




![Why are some people more boring while others are less boring [closed]](https://cdn.sstatic.net/Sites/interpersonal/Img/apple-touch-icon@2.png?v=17e836faa592)























































xVerify: Accurate, Efficient LLM Answer Verifier for Reasoning Model Evaluation
This is a Plain English Papers summary of a research paper called xVerify: Accurate, Efficient LLM Answer Verifier for Reasoning Model Evaluation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Rise of Reasoning Models and the Evaluation Challenge As language models increasingly adopt "slow thinking" strategies inspired by OpenAI's o1 model, they produce longer, more complex responses. These outputs often include detailed reasoning steps, intermediate calculations, and self-reflection. This evolution creates significant evaluation challenges for existing methods, which struggle to extract final answers from lengthy reasoning traces and accurately determine whether they match reference answers. Traditional evaluation approaches fall into two categories: rule-based frameworks and LLM-based judgment methods. Rule-based methods often fail to properly extract final answers and struggle with varied answer formats, while LLM judges are typically designed for subjective scoring rather than binary correctness judgments on objective questions. Framework of xVerify showing the three-stage process from data collection to evaluation To address these limitations, researchers introduce xVerify, an efficient answer verifier specifically designed for evaluating reasoning model responses on objective questions. Unlike existing methods, xVerify can process full model outputs to accurately identify final answers from complex reasoning traces and robustly check answer equivalence across different formats. Formalizing the Evaluation Problem The evaluation task is formalized as a 4-tuple (Q,R,Aref,E), where: Q represents the set of questions R contains the responses generated by an LLM Aref is the set of reference answers E is the evaluation function that determines correctness For the answer extraction stage, given a response r to question q, the system identifies candidate answers A(r) and selects the final answer using a scoring function. For the equivalence comparison stage, the system needs to determine whether the extracted answer is equivalent to the reference answer. This comparison must handle mathematical expressions, symbol conversions, and semantic matching to accommodate different but equivalent representations of the same answer. For example, "α" and "alpha" or "100" and "one hundred" should be recognized as equivalent. Building the VAR Dataset To train and evaluate xVerify, the researchers constructed the VAR (Verify Answer for Reasoning) dataset, which includes: Diverse LLM responses: Collected from 19 different LLMs (from 0.5B to 32B parameters) across 24 reasoning-focused datasets, with particular emphasis on recently released reasoning models like DeepSeek-R1-Distill series and QwQ-32B. Dataset Type #Train #Test Language License CMMLU Choice 2000 1000 Chinese CC-BY-NC-4.0 C-Eval Choice 1346 260 Chinese CC-BY-NC-SA-4.0 GPQA Choice 794 398 English CC-BY-4.0 MMLU Choice 1816 1000 English MIT MMLU-Pro Choice 2000 1000 English MIT MMLU-Redux Choice 2000 1000 English CC-BY-4.0 AgNews Classification 2000 1000 English Unspecified Amazon Classification 2000 1000 English Apache-2.0 CLUEWSC Classification 1548 1000 Chinese Unspecified CMNLI Classification 2000 1000 Chinese Apache-2.0 AMC23 Math 26 14 English Unspecified AIME 2024 Math 20 10 English MIT CMATH Math 1128 565 Chinese CC-BY-4.0 GSM8K Math 2000 1000 English MIT LiveMathBench Math 190 93 English & Chinese CC-BY-4.0 MATH Math 2000 1000 English MIT MGSM Math 1892 946 Multilingual CC-BY-SA-4.0 OlympiadBench Math 1787 892 English & Chinese Apache-2.0 ARC Short Answer 2000 1000 English CC-BY-SA-4.0 CHID Short Answer 2000 1000 Chinese