

































































Scalable GraphQL: Why you need DataLoaders
TL;DR DataLoaders solve the N+1 query problem in GraphQL by batching and caching database queries, reducing response times by upto 85% and allowing your API to scale efficiently with data growth. This article explains how DataLoaders work and provides implementation patterns you can apply to your GraphQL API. Checkout the GitHub repository for a full interactive demo, code examples and benchmarking tools. Introduction If you're building a GraphQL API that needs to scale, you've likely encountered performance bottlenecks when handling nested queries. One of the most common issues is the N+1 query problem, which can dramatically increase database load and response times. This article explores how DataLoaders solve this problem by efficiently batching and caching database queries. Prerequisites This article assumes you're familiar with: Basic GraphQL concepts (queries, resolvers, schema, context) JavaScript/TypeScript Apollo Server Our example uses Node.js with Apollo GraphQL and Drizzle ORM, but the concepts apply regardless of your specific tech stack. The N+1 Problem in GraphQL Although the N+1 problem isn't exclusive to GraphQL, GraphQL's nested query structure makes it prone to amplifying this issue. Let's explore why through a practical example. Schema structure type Product { id: ID! name: String! price: Float! category: Category! manufacturer: Manufacturer! } type Category { id: ID! name: String! products: [Product!]! } type Manufacturer { id: ID! name: String! country: String! products: [Product!]! rating: Float! } This schema represents the following relationships: many products per category and one manufacture per product. Problem in Action Here's a typical query we might use in our application to render products grouped by category: query GetCategoriesWithProducts { categories { name products { name price manufacturer { name } } } } Let's look at what actually happens under the hood with this query, even at a small scale: -- First, fetch all categories SELECT * FROM categories; -- Returns: [{id: 1, name: 'Electronics'}, {id: 2, name: 'Books'}, {id: 3, name: 'Clothing'}] -- Then for EACH category, fetch its products SELECT * FROM products WHERE category_id = 1; -- Returns: [{id: 1, name: 'Laptop', manufacturerId: 1}, {id: 2, name: 'Phone', manufacturerId: 2}, {id: 3, name: 'Tablet', manufacturerId: 3}] SELECT * FROM products WHERE category_id = 2; -- Returns: [{id: 4, name: 'Novel', manufacturerId: 4}, {id: 5, name: 'Textbook', manufacturerId: 5}, {id: 6, name: 'Comic', manufacturerId: 6}] SELECT * FROM products WHERE category_id = 3; -- Returns: [{id: 7, name: 'Shirt', manufacturerId: 7}, {id: 8, name: 'Pants', manufacturerId: 8}, {id: 9, name: 'Hat', manufacturerId: 9}] -- Finally, for EACH product, fetch its manufacturer SELECT * FROM manufacturers WHERE id = 1; SELECT * FROM manufacturers WHERE id = 2; SELECT * FROM manufacturers WHERE id = 3; SELECT * FROM manufacturers WHERE id = 4; SELECT * FROM manufacturers WHERE id = 5; SELECT * FROM manufacturers WHERE id = 6; SELECT * FROM manufacturers WHERE id = 7; SELECT * FROM manufacturers WHERE id = 8; SELECT * FROM manufacturers WHERE id = 9; -- Total: 13 queries -- 1 for categories -- 3 for products (one per category) -- 9 for manufacturers (one per product) To make this worse, even if all product results shared the same manufacturer, we would still unnecessarily query the database for the same manufacturer multiple times - once for each product. This approach completely fails to scale. After DataLoader When we use dataloader we end up flattening our above query cascade to the following: -- First, fetch all categories SELECT * FROM categories; -- Returns: [{id: 1, name: 'Electronics'}, {id: 2, name: 'Books'}, {id: 3, name: 'Clothing'}] -- Then for EACH category, fetch its products SELECT * FROM products WHERE category_id IN (1, 2, 3); -- Finally, fetch all manufactures SELECT * FROM manufacturers WHERE product_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9); -- Total: 3 queries -- 1 for categories -- 1 for products -- 1 for manufacturers This no longer increases the number of queries as your data grows with the help of batching (more on this below). How DataLoaders Work DataLoader optimizes data fetching in GraphQL through three key mechanisms: batching, request coalescing and caching. Let's explore how each of these works and their benefits. Batching Each DataLoader instance requires a batch loading function that serves as its foundation. This function must: Accept an array of keys (like product IDs or manufacturer IDs) Return a Promise that resolves to an array of values or errors Maintain the same order as the input keys and its coresponding result import DataLoader from "dataloader"; const productCategoryLoader = new Data
TL;DR
DataLoaders solve the N+1 query problem in GraphQL by batching and caching database queries, reducing response times by upto 85% and allowing your API to scale efficiently with data growth. This article explains how DataLoaders work and provides implementation patterns you can apply to your GraphQL API.
