

































































What the Hash?! Understanding the Basics of Hashing
Hashing is an important concept that helps us organize and manage data more efficiently. It's like a shortcut to finding things quickly! Whether it's for quickly looking up data in hash tables or storing passwords securely, hashing makes sure we can access data quickly and consistently. In this article, we’ll explore what hashing is, how it works, and the key components behind it. What is Hashing? Hashing is a technique used to convert a given input—such as a string, number, or file—into a unique value, often in the form of a hash code. Hashing for Utility vs. Security It's also important to know that not all hashing algorithms are built for the same job. Some are designed just to help organize and retrieve data quickly—like the ones used in hash tables or dictionaries. These are great when you need fast lookups and don’t care much about security. On the other hand, algorithms like SHA-256 or MD5 are made for security purposes. They’re used when you want to protect sensitive data, like storing passwords or verifying file integrity. So basically, if you're building something like a login system, you'd use a secure hash like SHA-256. But if you're just mapping keys to values in a hash table, a simple and fast hash function is all you need. How Hashing Makes Data Lookup Fast In data structures like hash tables, which store key/value pairs, each piece of data is stored in an array-like structure, and the hashing process helps determine the specific location where each element will go. When you want to find or update a value, hashing makes it quick and efficient because it allows for constant-time lookups. Rather than searching through the entire dataset, hashing quickly identifies the location of the data by generating a unique hash code for each key. This unique code is then used as an index to access the corresponding value. This method is especially useful for large datasets, as it ensures that lookups, insertions, and deletions happen in nearly constant time, regardless of the size of the data. Components of Hashing Keys A key can be any piece of data, such as a string, number, or file, which is input into the hash function. This key is used to determine where the data will be stored in a hash table. Hash function We use the hash function to take an input key and generate a unique index, known as the hash index, where the corresponding data will be stored. It converts the key into an index in the hash table, making it easier to locate and retrieve the data efficiently. Hash table A hash table is a data structure that stores data by mapping keys to values with the help of a hash function. It organizes the data inside an array, where each value is placed at a specific index generated from its key, making it easy to access the data later. What is Hash Collision A hash collision happens when two different keys are assigned the same index in a hash table. This occurs because the hash function, which calculates where each item should go, might occasionally produce the same result for different inputs. It's like two people accidentally having the same house number on the same street. To handle collisions, hash tables use techniques like placing both items at the same index using a list (chaining), or finding another nearby spot for one of them (open addressing). These methods help ensure that even when collisions happen, the data remains accessible and the system continues to work without any issues. What Are Hashing Algorithms? Basically, a hash algorithm is just a set process that takes any kind of input—like a bit of text, a number, or even a whole file—and turns it into a fixed-length string that looks totally random. Regardless of the size of the input, the resulting hash always has a fixed length. And if you give it the same input again, you’ll always get the exact same hash back. Over the years, plenty of different hashing algorithms have been created—each with its own way of working, along with its pros and cons depending on where it's used. MD5, SHA, and CRC32 are some of the most popular algorithms used nowadays. MD5 (Message Digest 5) MD5 was widely used in the past but now it is considered insecure because it can cause collisions (two different inputs giving the same hash). It’s still used for tasks like checking file integrity but not for sensitive data. import hashlib def md5_hash(text): text_bytes = text.encode('utf-8') hash_object = hashlib.md5(text_bytes) return hash_object.hexdigest() user_input = input("Enter text to hash using MD5: ") hashed = md5_hash(user_input) print(f"MD5 hash of '{user_input}': {hashed}") Output: This is a hash function that uses the MD5 algorithm from Python's hashlib module. MD5 produces a 32-character hexadecimal string. It's fast but not secure for cryptographic use. SHA (Secure Hash Algorithm) SHA refe
