






























































Protocol Parsing Guide: From Packets To Structured Data
In this blog, I’ll walk you through the essential steps and guidance for parsing network protocols. We’ll assume that you’re already running a Layer 4 (L4) proxy to capture packets into a buffer, and you have both the client and destination connection objects readily available. This guide will focus on helping you convert raw network data into meaningful, structured information. How Keploy Uses Protocol Parsing to Turn Live Traffic into Test-Ready Data? In contemporary software testing and observability, protocol parsing is central to the process of converting raw packets into actionable information. At the core of this is the protocol data unit (PDU)—the building block that conveys structured data from layer to layer in communication. Protocol parsing powers tools such as Keploy.io to automatically capture, analyze, and transform live API traffic into test cases and mocks. Through the knowledge and unbundling of PDUs, Keploy allows developers to create deterministic tests from live interactions on the fly, with increased coverage and speedy debugging. This tutorial delves into the concepts behind protocol parsing, revealing how such platforms as Keploy make the journey from raw packets to tidy, testable data a matter of ease. Understanding Protocols: The Backbone of Network Communication 1. What is a Protocol? A protocol is a set of rules and conventions that govern how data is transmitted over a network. Think of it as a language that allows devices (such as computers, servers, or smartphones) to communicate with each other. Just like how humans follow grammar and syntax in language, network protocols ensure that devices follow the same structure when exchanging data, so that information is sent, received, and understood correctly. Parsing network protocols is an essential process in the construction of stable communication systems, allowing developers to convert raw packet data into meaningful, structured information. At the heart of this process is the idea of a protocol data unit (PDU)—the smallest unit of data that is communicated within a given layer of a network protocol. Understanding and parsing PDUs correctly is critical to packet inspection, debugging, and creating custom network tools. This tutorial offers a hands-on method of protocol parsing, demonstrating how to break down packet headers, extract payloads, and translate binary streams into structured data formats that are more convenient to work with and analyze. 2. Different Types of Protocols There are various types of protocols, each designed for specific functions. Some of the most common categories include: • Application Layer Protocols: These are used by applications to communicate over a network. Examples include HTTP (for web browsing), FTP (for file transfer), and SMTP (for sending emails). • Transport Layer Protocols: Responsible for ensuring that data is transmitted reliably. TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are the primary protocols in this layer. • Network Layer Protocols: These manage the routing and forwarding of data across networks. The most common example is IP (Internet Protocol). • Link Layer Protocols: These handle communication between devices on the same local network, such as Ethernet and Wi-Fi. 3. How Most Protocols Operate Under the TCP/IP Model The TCP/IP (Transmission Control Protocol/Internet Protocol) model is the foundation of most network communication on the internet today. It consists of four layers: Link, Internet (Network), Transport, and Application. • Link Layer: Handles communication on the local network. • Internet Layer: Manages the movement of packets across different networks, primarily using IP. • Transport Layer: Ensures reliable data transmission through TCP, or faster, connectionless transmission through UDP. • Application Layer: The topmost layer where protocols like HTTP, FTP, and DNS operate. Most protocols you encounter, from web browsing to email, work within the structure of TCP/IP, ensuring that data travels efficiently across global networks. Why Parsing Protocols is Essential: Unpacking Data for Understanding and Control Why Do I Need to Parse a Protocol? Parsing a protocol means breaking down the raw data transmitted over a network into a structured and understandable format. This is crucial because: • Extracting Meaningful Data: Protocols often encode data in complex formats. By parsing them, you can extract valuable information, such as headers, payloads, or metadata, which can be used for further analysis or decision-making. • Monitoring and Debugging: In networking, parsing helps diagnose issues like connection failures or packet loss. By decoding the protocol, you can understand what’s going wrong at a granular level. • Security and Compliance: Parsing enables you to inspect packets for potential threats or security vulnerabilities. This can be useful for enforcing policies or detecting anomal
In this blog, I’ll walk you through the essential steps and guidance for parsing network protocols. We’ll assume that you’re already running a Layer 4 (L4) proxy to capture packets into a buffer, and you have both the client and destination connection objects readily available. This guide will focus on helping you convert raw network data into meaningful, structured information.
