







![Parents Threatened To Email A Business Partner And Get Them To Stop Working With Me [closed]](https://cdn.sstatic.net/Sites/workplace/Img/apple-touch-icon@2.png?v=d39b333f5c58)



![[Tutorial] Chapter 4: Task and Comment Plugins](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Ffl10oejjhn82dwrsm2n2.png)






_Porntep_Lueangon_Alamy.jpg?#)



















































The Complete Machine Learning Pipeline: From Data to Deployment
Machine Learning (ML) is revolutionizing industries by enabling automated decision-making, predictive analytics, and intelligent automation. However, building a successful ML model isn’t just about training an algorithm—it requires a structured pipeline that takes data from raw collection to real-world deployment. In this blog, we’ll walk through the end-to-end Machine Learning pipeline, covering each stage and its significance. 1. Data Collection The foundation of any ML project is data. Without high-quality data, even the most sophisticated model will fail. Data can be gathered from various sources: Databases: SQL, NoSQL, cloud storage solutions like AWS S3, Google Cloud Storage. APIs: Twitter API, Google Maps API, financial market data from Alpha Vantage. Files: CSV, JSON, Excel, Parquet. Web Scraping: BeautifulSoup, Scrapy for extracting information from websites. IoT Devices & Sensors: Smart devices, industrial sensors, fitness trackers. Public Datasets: Kaggle, UCI Machine Learning Repository, Google Dataset Search. Key Considerations: Ensure data is relevant to the problem. Maintain data integrity and avoid bias. Store data securely following privacy regulations (GDPR, HIPAA). 2. Data Preprocessing & Cleaning Raw data is often messy and requires cleaning before feeding it into an ML model. Common preprocessing steps include: Handling missing values: Imputation (mean, median, mode), deletion, or using predictive models. Removing duplicates and outliers: Use statistical methods like Z-score or IQR. Standardizing data formats: Converting dates to a standard format, normalizing text. Encoding categorical variables: One-hot encoding, label encoding. Feature scaling: Normalization (MinMaxScaler) or Standardization (StandardScaler). Popular Tools: Pandas & NumPy: Data manipulation and numerical computation. OpenCV: Image processing. NLTK & spaCy: Natural language preprocessing. 3. Feature Engineering Feature engineering is the process of transforming raw data into meaningful features that improve model performance. Techniques include: Feature selection: Choosing relevant variables using methods like Recursive Feature Elimination (RFE). Feature transformation: Applying logarithmic transformations, polynomial features, and binning. Feature extraction: Techniques like Principal Component Analysis (PCA), TF-IDF for text data. Feature creation: Aggregating data, domain-specific transformations, lag features for time series. Popular Tools: Scikit-learn: Feature selection and transformation. Featuretools: Automated feature engineering. TensorFlow Transform: Feature preprocessing for deep learning models. 4. Data Splitting Before training a model, the dataset needs to be split into different subsets: Training Set: Used to train the model (~70-80% of the data). Validation Set: Used for tuning hyperparameters (~10-15%). Test Set: Used for final evaluation (~10-15%). Stratified sampling is recommended for classification problems to maintain class distribution. Common Methods: train_test_split from Scikit-learn. Cross-validation techniques like k-fold cross-validation. 