Checkout the GitHub repository for a full interactive demo, code examples and benchmarking tools.
Introduction
If you're building a GraphQL API that needs to scale, you've likely encountered performance bottlenecks when handling nested queries. One of the most common issues is the N+1 query problem, which can dramatically increase database load and response times. This article explores how DataLoaders solve this problem by efficiently batching and caching database queries.
Prerequisites
This article assumes you're familiar with:
- Basic GraphQL concepts (queries, resolvers, schema, context)
- JavaScript/TypeScript
- Apollo Server
Our example uses Node.js with Apollo GraphQL and Drizzle ORM, but the concepts apply regardless of your specific tech stack.
The N+1 Problem in GraphQL
Although the N+1 problem isn't exclusive to GraphQL, GraphQL's nested query structure makes it prone to amplifying this issue. Let's explore why through a practical example.
Schema structure
type Product {
id: ID!
name: String!
price: Float!
category: Category!
manufacturer: Manufacturer!
}
type Category {
id: ID!
name: String!
products: [Product!]!
}
type Manufacturer {
id: ID!
name: String!
country: String!
products: [Product!]!
rating: Float!
}
This schema represents the following relationships: many products per category and one manufacture per product.
Problem in Action
Here's a typical query we might use in our application to render products grouped by category:
query GetCategoriesWithProducts {
categories {
name
products {
name
price
manufacturer {
name
}
}
}
}
Let's look at what actually happens under the hood with this query, even at a small scale:
-- First, fetch all categories
SELECT * FROM categories;
-- Returns: [{id: 1, name: 'Electronics'}, {id: 2, name: 'Books'}, {id: 3, name: 'Clothing'}]
-- Then for EACH category, fetch its products
SELECT * FROM products WHERE category_id = 1;
-- Returns: [{id: 1, name: 'Laptop', manufacturerId: 1}, {id: 2, name: 'Phone', manufacturerId: 2}, {id: 3, name: 'Tablet', manufacturerId: 3}]
SELECT * FROM products WHERE category_id = 2;
-- Returns: [{id: 4, name: 'Novel', manufacturerId: 4}, {id: 5, name: 'Textbook', manufacturerId: 5}, {id: 6, name: 'Comic', manufacturerId: 6}]
SELECT * FROM products WHERE category_id = 3;
-- Returns: [{id: 7, name: 'Shirt', manufacturerId: 7}, {id: 8, name: 'Pants', manufacturerId: 8}, {id: 9, name: 'Hat', manufacturerId: 9}]
-- Finally, for EACH product, fetch its manufacturer
SELECT * FROM manufacturers WHERE id = 1;
SELECT * FROM manufacturers WHERE id = 2;
SELECT * FROM manufacturers WHERE id = 3;
SELECT * FROM manufacturers WHERE id = 4;
SELECT * FROM manufacturers WHERE id = 5;
SELECT * FROM manufacturers WHERE id = 6;
SELECT * FROM manufacturers WHERE id = 7;
SELECT * FROM manufacturers WHERE id = 8;
SELECT * FROM manufacturers WHERE id = 9;
-- Total: 13 queries
-- 1 for categories
-- 3 for products (one per category)
-- 9 for manufacturers (one per product)
To make this worse, even if all product results shared the same manufacturer, we would still unnecessarily query the database for the same manufacturer multiple times - once for each product. This approach completely fails to scale.
After DataLoader
When we use dataloader we end up flattening our above query cascade to the following:
-- First, fetch all categories
SELECT * FROM categories;
-- Returns: [{id: 1, name: 'Electronics'}, {id: 2, name: 'Books'}, {id: 3, name: 'Clothing'}]
-- Then for EACH category, fetch its products
SELECT * FROM products WHERE category_id IN (1, 2, 3);
-- Finally, fetch all manufactures
SELECT * FROM manufacturers WHERE product_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9);
-- Total: 3 queries
-- 1 for categories
-- 1 for products
-- 1 for manufacturers
This no longer increases the number of queries as your data grows with the help of batching (more on this below).