How Keploy Uses Protocol Parsing to Turn Live Traffic into Test-Ready Data?
In contemporary software testing and observability, protocol parsing is central to the process of converting raw packets into actionable information. At the core of this is the protocol data unit (PDU)—the building block that conveys structured data from layer to layer in communication. Protocol parsing powers tools such as Keploy.io to automatically capture, analyze, and transform live API traffic into test cases and mocks. Through the knowledge and unbundling of PDUs, Keploy allows developers to create deterministic tests from live interactions on the fly, with increased coverage and speedy debugging. This tutorial delves into the concepts behind protocol parsing, revealing how such platforms as Keploy make the journey from raw packets to tidy, testable data a matter of ease.
Understanding Protocols: The Backbone of Network Communication
1. What is a Protocol?
A protocol is a set of rules and conventions that govern how data is transmitted over a network. Think of it as a language that allows devices (such as computers, servers, or smartphones) to communicate with each other. Just like how humans follow grammar and syntax in language, network protocols ensure that devices follow the same structure when exchanging data, so that information is sent, received, and understood correctly.
Parsing network protocols is an essential process in the construction of stable communication systems, allowing developers to convert raw packet data into meaningful, structured information. At the heart of this process is the idea of a protocol data unit (PDU)—the smallest unit of data that is communicated within a given layer of a network protocol. Understanding and parsing PDUs correctly is critical to packet inspection, debugging, and creating custom network tools. This tutorial offers a hands-on method of protocol parsing, demonstrating how to break down packet headers, extract payloads, and translate binary streams into structured data formats that are more convenient to work with and analyze.
2. Different Types of Protocols
There are various types of protocols, each designed for specific functions. Some of the most common categories include:
• Application Layer Protocols: These are used by applications to communicate over a network. Examples include HTTP (for web browsing), FTP (for file transfer), and SMTP (for sending emails).
• Transport Layer Protocols: Responsible for ensuring that data is transmitted reliably. TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are the primary protocols in this layer.
• Network Layer Protocols: These manage the routing and forwarding of data across networks. The most common example is IP (Internet Protocol).
• Link Layer Protocols: These handle communication between devices on the same local network, such as Ethernet and Wi-Fi.
3. How Most Protocols Operate Under the TCP/IP Model
The TCP/IP (Transmission Control Protocol/Internet Protocol) model is the foundation of most network communication on the internet today. It consists of four layers: Link, Internet (Network), Transport, and Application.
• Link Layer: Handles communication on the local network.
• Internet Layer: Manages the movement of packets across different networks, primarily using IP.
• Transport Layer: Ensures reliable data transmission through TCP, or faster, connectionless transmission through UDP.
• Application Layer: The topmost layer where protocols like HTTP, FTP, and DNS operate.
Most protocols you encounter, from web browsing to email, work within the structure of TCP/IP, ensuring that data travels efficiently across global networks.
Why Parsing Protocols is Essential: Unpacking Data for Understanding and Control
Why Do I Need to Parse a Protocol?
Parsing a protocol means breaking down the raw data transmitted over a network into a structured and understandable format. This is crucial because:
• Extracting Meaningful Data: Protocols often encode data in complex formats. By parsing them, you can extract valuable information, such as headers, payloads, or metadata, which can be used for further analysis or decision-making.
• Monitoring and Debugging: In networking, parsing helps diagnose issues like connection failures or packet loss. By decoding the protocol, you can understand what’s going wrong at a granular level.
• Security and Compliance: Parsing enables you to inspect packets for potential threats or security vulnerabilities. This can be useful for enforcing policies or detecting anomalies.
• Custom Applications: In certain use cases, you may need to build or modify protocol parsers to interact with custom or proprietary systems. Parsing allows you to do that effectively.
How Can a Protocol Be Parsed?