5. Model Selection Choosing the right algorithm depends on the type of ML problem: Regression: Linear Regression, Decision Trees, XGBoost, LightGBM. Classification: Logistic Regression, Random Forest, SVM, Deep Learning. Clustering: K-Means, DBSCAN, Hierarchical Clustering. Deep Learning: CNNs for images, RNNs for sequential data, Transformers for NLP. Frameworks: TensorFlow & PyTorch: Deep learning. Scikit-learn: Traditional ML models. XGBoost & LightGBM: Gradient boosting models. 6. Model Training Once an algorithm is selected, it is trained using the dataset: Batch training vs. Mini-batch gradient descent for deep learning models. Early stopping to prevent overfitting. Regularization techniques: L1 (Lasso), L2 (Ridge), Dropout. Transfer learning for pre-trained deep learning models. Key Considerations: Monitor loss functions and convergence. Utilize GPU acceleration for deep learning. 7. Model Evaluation A trained model is only useful if it performs well on unseen data. Performance is measured using: Regression Metrics: RMSE, MAE, R². Classification Metrics: Accuracy, Precision, Recall, F1-score, AUC-ROC. Clustering Metrics: Silhouette Score, Davies-Bouldin Index. Tools: Scikit-learn's metrics module. TensorFlow Model Analysis. 8. Hyperparameter Tuning Fine-tuning model parameters can significantly improve performance. Methods include: Grid Search: Exhaustive search over a parameter grid. Random Search: Randomly selecting hyperparameters. Bayesian Optimization: Probabilistic search using Gaussian Processes. Genetic Algorithms: Evolution-based tuning. Tools:
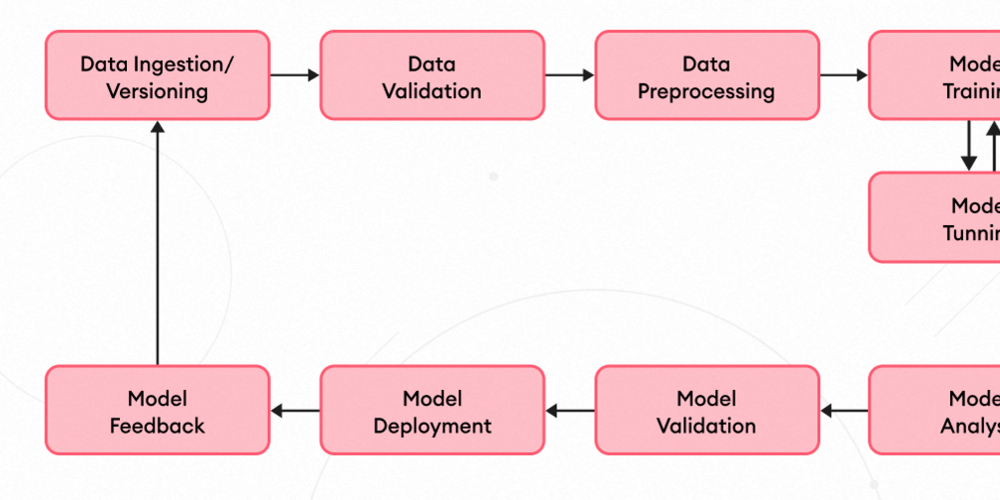
Machine Learning (ML) is revolutionizing industries by enabling automated decision-making, predictive analytics, and intelligent automation. However, building a successful ML model isn’t just about training an algorithm—it requires a structured pipeline that takes data from raw collection to real-world deployment.
In this blog, we’ll walk through the end-to-end Machine Learning pipeline, covering each stage and its significance.
1. Data Collection
The foundation of any ML project is data. Without high-quality data, even the most sophisticated model will fail. Data can be gathered from various sources:
- Databases: SQL, NoSQL, cloud storage solutions like AWS S3, Google Cloud Storage.
- APIs: Twitter API, Google Maps API, financial market data from Alpha Vantage.
- Files: CSV, JSON, Excel, Parquet.
- Web Scraping: BeautifulSoup, Scrapy for extracting information from websites.
- IoT Devices & Sensors: Smart devices, industrial sensors, fitness trackers.
- Public Datasets: Kaggle, UCI Machine Learning Repository, Google Dataset Search.
Key Considerations:
- Ensure data is relevant to the problem.
- Maintain data integrity and avoid bias.
- Store data securely following privacy regulations (GDPR, HIPAA).
2. Data Preprocessing & Cleaning
Raw data is often messy and requires cleaning before feeding it into an ML model. Common preprocessing steps include:
- Handling missing values: Imputation (mean, median, mode), deletion, or using predictive models.
- Removing duplicates and outliers: Use statistical methods like Z-score or IQR.
- Standardizing data formats: Converting dates to a standard format, normalizing text.
- Encoding categorical variables: One-hot encoding, label encoding.
- Feature scaling: Normalization (MinMaxScaler) or Standardization (StandardScaler).
Popular Tools:
- Pandas & NumPy: Data manipulation and numerical computation.