Apache-2.0 C-SimpleQA Short Answer 2000 1000 Chinese CC-BY-NC-SA-4.0 DROP Short Answer 2000 1000 English CC-BY-SA-4.0 FRAMES Short Answer 550 274 English Apache-2.0 SimpleQA Short Answer 2000 1000 English MIT Table 3: Datasets Description showing the question types, sizes, languages, and licenses Four question types: Multiple choice, math, short answer, and classification questions, covering a range of formats and complexities. Various prompting strategies: The dataset includes responses generated using different prompt templates (0-shot vs. 5-shot, with/without Chain-of-Thought, with/without format restrictions). High-quality annotations: All samples underwent multiple rounds of annotation by both GPT-4o and human annotators to ensure label accuracy, with special attention to challenging cases. Data augmentation: To improve model robustness, the researchers employed data augmentation techniques to create diverse answer formats. Data augmentation strategies applied to enhance answer format diversity The final VAR dataset was partitioned into training, test, and generalization sets. The generalization set includes samples from datasets and models not seen during training to evalua

This is a Plain English Papers summary of a research paper called xVerify: Accurate, Efficient LLM Answer Verifier for Reasoning Model Evaluation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Rise of Reasoning Models and the Evaluation Challenge
As language models increasingly adopt "slow thinking" strategies inspired by OpenAI's o1 model, they produce longer, more complex responses. These outputs often include detailed reasoning steps, intermediate calculations, and self-reflection. This evolution creates significant evaluation challenges for existing methods, which struggle to extract final answers from lengthy reasoning traces and accurately determine whether they match reference answers.
Traditional evaluation approaches fall into two categories: rule-based frameworks and LLM-based judgment methods. Rule-based methods often fail to properly extract final answers and struggle with varied answer formats, while LLM judges are typically designed for subjective scoring rather than binary correctness judgments on objective questions.
Framework of xVerify showing the three-stage process from data collection to evaluation
To address these limitations, researchers introduce xVerify, an efficient answer verifier specifically designed for evaluating reasoning model responses on objective questions. Unlike existing methods, xVerify can process full model outputs to accurately identify final answers from complex reasoning traces and robustly check answer equivalence across different formats.
Formalizing the Evaluation Problem
The evaluation task is formalized as a 4-tuple (Q,R,Aref,E), where:
- Q represents the set of questions
- R contains the responses generated by an LLM
- Aref is the set of reference answers
- E is the evaluation function that determines correctness
For the answer extraction stage, given a response r to question q, the system identifies candidate answers A(r) and selects the final answer using a scoring function. For the equivalence comparison stage, the system needs to determine whether the extracted answer is equivalent to the reference answer.
This comparison must handle mathematical expressions, symbol conversions, and semantic matching to accommodate different but equivalent representations of the same answer. For example, "α" and "alpha" or "100" and "one hundred" should be recognized as equivalent.
Building the VAR Dataset
To train and evaluate xVerify, the researchers constructed the VAR (Verify Answer for Reasoning) dataset, which includes:
- Diverse LLM responses: Collected from 19 different LLMs (from 0.5B to 32B parameters) across 24 reasoning-focused datasets, with particular emphasis on recently released reasoning models like DeepSeek-R1-Distill series and QwQ-32B.