Protocols can vary widely in format—some use human-readable text (like HTTP), while others use compact binary data (like many low-level communication protocols). Parsing involves understanding the structure of the protocol (e.g., headers, payloads, flags) and systematically extracting those components. Common steps include:
• Identifying Packet Boundaries: Knowing where a packet starts and ends.
• Reading Headers: Extracting metadata such as packet size, source, destination, and type of data.
• Decoding Payload: Interpreting the actual data being transmitted.
• Handling Error Codes and Flags: Managing protocol-specific nuances like checksums or control flags.
In this blog, I’ll focus on parsing binary wire protocols, which transmit data in a compact and efficient binary format. However, the steps outlined here can also be adapted for other protocols, such as simple text-based ones.
Leveraging Documentation and Wireshark for Effective Protocol Parsing
A. Use Documentation and Wireshark Together
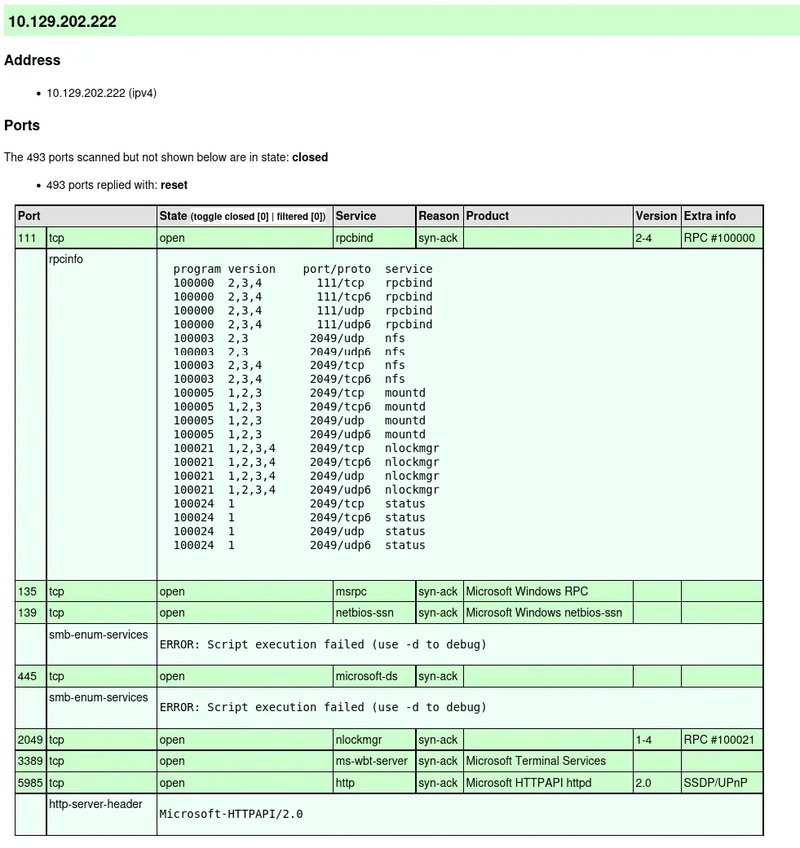
When working with protocols, the first step is to thoroughly review the official documentation of the protocol you’re working with (e.g., MySQL, MongoDB). The documentation will provide critical details on how packets are structured, what data fields are present, and what you need to look for.
Wireshark, a powerful network protocol analyzer, helps you visualize this data. However, Wireshark can only recognize protocols if they are running on their default ports (unless configured otherwise). If you’re using a non-default port for your protocol, Wireshark might not automatically detect it. To ensure that Wireshark can help dissect the protocol packets properly, make sure the service (e.g., MySQL, MongoDB) is running on its default port. This allows Wireshark to correctly label and dissect the packets.
B. Explore Popular Clients to Understand Packet Decoding
Along with documentation, another effective way to understand how a protocol works is to analyze the popular client libraries that implement that protocol. For instance, if you’re working with MySQL, explore open-source MySQL clients and check how they decode and handle incoming and outgoing packets. This can help you see how protocol-specific packets are constructed and parsed.
For protocols with well-documented implementations (e.g., MySQL, MongoDB), you can easily correlate each packet seen in Wireshark with its documented structure. This makes the decoding process more intuitive, as you can visually match packet components to their description in the protocol documentation.