How DataLoaders Work
DataLoader optimizes data fetching in GraphQL through three key mechanisms: batching, request coalescing and caching. Let's explore how each of these works and their benefits.
Batching
Each DataLoader instance requires a batch loading function that serves as its foundation. This function must:
- Accept an array of keys (like product IDs or manufacturer IDs)
- Return a Promise that resolves to an array of values or errors
- Maintain the same order as the input keys and its coresponding result
import DataLoader from "dataloader";
const productCategoryLoader = new DataLoader(async (ids) => {
const products = await db.products.findMany({
where: { categoryId: { in: ids } },
});
// Must preserve order of input ids
return orderMany(ids, products);
});
Request Coalescing
Request coalescing is the process where multiple individual requests for data that occur within the same event loop tick are automatically combined into a single batch operation. For example:
// These separate load calls:
productCategoryLoader.load(1);
productCategoryLoader.load(2);
productCategoryLoader.load(3);
// Become a single batch operation:
SELECT * FROM products WHERE category_id IN ('1', '2', '3')
Caching Mechanism
DataLoader implements a per-request memoization cache that:
- Caches values for the lifetime of the request
- Is not intended as a permanent response cache
- Helps prevent duplicate database queries within a single request
For example, if multiple products reference the same manufacturer in the same request:
// Only triggers one database query even if called multiple times
await manufacturerLoader.load(1); // DB query
await manufacturerLoader.load(1); // Uses cache
await manufacturerLoader.load(1); // Uses cache
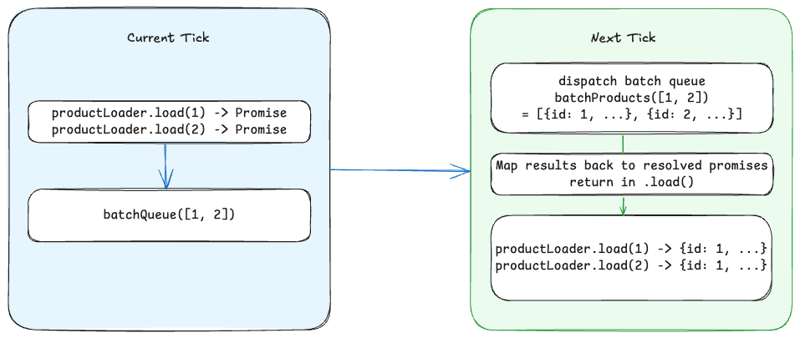
Batch Scheduling
Batch scheduling controls when the batch loading function executes:
- Scheduled to run on the next event loop tick (via
process.nextTick()by default) - Collects all keys requested via
load()during the current tick - Passes collected keys to the batch function as a single array
- Returns results to individual
load()calls in matching order
The process flows like this:
- Multiple
load()calls queue their keys during current tick - DataLoader schedules batch execution for next tick
- On next tick, batch function executes with all collected keys
- Results are distributed back to original
load()promises
This combination of mechanisms makes DataLoader efficient for GraphQL APIs, reducing the number of database queries while maintaining clean resolver code.
Implementation
While the DataLoader documentation effectively describes how dataloaders work under the hood, the actual implementation strategy is left for you to configure. I typically structure my dataloaders module like this:
/dataloaders
- batching.ts // Contains batch functions
- store.ts // Defines dataloader instances
- utils.ts // Helper functions
- index.ts // Main export file
Group Batching
In the batching file, I group all the batch functions together. I follow consistent naming conventions to make the code more readable and maintainable:
For one-to-one relations:
I structure naming as: batch
Examples:
-
batchManufacturerById- Retrieves a manufacturer by its ID -
batchManufacturerByProductId- Retrieves a manufacturer associated with a product ID
For one-to-many relations:
I structure naming as: batchMany
Examples:
-
batchManyProductsById- Retrieves multiple products by their IDs -
batchManyProductsByCategoryId- Retrieves all products for a given category ID
Store
For small applications, you could put all your dataloaders directly on the context object:
context: (req, res) => ({
// ...other context properties
dataloaders: {
productsLoader: new DataLoader(batchProductsById),
manufacturersLoader: new DataLoader(batchManufacturersById),
},
});
However, this approach quickly becomes inefficient. As your application grows, the additional memory required for all these dataloader instances can impact performance. Large applications may have hundreds or even thousands of dataloaders in a single store.