| Dataset | Type | #Train | #Test | Language | License |
|---|---|---|---|---|---|
| CMMLU | Choice | 2000 | 1000 | Chinese | CC-BY-NC-4.0 |
| C-Eval | Choice | 1346 | 260 | Chinese | CC-BY-NC-SA-4.0 |
| GPQA | Choice | 794 | 398 | English | CC-BY-4.0 |
| MMLU | Choice | 1816 | 1000 | English | MIT |
| MMLU-Pro | Choice | 2000 | 1000 | English | MIT |
| MMLU-Redux | Choice | 2000 | 1000 | English | CC-BY-4.0 |
| AgNews | Classification | 2000 | 1000 | English | Unspecified |
| Amazon | Classification | 2000 | 1000 | English | Apache-2.0 |
| CLUEWSC | Classification | 1548 | 1000 | Chinese | Unspecified |
| CMNLI | Classification | 2000 | 1000 | Chinese | Apache-2.0 |
| AMC23 | Math | 26 | 14 | English | Unspecified |
| AIME 2024 | Math | 20 | 10 | English | MIT |
| CMATH | Math | 1128 | 565 | Chinese | CC-BY-4.0 |
| GSM8K | Math | 2000 | 1000 | English | MIT |
| LiveMathBench | Math | 190 | 93 | English & Chinese | CC-BY-4.0 |
| MATH | Math | 2000 | 1000 | English | MIT |
| MGSM | Math | 1892 | 946 | Multilingual | CC-BY-SA-4.0 |
| OlympiadBench | Math | 1787 | 892 | English & Chinese | Apache-2.0 |
| ARC | Short Answer | 2000 | 1000 | English | CC-BY-SA-4.0 |
| CHID | Short Answer | 2000 | 1000 | Chinese | Apache-2.0 |
| C-SimpleQA | Short Answer | 2000 | 1000 | Chinese | CC-BY-NC-SA-4.0 |
| DROP | Short Answer | 2000 | 1000 | English | CC-BY-SA-4.0 |
| FRAMES | Short Answer | 550 | 274 | English | Apache-2.0 |
| SimpleQA | Short Answer | 2000 | 1000 | English | MIT |
Table 3: Datasets Description showing the question types, sizes, languages, and licenses
Four question types: Multiple choice, math, short answer, and classification questions, covering a range of formats and complexities.
Various prompting strategies: The dataset includes responses generated using different prompt templates (0-shot vs. 5-shot, with/without Chain-of-Thought, with/without format restrictions).
High-quality annotations: All samples underwent multiple rounds of annotation by both GPT-4o and human annotators to ensure label accuracy, with special attention to challenging cases.
Data augmentation: To improve model robustness, the researchers employed data augmentation techniques to create diverse answer formats.
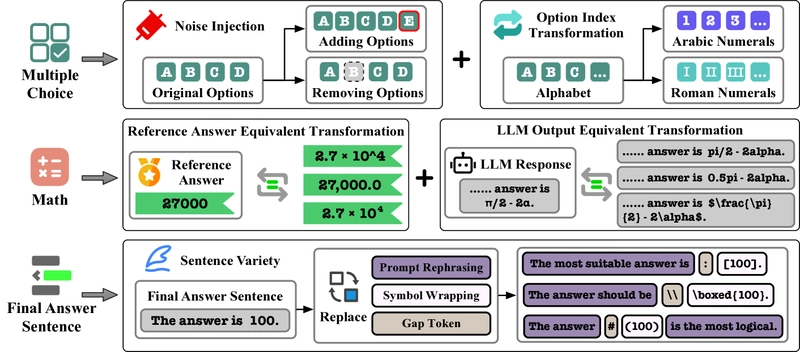
Data augmentation strategies applied to enhance answer format diversity
The final VAR dataset was partitioned into training, test, and generalization sets. The generalization set includes samples from datasets and models not seen during training to evaluate real-world performance.
Training the xVerify Models
Using the VAR dataset, the researchers trained 14 xVerify models with different parameter sizes (0.5B to 32B) and architectures. This diversity helped assess generalization capability across model families including LLaMA 3, Qwen2.5, and Gemma 2.
The training used the LLaMA-Factory framework and QLoRA technique, with hyperparameters optimized through experimentation. Training multiple model variants helped address potential bias, where judge models might favor outputs from the same model family.