Generating and Analyzing PCAP Files Using Tshark or Tcpdump
To capture and analyze network traffic for a specific protocol, you can use Tshark or Tcpdump. These tools allow you to record live traffic in a PCAP (Packet Capture) file, which can then be analyzed in Wireshark for a deeper understanding.Here’s how you can generate a PCAP file:
Here’s how you can generate a filtered PCAP file using these tools:
1. Using Tshark
To capture only the traffic on a specific port (e.g., MySQL running on port 3306), you can run the following command:
sudo tshark -i any -f "port 3306" -w capture.pcap
• -i any: Captures traffic on any network interface.
• -f "port 3306": Filters the traffic to capture only packets related to the specified port (e.g., MySQL).
• -w capture.pcap: Writes the captured traffic to a file called capture.pcap.
This command will capture all MySQL traffic to and from port 3306 and save it in a PCAP file, which can then be loaded into Wireshark for analysis.
2. Using Tcpdump
Similarly, you can use Tcpdump to capture traffic on a specific port:
sudo tcpdump -i any port 3306 -w capture.pcap
• -i any: Captures traffic on all available interfaces.
• port 3306: Filters traffic to capture only packets related to port 3306 (for MySQL).
• -w capture.pcap: Saves the captured traffic to capture.pcap.
Once the PCAP file is generated, you can load it into Wireshark for detailed inspection:
1. Open Wireshark and go to File > Open.
2. Select your capture.pcap file and load it.
3. Wireshark will dissect the captured packets, showing detailed protocol-level data such as headers, flags, and payloads.
By filtering traffic with Tshark or Tcpdump and using Wireshark for visualization, you can clearly see the packet structure and flow, which helps in understanding the protocol and debugging any communication issues.
What Happens After the TCP Handshake?
Once the basic TCP handshake is completed between the client and the server, different wire protocols have their own mechanisms to establish a successful connection and continue communication. These mechanisms vary depending on the protocol being used.
1. Initial Handshake in Different Wire Protocols
Each protocol handles the connection setup differently, for eg:
• MongoDB: Unlike other databases, MongoDB doesn’t have a formal initial handshake. Instead, it uses a heartbeat call that occurs at regular intervals to ensure the connection is alive. This mechanism is primarily used for monitoring the status of the connection.
• MySQL and PostgreSQL: Both these databases implement a well-defined initial handshake. This handshake involves an exchange of data between the client and server, including flags, capabilities, authentication methods, and the actual authentication process itself. The amount of data exchanged and the exact details of the handshake can differ between protocols.
2. How Does HTTP Handle It?
In contrast, HTTP does not require an explicit initial handshake after the TCP connection. The client sends a request directly to the server over the TCP connection, and the server responds. Once the request-response cycle is complete, the connection can be closed immediately. While there are techniques like HTTP Keep-Alive to keep the connection open for multiple requests, the protocol does not inherently include a handshake like database protocols. The connection can be reused, but each HTTP request is independent.
Connection Pooling: Efficient Management of Database Connections
What is Connection Pooling?
Connection pooling is a technique commonly used in database protocols like MySQL, PostgreSQL, and MongoDB to manage database connections more efficiently. Instead of opening a new connection for each request, a pool of connections is created and maintained. These connections are reused for multiple requests, significantly reducing the overhead of establishing new connections every time.
How It Works:
• Pooling at Start: When an application starts, it opens a set number of database connections (called a connection pool). These connections are kept alive and ready for use, allowing requests to be made without the need to establish a new connection each time.
• Reusing Connections: When a client needs to query the database, it borrows a connection from the pool. After the request is completed, the connection is returned to the pool, ready to be reused by another request.
• Connection Lifecycle: Once a connection is established, it is kept open and maintained. All future requests between the client and the server are exchanged using the same connection until one of the sides (client or server) closes it. This method reduces latency and resource consumption, as the overhead of repeatedly setting up new connections is avoided.
Why Connection Pooling is Important:
• Performance Boost: Creating new connections can be expensive in terms of time and resources. Connection pooling allows the system to handle more requests efficiently by reusing already-established connections.