- OpenCV: Image processing.
- NLTK & spaCy: Natural language preprocessing.
3. Feature Engineering
Feature engineering is the process of transforming raw data into meaningful features that improve model performance. Techniques include:
- Feature selection: Choosing relevant variables using methods like Recursive Feature Elimination (RFE).
- Feature transformation: Applying logarithmic transformations, polynomial features, and binning.
- Feature extraction: Techniques like Principal Component Analysis (PCA), TF-IDF for text data.
- Feature creation: Aggregating data, domain-specific transformations, lag features for time series.
Popular Tools:
- Scikit-learn: Feature selection and transformation.
- Featuretools: Automated feature engineering.
- TensorFlow Transform: Feature preprocessing for deep learning models.
4. Data Splitting
Before training a model, the dataset needs to be split into different subsets:
- Training Set: Used to train the model (~70-80% of the data).
- Validation Set: Used for tuning hyperparameters (~10-15%).
- Test Set: Used for final evaluation (~10-15%).
Stratified sampling is recommended for classification problems to maintain class distribution.
Common Methods:
-
train_test_splitfrom Scikit-learn. - Cross-validation techniques like k-fold cross-validation.
5. Model Selection
Choosing the right algorithm depends on the type of ML problem:
- Regression: Linear Regression, Decision Trees, XGBoost, LightGBM.
- Classification: Logistic Regression, Random Forest, SVM, Deep Learning.
- Clustering: K-Means, DBSCAN, Hierarchical Clustering.
- Deep Learning: CNNs for images, RNNs for sequential data, Transformers for NLP.
Frameworks:
- TensorFlow & PyTorch: Deep learning.
- Scikit-learn: Traditional ML models.
- XGBoost & LightGBM: Gradient boosting models.
6. Model Training
Once an algorithm is selected, it is trained using the dataset:
- Batch training vs. Mini-batch gradient descent for deep learning models.
- Early stopping to prevent overfitting.
- Regularization techniques: L1 (Lasso), L2 (Ridge), Dropout.
- Transfer learning for pre-trained deep learning models.
Key Considerations:
- Monitor loss functions and convergence.
- Utilize GPU acceleration for deep learning.
7. Model Evaluation
A trained model is only useful if it performs well on unseen data. Performance is measured using:
- Regression Metrics: RMSE, MAE, R².
- Classification Metrics: Accuracy, Precision, Recall, F1-score, AUC-ROC.
- Clustering Metrics: Silhouette Score, Davies-Bouldin Index.
Tools:
-
Scikit-learn's
metricsmodule. - TensorFlow Model Analysis.
8. Hyperparameter Tuning
Fine-tuning model parameters can significantly improve performance. Methods include:
- Grid Search: Exhaustive search over a parameter grid.
- Random Search: Randomly selecting hyperparameters.
- Bayesian Optimization: Probabilistic search using Gaussian Processes.
- Genetic Algorithms: Evolution-based tuning.
Tools:
- Optuna, Hyperopt, GridSearchCV.
9. Model Deployment
Once the model is optimized, it needs to be deployed for real-world use:
- API-based deployment: Using Flask or FastAPI.
- Cloud deployment: AWS SageMaker, GCP AI Platform, Azure ML.
- Edge AI: Deploying models on IoT devices using TensorFlow Lite, ONNX.
- Containerization: Docker, Kubernetes for scalable deployment.
10. Monitoring & Maintenance
ML models require continuous monitoring to remain effective:
- Detecting data drift: Concept drift, covariate shift.
- Logging model predictions for auditing.
- Retraining with new data periodically.
- Scaling and optimizing for performance.
Tools:
- MLflow: Experiment tracking.
- Evidently AI: Model monitoring.
11. Feedback & Continuous Improvement
The ML pipeline is an iterative process. New data, changing user behavior, and industry trends mean models must evolve over time. A strong feedback loop allows:
- Retraining with fresh data.
- Adjusting hyperparameters.
- Deploying improved versions of the model.
Final Thoughts
Building a Machine Learning Pipeline is a systematic approach to developing, deploying, and maintaining ML models efficiently. By following this structured workflow, businesses can scale AI applications, improve accuracy, and ensure reliable, real-time predictions.