Experimental Results: xVerify Outperforms Existing Methods
The evaluation compared xVerify against both rule-based evaluation frameworks (DeepSeek-Math, LM Eval Harness, Math-Verify, OpenAI Evals, OpenCompass, UltraEval) and LLM-based judge models (PandaLM, Auto-J, Prometheus, JudgeLM, CompassJudger, GPT-4o).
| Method Type | Method | Multiple Choice | Math | Short Answer | Classification | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | ||
| Evaluation Framework | DeepSeek Math Verify | 70.77% | 75.17% | 78.34% | 84.30% | - | - | - | - | 74.90% | 52.52% |
| LM Eval Harness | 58.44% | 68.19% | 25.16% | 28.27% | 53.41% | 44.51% | 72.35% | 66.94% | 47.67% | 48.32% | |
| Math-Verify | 5.88% | 53.76% | 82.55% | 86.70% | 42.27% | 71.91% | 0.00% | 29.66% | 45.64% | 65.91% | |
| OpenAI Simple Evals | 23.61% | 28.02% | 66.79% | 76.88% | 42.23% | 55.32% | 73.29% | 67.87% | 51.17% | 58.10% | |
| OpenCompass | 68.11% | 72.52% | 79.25% | 84.73% | - | - | - | - | 74.18% | 79.64% | |
| UltraEval | 17.34% | 18.04% | 8.88% | 56.89% | - | - | - | - | 13.95% | 40.71% | |
| Judge Model | PundaLM-7B-v1 | 4.26% | 8.12% | 16.78% | 14.46% | 23.47% | 17.72% | 25.32% | 16.79% | 16.40% | 13.72% |
| Auto-J-Bilingual-6B | 52.85% | 67.71% | 40.76% | 65.21% | 67.22% | 79.60% | 74.86% | 71.37% | 57.04% | 69.59% | |
| Auto-J-13B | 40.00% | 63.20% | 26.32% | 60.62% | 64.41% | 78.22% | 86.04% | 82.60% | 53.38% | 68.13% | |
| Prometheus-7B-v2.0 | 75.76% | 75.41% | 74.20% | 74.35% | 70.95% | 74.59% | 84.80% | 77.03% | 76.50% | 75.11% | |
| Prometheus-8x7B-v2.0 | 71.26% | 68.61% | 71.99% | 66.92% | 76.24% | 77.70% | 83.27% | 77.65% | 74.57% | 71.12% | |
| JudgeLM-7B-v1.0 | 56.53% | 42.57% | 46.09% | 34.58% | 60.33% | 50.56% | 83.89% | 73.22% | 59.02% | 45.90% | |
| JudgeLM-13B-v1.0 | 56.81% | 48.89% | 58.39% | 59.46% | 77.32% | 79.52% | 95.63% | 93.82% | 68.57% | 65.83% | |
| JudgeLM-33B-v1.0 | 42.86% | 43.24% | 44.82% | 46.03% | 57.86% | 62.23% | 73.42% | 67.56% | 52.00% | 51.75% | |
| CompassJudger-1-1.5B | 49.95% | 35.54% | 61.66% | 48.78% | 57.36% | 46.93% | 82.51% | 70.96% | 61.94% | 48.35% | |
| CompassJudger-1-7B | 70.05% | 62.78% | 66.62% | 58.86% | 67.47% | 65.08% | 92.99% | 89.50% | 72.72% | 65.96% | |
| CompassJudger-1-14B | 58.94% | 44.62% | 55.09% | 40.76% | 59.66% | 52.90% | 90.87% | 86.61% | 63.22% | 51.37% | |
| CompassJudger-1-32B | 95.09% | 95.37% | 84.11% | 84.30% | 94.95% | 96.11% | 98.45% | 97.84% | 91.67% | 91.69% | |
| GPT-4o as Judge | 96.61% | 96.75% | 95.27% | 95.80% | 95.01% | 96.20% | 98.14% | 97.43% | 96.25% | 96.39% | |
| GPT-4o as Judge (CoT) | 97.10% | 97.23% | 95.41% | 95.88% | 95.63% | 96.63% | 99.56% | 99.38% | 96.85% | 96.95% | |
| xVerify | xVerify-0.5B-I | 97.78% | 97.90% | 93.74% | 94.64% | 96.72% | 97.49% | 99.71% | 99.59% | 96.69% | 96.85% |
| xVerify-3B-Ib | 97.31% | 97.41% | 95.65% | 96.18% | 96.38% | 97.23% | 99.78% | 99.69% | 97.17% | 97.27% | |
| xVerify-7B-I | 97.75% | 97.84% | 95.94% | 96.44% | 96.51% | 97.32% | 99.78% | 99.69% | 97.41% | 97.50% | |
| xVerify-9B-I | 97.43% | 97.53% | 95.75% | 96.27% | 96.06% | 96.97% | 99.78% | 99.69% | 97.19% | 97.29% | |
| xVerify-14B-Ia | 97.49% | 97.59% | 95.73% | 96.22% | 95.41% | 96.46% | 99.63% | 99.49% | 97.06% | 97.16% | |
| xVerify-32B-I | 97.81% | 97.90% | 95.88% | 96.31% | 96.18% | 97.06% | 99.71% | 99.59% | 97.32% | 97.40% |
Table 1: Evaluation Accuracy Results on the Test Set, showing xVerify's superior performance across all question types
The results show that:
xVerify outperforms all baselines: Even the smallest xVerify model (0.5B parameters) surpasses all evaluation frameworks and most judge models, achieving overall F1 scores and accuracy exceeding 96.5% on the test set. This demonstrates the effectiveness of the targeted training approach and the quality of the VAR dataset.