• Connection Reuse: Since database operations often require several interactions with the server, keeping connections open (through connection pooling) prevents the need to repeat the initial handshake and authentication process, saving both time and resources.
Closing Connections and New Handshake:
When a connection is closed—either due to timeout, server shutdown, or client decision—a new connection will be created. This new connection will go through the entire initial setup process, including the handshake and authentication, before it can be used for data exchange.
Key Terms to Understand When Reading or Writing Data Over Connections
When working with network connections, especially when reading from or writing to the connection, there are several important terms and concepts that you should be familiar with. These terms help you understand different connection states, errors, and timeouts that can occur during communication between the client and server.
1. EOF (End of File)
EOF stands for End of File, which in the context of networking, signifies that the connection has been gracefully closed by the remote side. When a client or server reads from the connection and encounters EOF, it means that no more data can be read because the other side has finished sending data and closed the connection. This is not an error but a normal termination of the data stream.
2. ReadTimeout
A ReadTimeout occurs when the connection fails to receive data within a specified time limit. It is often used to prevent the application from hanging while waiting for data that may never arrive. If the timeout is reached, the read operation is aborted, and a timeout error is raised. This is useful in scenarios where the server or client is unresponsive, preventing unnecessary waiting.
3. WriteTimeout
A WriteTimeout is triggered when an attempt to send data over a connection takes longer than the specified time limit. Similar to ReadTimeout, this mechanism ensures that the system does not get stuck waiting to write data to a possibly unresponsive peer. If the timeout occurs, the write operation is terminated, and an error is returned.
4. IdleTimeout
An IdleTimeout refers to the maximum period that a connection can remain open without any activity (either reading or writing). If no data is exchanged for the duration of this timeout, the connection is considered idle and may be closed by the system. This is often used to free up resources by terminating connections that are no longer active.
5. Connection Reset by Peer
This error occurs when the remote side (the “peer”) of the connection forcefully closes the connection unexpectedly. Instead of performing a graceful shutdown, the peer terminates the connection abruptly, which causes the local system to receive a “connection reset” error. This can happen due to a variety of reasons, such as a network issue or an application crash on the remote side.
6. Broken Pipe
A Broken Pipe error occurs when a process tries to write to a connection that has already been closed by the remote side. For example, if a client closes the connection but the server tries to send more data, the server will encounter a broken pipe error because it is attempting to write to a non-existent (closed) connection. This typically indicates that communication was interrupted unexpectedly.
These terms and concepts are critical when dealing with network communication, especially for diagnosing and handling issues that arise during reading or writing operations over a connection. Understanding these terms will help you troubleshoot connection errors and ensure stable data transmission between client and server.
Identifying the Type of Wire Protocol: Key Techniques
At the very start of protocol parsing, it’s crucial to determine the type of wire protocol being used in the communication. Identifying the protocol early helps in reading and interpreting the subsequent packets correctly. There are several ways to identify the protocol type, including examining magic numbers or specific fields in the packet header. Each protocol has unique characteristics that can help us make this determination.
Ways to Identify the Protocol Type
1. Magic Numbers: Certain protocols use a specific sequence of bytes (called a “magic number”) at the start of each packet, which can be used to identify the protocol.
2. Packet Header Fields: Many protocols include identifiers or metadata in the headers, such as protocol versions, message lengths, or flags, that help in protocol recognition.
Let’s look at examples from some common protocols:
Example: HTTP
In HTTP, protocol identification is simple and relies on common HTTP method names like GET, POST, or the string HTTP/. The function checks if the buffer starts with any of these methods or the “HTTP/” string to determine if it’s an HTTP packet.
go
func (h *HTTP) MatchType(_ context.Context, buf []byte) bool {
isHTTP := bytes.HasPrefix(buf[:], []byte("HTTP/")) ||
bytes.HasPrefix(buf[:], []byte("GET ")) ||
bytes.HasPrefix(buf[:], []byte("POST ")) ||
bytes.HasPrefix(buf[:], []byte("PUT ")) ||
bytes.HasPrefix(buf[:], []byte("PATCH ")) ||
bytes.HasPrefix(buf[:], []byte("DELETE ")) ||
bytes.HasPrefix(buf[:], []byte("OPTIONS ")) ||
bytes.HasPrefix(buf[:], []byte("HEAD "))
h.logger.Debug(fmt.Sprintf("Is HTTP Protocol?: %v", isHTTP))
return isHTTP
}
In this case, if the buffer starts with any of the standard HTTP method names, it’s identified as HTTP traffic.