To mitigate this issue, we can implement lazy loading for dataloaders:
// store.ts
export const store = {
productsLoader: () => new DataLoader(batchProductsById),
manufacturersLoader: () => new DataLoader(batchManufacturersById),
};
// index.ts
export function createDataLoaders() {
const loaders = new Map<string, DataLoader<any, any>>();
return {
get: function <K, V>(key: string): DataLoader<K, V> {
if (!loaders.has(key)) {
if (!store[key]) {
throw new Error(`DataLoader with key ${key} not found in store`);
}
loaders.set(key, store[key]());
}
return loaders.get(key) as DataLoader<K, V>;
},
};
}
Now you can pass this factory function in your context and lazy-load only the dataloaders you need:
const server = new ApolloServer({
context: (req, res) => ({
dataloaders: createDataLoaders(),
}),
});
In your resolvers, you would access the dataloaders like this:
const resolvers = {
Product: {
manufacturer: async (product, _, context) => {
return context.dataloaders
.get("manufacturersLoader")
.load(product.manufacturerId);
},
},
};
Key Benefits
This implementation approach offers several advantages:
- Memory Efficiency: Dataloaders are only created when needed
- Type Safety: Using TypeScript generics ensures correct typing
- Maintainability: Clear naming conventions make the code easier to understand
- Error Handling: Provides clear feedback when a loader doesn't exist
Remember that each GraphQL request should have its own DataLoader instances to prevent cross-request caching issues. The pattern above ensures that a new set of loaders is created for each request context.
Benchmarks
Test Configurations
| Run | Label | Categories | Products/Category | Manufacturers | Total Records |
|---|---|---|---|---|---|
| A | Small | 10 | 5 | 5 | 50 |
| B | Medium | 50 | 20 | 20 | 1,000 |
| C | Large | 200 | 50 | 50 | 10,000 |
| D | XL | 1000 | 100 | 100 | 100,000 |
Performance Results
Run A (Small Dataset - 50 Records)
| Metric | With DataLoader | Without DataLoader | Improvement |
|---|---|---|---|
| Average Response Time | 3.36 ms | 9.42 ms | 64.3% |
| Median Response Time | 2.55 ms | 8.08 ms | 68.4% |
| Min Response Time | 1.79 ms | 6.95 ms | 74.2% |
| Max Response Time | 43.60 ms | 58.42 ms | 25.4% |
Run B (Medium Dataset - 1,000 Records)
| Metric | With DataLoader | Without DataLoader | Improvement |
|---|---|---|---|
| Average Response Time | 24.02 ms | 144.74 ms | 83.4% |
| Median Response Time | 21.22 ms | 139.39 ms | 84.8% |
| Min Response Time | 19.99 ms | 133.27 ms | 85.0% |
| Max Response Time | 85.83 ms | 225.82 ms | 62.0% |
Run C (Large Dataset - 10,000 Records)
| Metric | With DataLoader | Without DataLoader | Improvement |
|---|---|---|---|
| Average Response Time | 238.91 ms | 1,543.83 ms | 84.5% |
| Median Response Time | 231.13 ms | 1,537.57 ms | 85.0% |
| Min Response Time | 209.72 ms | 1,445.89 ms | 85.5% |
| Max Response Time | 418.55 ms | 1,807.23 ms | 76.8% |
Run D (Extra Large Dataset - 100,000 Records)
| Metric | With DataLoader | Without DataLoader | Improvement |
|---|---|---|---|
| Average Response Time | 6,133.99 ms | 20592.45 ms | 70.2% |
| Median Response Time | 6,068.14 ms | 20511.97 ms | 70.4% |
| Min Response Time | 5,761.18 ms | 19250.59 ms | 70.1% |
| Max Response Time | 6,807.52 ms | 21962.64 ms | 69.0% |
Conclusion
These benchmarks clearly demonstrate DataLoader's effectiveness at solving the N+1 query problem in GraphQL. The performance improvements range from 64% faster with small datasets to over 84% faster with large datasets, making DataLoader essential for production GraphQL APIs handling relational data at scale.
Ready to implement DataLoaders in your GraphQL API? Check out the complete code examples here to get started