Strong generalization ability: On the more challenging generalization set with unseen datasets and models, xVerify maintains high performance with F1 scores and accuracy above 95.5%, showing minimal performance drop compared to the test set.
| Method Type | Method | Multiple Choice | Math | Short Answer | Classification | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | ||
| Evaluation Framework | DeepSeek Math Verify | 72.90% | 73.39% | 11.69% | 79.83% | - | - | - | - | 60.57% | 44.42% |
| LM Eval Harness | 61.60% | 65.37% | 7.03% | 18.48% | 58.22% | 45.09% | 92.06% | 88.21% | 55.81% | 51.30% | |
| Math-Verify | 5.19% | 45.10% | 64.18% | 87.68% | 9.12% | 52.75% | 0.00% | 24.59% | 16.10% | 55.53% | |
| OpenAI Simple Evals | 28.72% | 29.23% | 24.31% | 78.90% | 58.33% | 59.58% | 94.39% | 91.62% | 57.99% | 63.36% | |
| OpenCompass | 71.64% | 71.44% | 47.22% | 84.39% | - | - | - | - | 65.74% | 78.18% | |
| UltraEval | 16.29% | 15.31% | 13.55% | 78.39% | - | - | - | - | 15.71% | 48.13% | |
| Judge Model | PandaLM-7B-v1 | 4.28% | 7.85% | 9.91% | 15.97% | 45.81% | 31.43% | 36.23% | 25.99% | 23.74% | 19.14% |
| Auto-J-Bilingual-6B | 52.07% | 60.75% | 10.56% | 74.79% | 85.16% | 86.76% | 84.90% | 79.91% | 67.20% | 74.57% | |
| Auto-J-13B | 34.87% | 52.78% | 9.86% | 76.54% | 85.12% | 86.97% | 77.67% | 71.99% | 60.43% | 71.35% | |
| Prometheus-7B-v2.0 | 76.67% | 73.66% | 49.08% | 71.46% | 81.52% | 81.32% | 79.59% | 71.92% | 73.85% | 74.35% | |
| Prometheus-8x7B-v2.0 | 74.13% | 68.60% | 49.48% | 60.27% | 87.15% | 86.13% | 84.70% | 77.19% | 74.51% | 71.69% | |
| JudgeLM-7B-v1.0 | 60.22% | 45.71% | 12.71% | 15.40% | 72.15% | 62.51% | 86.11% | 76.18% | 59.11% | 46.38% | |
| JudgeLM-13B-v1.0 | 65.39% | 57.80% | 21.61% | 44.87% | 86.11% | 84.53% | 91.78% | 86.89% | 69.18% | 65.63% | |
| JudgeLM-33B-v1.0 | 46.99% | 45.10% | 20.31% | 39.99% | 71.34% | 66.69% | 41.92% | 33.36% | 46.06% | 46.01% | |
| CompassJudger-1-1.5B | 55.75% | 40.87% | 34.53% | 33.62% | 63.93% | 51.57% | 84.49% | 73.93% | 60.01% | 47.65% | |
| CompassJudger-1-7B | 74.31% | 65.20% | 38.27% | 39.89% | 88.99% | 88.15% | 93.29% | 89.29% | 73.47% | 67.47% | |
| CompassJudger-1-14B | 63.65% | 49.50% | 27.63% | 21.20% | 73.61% | 66.48% | 88.97% | 81.92% | 63.10% | 51.21% | |
| CompassJudger-1-32B | 92.93% | 92.32% | 72.05% | 84.91% | 96.81% | 96.86% | 98.05% | 97.05% | 91.90% | 92.04% | |
| GPT-4o as Judge | 95.86% | 95.38% | 87.91% | 94.76% | 97.46% | 97.49% | 98.67% | 97.98% | 96.03% | 96.18% | |
| GPT-4o as Judge (CoT) | 95.44% | 94.88% | 88.34% | 94.71% | 97.39% | 97.42% | 98.36% | 97.52% | 95.79% | 95.92% | |
| xVerify | xVerify-0.5B-I | 96.49% | 96.10% | 80.00% | 91.94% | 96.95% | 97.00% | 99.03% | 98.53% | 95.29% | 95.53% |