Example: MongoDB
In MongoDB, protocol identification is done by inspecting the first 4 bytes of the packet, which represent the message length. The protocol expects that the message length in the first 4 bytes should match the actual length of the buffer, indicating a valid MongoDB message.
go
func (m *Mongo) MatchType(_ context.Context, buffer []byte) bool {
if len(buffer) < 4 {
return false
}
// The first 4 bytes contain the message length
messageLength := binary.LittleEndian.Uint32(buffer[0:4])
return int(messageLength) == len(buffer)
}
If the length matches, the message is likely a MongoDB packet.
Example: PostgreSQL
PostgreSQL protocol uses the protocol version number in its message header for identification. The version is located in bytes 4 to 8 of the packet, and by comparing it to known values, the protocol type is determined.
go
func (p *PostgresV1) MatchType(_ context.Context, reqBuf []byte) bool {
const ProtocolVersion = 0x00030000 // Protocol version 3.0
if len(reqBuf) < 8 {
return false
}
// The protocol version is in bytes 4 to 8
version := binary.BigEndian.Uint32(reqBuf[4:8])
return version == ProtocolVersion || version == 80877103
}
In this case, the function checks if the protocol version matches PostgreSQL’s version 3.0.
Decoding and Parsing Protocols: Step-by-Step Guide
Once the protocol type is identified, the next step is to correctly read and interpret packets being transferred between the client and server. By following protocol documentation and using tools like Wireshark to inspect the packet flow, we can understand the sequence and structure of the packets. Most protocols are already dissected by Wireshark, making it easier to read packet information and compare it with the official protocol documentation.
1. Sequential Packet Reading and Parsing
After identifying the protocol, we need to read packets one by one in the correct order. This involves following a systematic process:
1. Read the Header First: The header typically contains metadata, including the length of the payload. Knowing the header length beforehand helps you extract the relevant information.
2. Read the Payload: Once the header is read, extract the payload based on the length indicated in the header. The payload is where the actual data resides.
3. Identify Packet Type: In many protocols, the packet type can be identified using the first few bytes of the payload. For example, in MySQL, if the payload length is 5 and the first byte is 0xFE, the packet is an EOF packet.
4. Parse Protocol-Specific Packets: Various packets, such as handshake packets, query packets, and error packets, are handled differently based on their type. In cases where there is no direct packet identifier (like result set packets in MySQL), rely on the sequence of packets. For example, after receiving a query packet from the client, the server will respond with a result set that might not have a clear identifier but can be inferred based on the packet flow.
2. Handling Packet Fragmentation
It’s important to understand that not all information will fit into a single packet. Responses can be larger than the maximum allowed packet size, and protocols handle this by splitting data across multiple packets. For example:
• Result Set Packets: In MySQL, a result set that contains rows and columns may not fit into one packet. Instead, it is split into multiple packets, each containing part of the data (e.g., rows and columns).
• Handling Multiple Packets: When reading fragmented packets, ensure that each part is correctly reassembled to get the full message.
3. Efficient Packet Flow: Read, Write, and Parse
The ideal packet flow ensures that there is no unnecessary delay between reading, writing, and parsing. Here’s how it works:
1. Read from Client: Capture the packet sent from the client.
2. Write to Server: Forward the packet to the server without delay.
3. Parse the Packet: Perform protocol-specific decoding of the packet. Based on the type of packet, decide whether it’s a query, handshake, or another type of packet.
4. Read from Server: Capture the server’s response.
5. Write to Client: Forward the response to the client while parsing it to understand the data flow.
This process ensures minimal latency and keeps the connection smooth, without adding unnecessary delays that could cause timeouts.