Hashing is an important concept that helps us organize and manage data more efficiently. It's like a shortcut to finding things quickly!
Whether it's for quickly looking up data in hash tables or storing passwords securely, hashing makes sure we can access data quickly and consistently.
In this article, we’ll explore what hashing is, how it works, and the key components behind it.
What is Hashing?
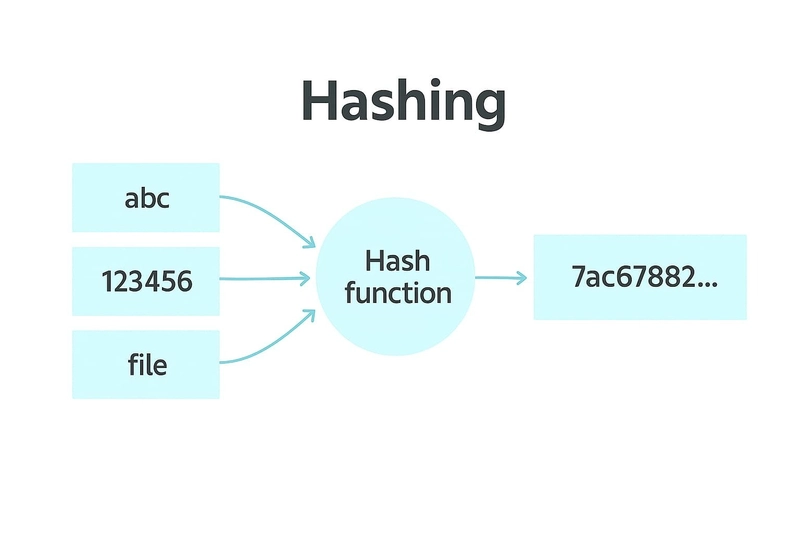
Hashing is a technique used to convert a given input—such as a string, number, or file—into a unique value, often in the form of a hash code.
Hashing for Utility vs. Security
It's also important to know that not all hashing algorithms are built for the same job. Some are designed just to help organize and retrieve data quickly—like the ones used in hash tables or dictionaries.
These are great when you need fast lookups and don’t care much about security. On the other hand, algorithms like SHA-256 or MD5 are made for security purposes. They’re used when you want to protect sensitive data, like storing passwords or verifying file integrity.
So basically, if you're building something like a login system, you'd use a secure hash like SHA-256. But if you're just mapping keys to values in a hash table, a simple and fast hash function is all you need.
How Hashing Makes Data Lookup Fast
In data structures like hash tables, which store key/value pairs, each piece of data is stored in an array-like structure, and the hashing process helps determine the specific location where each element will go.
When you want to find or update a value, hashing makes it quick and efficient because it allows for constant-time lookups. Rather than searching through the entire dataset, hashing quickly identifies the location of the data by generating a unique hash code for each key. This unique code is then used as an index to access the corresponding value.
This method is especially useful for large datasets, as it ensures that lookups, insertions, and deletions happen in nearly constant time, regardless of the size of the data.
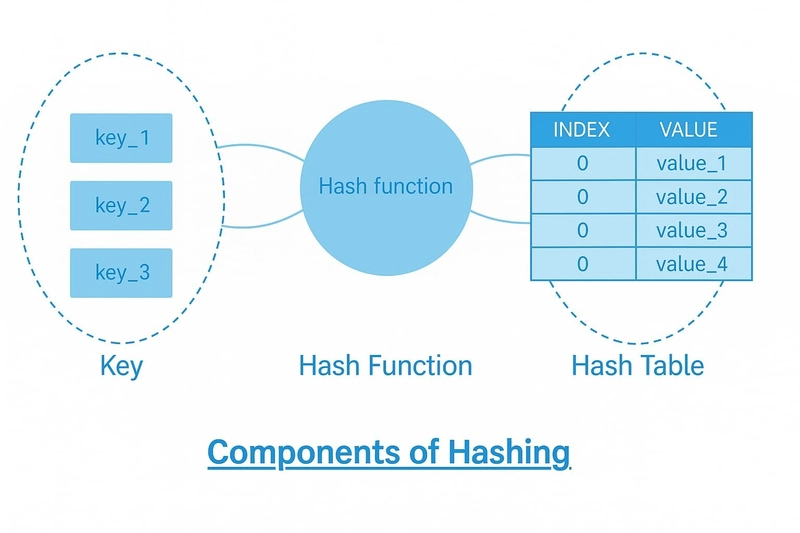
Components of Hashing
Keys
A key can be any piece of data, such as a string, number, or file, which is input into the hash function. This key is used to determine where the data will be stored in a hash table.
Hash function
We use the hash function to take an input key and generate a unique index, known as the hash index, where the corresponding data will be stored.
It converts the key into an index in the hash table, making it easier to locate and retrieve the data efficiently.
Hash table
A hash table is a data structure that stores data by mapping keys to values with the help of a hash function. It organizes the data inside an array, where each value is placed at a specific index generated from its key, making it easy to access the data later.
What is Hash Collision
A hash collision happens when two different keys are assigned the same index in a hash table. This occurs because the hash function, which calculates where each item should go, might occasionally produce the same result for different inputs.
It's like two people accidentally having the same house number on the same street.
To handle collisions, hash tables use techniques like placing both items at the same index using a list (chaining), or finding another nearby spot for one of them (open addressing).
These methods help ensure that even when collisions happen, the data remains accessible and the system continues to work without any issues.
What Are Hashing Algorithms?
Basically, a hash algorithm is just a set process that takes any kind of input—like a bit of text, a number, or even a whole file—and turns it into a fixed-length string that looks totally random.
Regardless of the size of the input, the resulting hash always has a fixed length. And if you give it the same input again, you’ll always get the exact same hash back.

Over the years, plenty of different hashing algorithms have been created—each with its own way of working, along with its pros and cons depending on where it's used.
MD5, SHA, and CRC32 are some of the most popular algorithms used nowadays.
MD5 (Message Digest 5)
MD5 was widely used in the past but now it is considered insecure because it can cause collisions (two different inputs giving the same hash).
It’s still used for tasks like checking file integrity but not for sensitive data.
import hashlib
def md5_hash(text):
text_bytes = text.encode('utf-8')
hash_object = hashlib.md5(text_bytes)
return hash_object.hexdigest()
user_input = input("Enter text to hash using MD5: ")
hashed = md5_hash(user_input)
print(f"MD5 hash of '{user_input}': {hashed}")
Output:

This is a hash function that uses the MD5 algorithm from Python's hashlib module.
MD5 produces a 32-character hexadecimal string. It's fast but not secure for cryptographic use.
SHA (Secure Hash Algorithm)
SHA refers to a group of hashing algorithms, with SHA-2 being the most common these days.
It’s trusted for securing private data and is used in applications like blockchain and digital certificates.
import hashlib
def sha256_hash(text):
text_bytes = text.encode('utf-8')
hash_object = hashlib.sha256(text_bytes)
return hash_object.hexdigest()
user_input = input("Enter text to hash using SHA-256: ")
hashed = sha256_hash(user_input)
print(f"SHA-256 hash of '{user_input}': {hashed}")
Output:

In this example, we're using Python's built-in 'hashlib' module
to create a SHA-256 hash of a string entered by the user.
HA-256 produces a 256-bit (32-byte) hash value, represented as a 64-character hexadecimal string.
CRC32 (Cyclic Redundancy Check)
CRC32 is mainly used for error checking—like making sure files haven’t been corrupted during download.
It’s quick and easy but not strong enough to protect sensitive data.
import zlib
def crc32_hash(text):
text_bytes = text.encode('utf-8')
crc = zlib.crc32(text_bytes)
return format(crc & 0xFFFFFFFF, '08x')
user_input = input("Enter text to hash using CRC32: ")
hashed = crc32_hash(user_input)
print(f"CRC32 hash of '{user_input}': {hashed}")
Output:

This function computes the CRC32 checksum of a given input string.
CRC32 is used for error-checking, not for cryptographic purposes.
It returns a 32-bit unsigned integer value.
Why Hashing is More Efficient
Arrays are commonly used to store data and allow fast access by index in O(1) time. However, searching for a specific value—when the index is unknown—takes O(n) time in an unsorted array.
To address this inefficiency, we use hashing. Hashing enables key-based access in O(1) average time by applying a hash function to the key, which maps it to a specific position in a hash table.
Conclusion
Hashing is a simple but useful technique that helps us store and secure data efficiently.
There are different algorithms depending on what you need, but the core idea stays the same: take some data and turn it into a unique, fixed-size value that’s quick to work with.
Understanding how hashing works gives us a better idea of what’s happening behind the scenes in apps, websites, and systems we use every day.