| xVerify-3B-Ib | 96.21% | 95.71% | 86.20% | 94.15% | 97.68% | 97.63% | 99.03% | 98.53% | 96.08% | 96.23% | |
| xVerify-7B-I | 96.16% | 95.66% | 87.86% | 94.87% | 97.45% | 97.49% | 98.93% | 98.37% | 96.22% | 96.37% | |
| xVerify-9B-I | 96.06% | 95.55% | 87.47% | 94.76% | 97.53% | 97.56% | 99.13% | 98.68% | 96.23% | 96.38% | |
| xVerify-14B-Ia | 96.11% | 95.60% | 90.20% | 95.74% | 97.32% | 97.35% | 99.13% | 98.68% | 96.53% | 96.65% | |
| xVerify-32B-I | 96.22% | 95.71% | 90.09% | 95.59% | 97.32% | 97.35% | 99.03% | 98.53% | 96.50% | 96.60% |
Table 2: Evaluation Accuracy Results on the Generalization Set, demonstrating xVerify's robust performance on unseen distribution
Computational efficiency: xVerify models run significantly faster than other judge models, with average evaluation times under 100 seconds for 200 samples, compared to over 100 seconds for other judge models. This makes xVerify more practical for large-scale evaluations.
Cost-effectiveness: Compared to using GPT-4o as an evaluation judge, locally deployed xVerify models offer substantial cost savings while maintaining comparable or better accuracy.
These results demonstrate that focused training on a high-quality dataset enables even small parameter models to excel at specialized tasks like answer verification for reasoning models. This finding aligns with research like VerifiAgent and Not All Votes Count, which explore targeted verification approaches.
Conclusion
xVerify represents a significant advancement in evaluating reasoning model outputs on objective questions. By combining innovative data collection and annotation methods with targeted training, the researchers created an efficient verifier that outperforms both rule-based frameworks and general-purpose judge models.
Key contributions include:
The VAR dataset, containing diverse responses from 19 LLMs across 24 evaluation benchmarks, with high-quality annotations from multiple GPT-4o and human review rounds.
The xVerify model family, with variants ranging from 0.5B to 32B parameters, all achieving strong performance across different question types.
Comprehensive evaluation showing xVerify's superiority in accuracy, generalization ability, computational efficiency, and cost-effectiveness.
As reasoning models continue to evolve and generate increasingly complex outputs, specialized evaluation tools like xVerify will be crucial for accurate assessment. This work provides both an immediately useful tool and a methodology for developing similar specialized verifiers for other complex LLM evaluation tasks.
The approach taken in xVerify could be extended to other domains requiring specialized verification, as explored in the VERIFY benchmark for multimodal reasoning evaluation.




