们与您定义的总体和想要得出的结论相关,您可以使用这些测量值来得出结论。
缺失值
发现数据集中缺失值的最快方式是使用汇总统计信息。 提醒一下,在 DataFrame 中,点击右侧的 Show Column Statistics(显示列统计信息),然后选择 Compact(紧凑)。 列中的缺失值以红色显示,如我们的 Ames Housing 数据集中的 Lot Frontage 所示:

对于我们的数据,我们需要考虑三种缺失:
- 完全随机缺失
- 随机缺失
- 非随机缺失
完全随机缺失
完全随机缺失意味着数据完全偶然缺失,并且缺失的事实与数据集中的其他变量无关。 例如,有人忘记回答调查问题时,就会发生这种情况。
完全随机缺失的数据很少见,但也是最容易处理的数据之一。 如果有相对较少的观察值完全随机缺失,最常见的方式是删除这些观察值,因为这样不会影响数据集的完整性,从而不会影响您希望得出的结论。
随机缺失
随机缺失看起来没有模式,但我们可以通过测量的其他变量来解释这种模式。 例如,有人由于数据收集方式没有回答调查问题。
再来看我们的 Ames Housing 数据集,对于某些房地产中介出售的房屋,也许 Lot Frontage 变量缺失的频率更高。 在这种情况下,这种缺失可能是由于某些机构的数据录入做法不一致造成的。 如果属实,那么 Lot Frontage 数据的缺失与出售该房产的机构收集数据的方式有关(这是一个观察到的特征),而与 Lot Frontage 本身无关。
当数据随机缺失时,您会想了解数据缺失的原因,这通常需要深入探究数据的收集方式。 了解数据缺失原因后,就可以选择要采取的操作。 处理随机缺失的一种常见方式是插补值。 我们已经针对不合理值探讨过这种方式,但它也是一个解决缺失的有效策略。 根据定义的总体和想要得出的结论,您可以选择多种选项,在此示例中包括使用房屋大小、建造年份和销售价格等相关变量。 如果您了解缺失数据背后的模式,您通常可以使用上下文信息插补值,从而确保数据集中数据之间的关系得以保留。
非随机缺失
最后,非随机缺失是指缺失数据的可能性与未观察到的数据有关。 这意味着缺失取决于未观察到的数据。
我们最后一次回到 Ames Housing 数据集以及我们在 Lot Frontage 中缺失数据的事实。 一种非随机数据缺失的情况是卖家认为 Lot Frontage 较小,故意选择不报告,因为报告可能会降低房价。 如果 Lot Frontage 数据缺失的可能性取决于正面本身的大小(未观察到),更小的地块正面被报告的可能性更小,意味着缺失与缺失值直接相关。
直观呈现缺失
每当数据缺失时,您都需要确定是否存在模式。 如果存在模式,那么在泛化数据之前您很可能必须解决这个问题。
寻找模式的最简单方式之一是使用热图可视化。 在进入代码之前,我们先排除没有缺失的变量。 我们可以提示 JetBrains AI 生成代码:
Code to create a new dataframe that contains only columns with missingness
得到代码:
# Identify columns with any missing values columns_with_missing = data.columns[data.isnull().any()] # Create a new DataFrame with only columns that have missing values data_with_missingness = data[columns_with_missing] # Display the new DataFrame print(data_with_missingness)
运行代码之前,更改最后一行,以便我们可以从 PyCharm 的 DataFrame 布局中受益:
data_with_missingness
现在该创建热图了,我们将再次提示 JetBrains AI 生成代码:
Create a heatmap of #data_with_missingness that is transposed
得到代码:
import seaborn as sns
import matplotlib.pyplot as plt
# Transpose the data_with_missingness DataFrame
transposed_data = data_with_missingness.T
# Create a heatmap to visualize missingness
plt.figure(figsize=(12, 8))
sns.heatmap(transposed_data.isnull(), cbar=False, yticklabels=True)
plt.title('Missing Data Heatmap (Transposed)')
plt.xlabel('Instances')
plt.ylabel('Features')
plt.tight_layout()
plt.show()
请注意,我从热图实参中移除了 cmap=’viridis’,因为我感觉它难以查看。
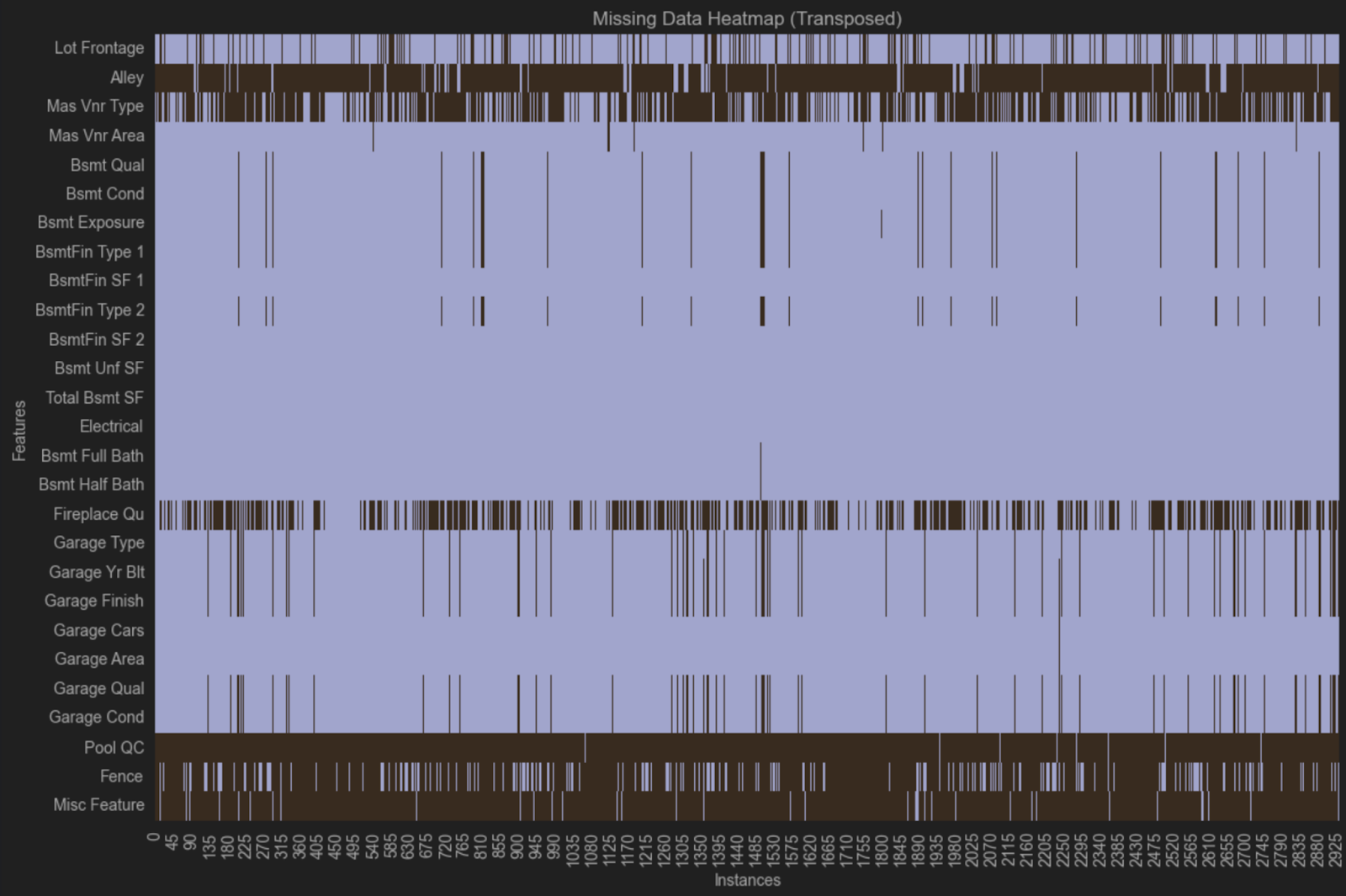
热图表明可能存在缺失模式,因为相同的变量在多行中缺失。 在一组中,我们可以看到 Bsmt Qual、Bsmt Cond、Bsmt Exposure、BsmtFin Type 1 和 Bsmt Fin Type 2 在相同的观察值中全部缺失。 在另一组中,我们可以看到相同的观察值中缺失 Garage Type、Garage Yr Bit、Garage Finish、Garage Qual 和 Garage Cond。
这些变量都与地下室和车库有关,但还有其他与车库或地下室相关的变量并没有缺失。 一种可能的解释是,在收集数据时,不同房产中介对车库和地下室提出了不同的问题,而且并非所有中介都在数据库中记录了尽可能多的详细信息。 这种情况在您没有自行收集的数据上很常见,如果您需要详细了解数据集中的缺失,可以探索数据的收集方式。
数据清理的最佳做法
如前所述,定义总体是数据清理最佳做法的重点。 开始清理数据之前,您应该清楚自己想要实现什么以及如何泛化数据。
您需要确保所有方法都可重现,因为可重现性也说明数据干净。 不可重现的情况后续可能产生重大影响。 因此,我建议保持 Jupyter Notebook 整洁有序,同时利用 Markdown 功能记录每一步决策,特别是在清理时。
清理数据时,您应当逐步进行,修改 DataFrame 而不是原始 CSV 文件或数据库,并确保使用可重现、记录良好的代码完成所有操作。
总结
数据清理是一个很大的话题,可能存在很多挑战。 数据集越大,清理过程就越具有挑战性。 您需要注意总体以更广泛地泛化结论,同时在移除和插补缺失值之间取得平衡,并理解数据缺失的根本原因。
您可以把自己想象成数据的声音。 您了解数据的历程以及如何在各个阶段维护数据完整性。 您是记录这段历程并与他人分享的最佳人选。
本博文英文原作者:









