


































































Understanding Data Pipelines: A Comprehensive Guide
Introduction In the digital age, businesses generate vast amounts of data daily. However, raw data alone is not useful until it is processed, analyzed, and turned into meaningful insights. This is where data pipelines come into play. A data pipeline is a system that collects, processes, and transforms data from various sources into a usable format. This article provides a structured overview of data pipelines, covering their components, types, processing methods, and significance in data-driven decision-making. 1. What is a Data Pipeline? A data pipeline is a series of processes that automate the movement and transformation of data from multiple sources to a destination, such as a data warehouse, analytics tool, or business intelligence system. It ensures data flows efficiently, reliably, and in a structured manner to support analytics, reporting, and machine learning applications. Key Functions of a Data Pipeline: ✅ Data Collection: Gathering data from various sources like databases, APIs, and real-time streaming platforms. ✅ Data Processing: Cleaning, transforming, and enriching data to ensure quality. ✅ Data Storage: Storing processed data in a structured format, either in data lakes (for raw data) or data warehouses (for structured data). ✅ Data Analysis & Visualization: Using Business Intelligence (BI) tools to generate reports and dashboards. 2. Components of a Data Pipeline A well-designed data pipeline consists of the following key components: 2.1 Data Sources The first step in any data pipeline is collecting data from various sources, including: Databases (e.g., MySQL, PostgreSQL, MongoDB) APIs (e.g., RESTful APIs for third-party integrations) Streaming Platforms (e.g., Kafka, Apache Flink, AWS Kinesis) Flat Files & Logs (e.g., CSV, JSON, log files) 2.2 Data Ingestion Data ingestion refers to moving data from sources into the pipeline. There are two main types: Batch Ingestion – Extracts and loads data at scheduled intervals. Real-Time Streaming – Processes data as it arrives (e.g., stock market feeds, IoT sensors). 2.3 Data Processing & Transformation Once data enters the pipeline, it needs cleaning, validation, and structuring. Processing techniques include: Data Cleaning: Removing duplicates, handling missing values, and standardizing formats. Data Transformation: Converting data into a usable structure (e.g., JSON to a relational table). Aggregation: Summarizing data (e.g., calculating total sales per region). 2.4 Data Storage Processed data needs to be stored securely for further analysis. Common storage solutions include: Data Lakes: Store raw, unstructured data (e.g., AWS S3, Azure Data Lake). Data Warehouses: Store structured, cleaned data for analytical processing (e.g., Snowflake, Google BigQuery). 2.5 Data Analysis & Visualization The final step involves extracting insights from processed data using: Machine Learning & AI – Applying algorithms to predict trends. Business Intelligence (BI) Tools – Generating reports and dashboards (e.g., Tableau, Power BI). Self-Service Analytics – Enabling users to explore data without technical expertise. 3. Types of Data Pipelines There are different types of data pipelines designed for various business needs: 3.1 ETL (Extract, Transform, Load) Pipelines Extracts data from sources → Transforms it into a structured format → Loads it into a warehouse. Used in batch processing for reporting and analytics. 3.2 ELT (Extract, Load, Transform) Pipelines Loads raw data into a warehouse first → Transforms it later. Used when storage is cheap, and processing happens on demand. 3.3 Streaming Data Pipelines Processes data in real-time using frameworks like Apache Flink or Spark Streaming. Used in fraud detection, monitoring systems, and IoT applications. 4. Why Are Data Pipelines Important? Data pipelines enhance business operations and decision-making by: ✅ Automating Data Flow: Reducing manual effort in handling data. ✅ Ensuring Data Consistency & Quality: Standardizing and cleaning data before analysis. ✅ Enabling Real-Time Insights: Supporting fast decision-making with streaming data. ✅ Optimizing Machine Learning Workflows: Providing clean, structured data for AI models. 5. Challenges in Building Data Pipelines Despite their benefits, data pipelines face several challenges: ⚠️ Scalability Issues: Handling large volumes of data efficiently. ⚠️ Data Quality Problems: Ensuring data is accurate, consistent, and complete. ⚠️ Latency in Processing: Reducing delays in data delivery. ⚠️ Integration Complexity: Managing multiple data sources and tools. 6. Future Trends in Data Pipelines
Introduction
In the digital age, businesses generate vast amounts of data daily. However, raw data alone is not useful until it is processed, analyzed, and turned into meaningful insights. This is where data pipelines come into play. A data pipeline is a system that collects, processes, and transforms data from various sources into a usable format.
This article provides a structured overview of data pipelines, covering their components, types, processing methods, and significance in data-driven decision-making.
1. What is a Data Pipeline?
A data pipeline is a series of processes that automate the movement and transformation of data from multiple sources to a destination, such as a data warehouse, analytics tool, or business intelligence system. It ensures data flows efficiently, reliably, and in a structured manner to support analytics, reporting, and machine learning applications.
Key Functions of a Data Pipeline:
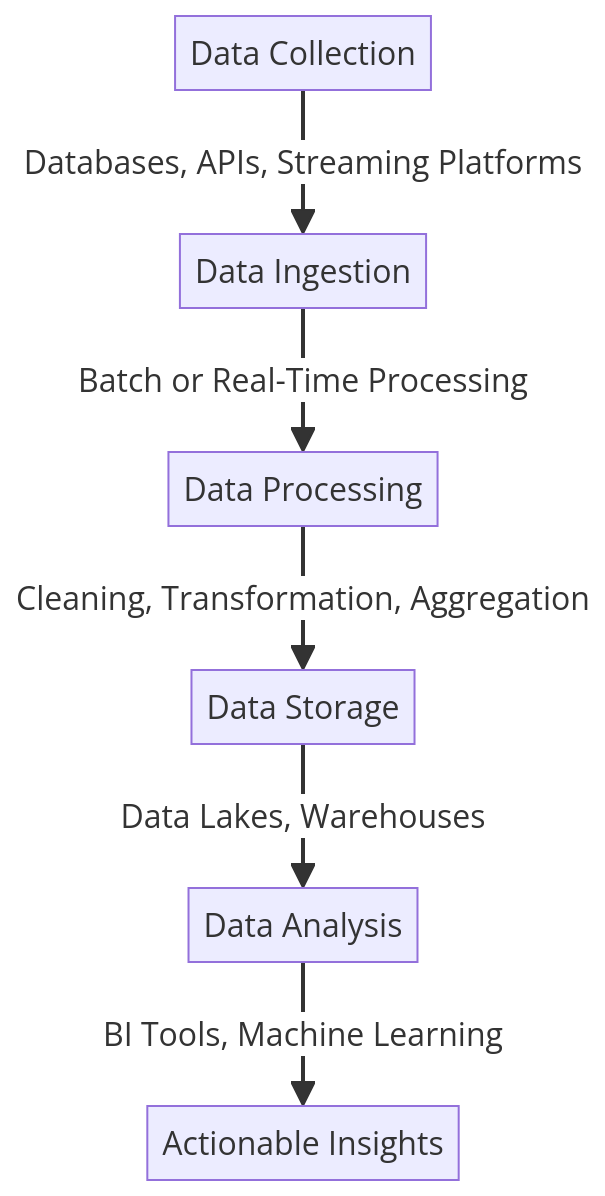
✅ Data Collection: Gathering data from various sources like databases, APIs, and real-time streaming platforms.
✅ Data Processing: Cleaning, transforming, and enriching data to ensure quality.
✅ Data Storage: Storing processed data in a structured format, either in data lakes (for raw data) or data warehouses (for structured data).
✅ Data Analysis & Visualization: Using Business Intelligence (BI) tools to generate reports and dashboards.
2. Components of a Data Pipeline
A well-designed data pipeline consists of the following key components:
2.1 Data Sources
The first step in any data pipeline is collecting data from various sources, including:
- Databases (e.g., MySQL, PostgreSQL, MongoDB)
- APIs (e.g., RESTful APIs for third-party integrations)
- Streaming Platforms (e.g., Kafka, Apache Flink, AWS Kinesis)
- Flat Files & Logs (e.g., CSV, JSON, log files)
2.2 Data Ingestion
Data ingestion refers to moving data from sources into the pipeline. There are two main types:
- Batch Ingestion – Extracts and loads data at scheduled intervals.
- Real-Time Streaming – Processes data as it arrives (e.g., stock market feeds, IoT sensors).
2.3 Data Processing & Transformation
Once data enters the pipeline, it needs cleaning, validation, and structuring. Processing techniques include:
- Data Cleaning: Removing duplicates, handling missing values, and standardizing formats.
- Data Transformation: Converting data into a usable structure (e.g., JSON to a relational table).
- Aggregation: Summarizing data (e.g., calculating total sales per region).
2.4 Data Storage
Processed data needs to be stored securely for further analysis. Common storage solutions include:
- Data Lakes: Store raw, unstructured data (e.g., AWS S3, Azure Data Lake).
- Data Warehouses: Store structured, cleaned data for analytical processing (e.g., Snowflake, Google BigQuery).
2.5 Data Analysis & Visualization
The final step involves extracting insights from processed data using:
- Machine Learning & AI – Applying algorithms to predict trends.
- Business Intelligence (BI) Tools – Generating reports and dashboards (e.g., Tableau, Power BI).
- Self-Service Analytics – Enabling users to explore data without technical expertise.
3. Types of Data Pipelines
There are different types of data pipelines designed for various business needs:
3.1 ETL (Extract, Transform, Load) Pipelines
- Extracts data from sources → Transforms it into a structured format → Loads it into a warehouse.
- Used in batch processing for reporting and analytics.
3.2 ELT (Extract, Load, Transform) Pipelines
- Loads raw data into a warehouse first → Transforms it later.
- Used when storage is cheap, and processing happens on demand.
3.3 Streaming Data Pipelines
- Processes data in real-time using frameworks like Apache Flink or Spark Streaming.
- Used in fraud detection, monitoring systems, and IoT applications.
4. Why Are Data Pipelines Important?
Data pipelines enhance business operations and decision-making by:
✅ Automating Data Flow: Reducing manual effort in handling data.
✅ Ensuring Data Consistency & Quality: Standardizing and cleaning data before analysis.
✅ Enabling Real-Time Insights: Supporting fast decision-making with streaming data.
✅ Optimizing Machine Learning Workflows: Providing clean, structured data for AI models.
5. Challenges in Building Data Pipelines
Despite their benefits, data pipelines face several challenges:
⚠️ Scalability Issues: Handling large volumes of data efficiently.
⚠️ Data Quality Problems: Ensuring data is accurate, consistent, and complete.
⚠️ Latency in Processing: Reducing delays in data delivery.
⚠️ Integration Complexity: Managing multiple data sources and tools.
6. Future Trends in Data Pipelines