Code Implementation Example
Here’s a basic example of how protocol decoding could be implemented using Go. The function decodeProtocol() determines the protocol type and calls the appropriate decoding function (e.g., decodePostgres() for PostgreSQL).
go
func decodeProtocol(client, server net.Conn) {
// Find the protocol type (e.g., Postgres, Mongo, HTTP)
protocolType := identifyProtocol(client, server)
// Go to the protocol-specific decoding logic
switch protocolType {
case "postgres":
decodePostgres(client, server)
case "http":
decodeHTTP(client, server)
case "mongo":
decodeMongo(client, server)
default:
log.Println("Unknown protocol type")
}
}
4. Example: Decoding PostgreSQL Protocol
Let’s take PostgreSQL as an example. In PostgreSQL, the client and server go through an initial handshake. After the handshake is completed, the connection remains open for further data exchanges.
func decodePostgres(client, server net.Conn) {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// Read the initial packet from the client
clientPacket := make([]byte, 4096)
_, err := client.Read(clientPacket)
if err != nil {
log.Println("Error reading from client:", err)
return
}
// Write the packet to the server
_, err = server.Write(clientPacket)
if err != nil {
log.Println("Error writing to server:", err)
return
}
// Parse the packet (dummy parse function for now)
parsePacket(clientPacket)
// Continue reading and writing for the initial handshake
handshakeComplete := false
for !handshakeComplete {
serverPacket := make([]byte, 4096)
_, err = server.Read(serverPacket)
if err != nil {
log.Println("Error reading from server:", err)
return
}
_, err = client.Write(serverPacket)
if err != nil {
log.Println("Error writing to client:", err)
return
}
// Parse the server response
parsePacket(serverPacket)
// Check if handshake is complete
handshakeComplete = checkHandshakeComplete(serverPacket)
}
// Once the handshake is complete, keep the connection alive for further communication
errCh := make(chan error)
go func() {
for {
select {
case <-ctx.Done():
return
default:
// Handle reading and writing of actual data exchange between client and server
errCh <- handleClientServerCommunication(client, server)
}
}
}()
select {
case <-ctx.Done():
case err := <-errCh:
log.Println("Error during communication:", err)
}
}
Key Takeaways:
• No Delays Between Read/Write: The most important thing to note is that you should not add unnecessary sleep between reading and writing packets. Adding artificial delays can cause timeouts or unnecessary latency.
• Initial Handshake: After the initial handshake is completed, the connection is kept alive, and all further communication happens on the established connection without additional handshakes.
• Packet Parsing: Most of the protocol-specific packets can be identified based on the first few bytes of the payload. In some cases, you may need to rely on the flow of communication to determine the packet type.
Limitations to Keep in Mind
While decoding protocols and handling packet parsing can be straightforward for many common protocols, there are several important limitations and considerations to be aware of:
1. Protocol Flow Can Vary
Some protocols are not as straightforward as reading from the client first to identify the protocol type. For example, in MySQL, the server sends the first packet, so we cannot always rely on reading the first packet from the client. In such cases, alternative methods can be used, like checking the default port of the server to identify the protocol.
2. Encryption in TLS or HTTPS
When TLS is enabled for databases or when dealing with HTTPS requests, the data exchanged between the client and server will be encrypted. This means that we cannot directly inspect or parse the payload, as it requires decryption before further processing. Handling encrypted traffic requires additional steps, such as performing a TLS handshake and decrypting the data, before packet inspection is possible.
Conclusion
In this blog, we explored the steps and techniques for decoding and parsing network protocols efficiently. From identifying the protocol type through magic numbers or packet headers to systematically reading, writing, and parsing packets, we covered the essentials of protocol handling. We also discussed the importance of connection management and how tools like Wireshark can help visualize the packet flow to better understand the protocol structure.
However, limitations such as varying protocol flows (e.g., MySQL server-initiated communication) and encryption in TLS/HTTPS highlight the need for flexible approaches to protocol parsing. Understanding these complexities ensures that we can adapt our strategies to different scenarios effectively.
For more in-depth code and protocol handling, you can refer to Keploy’s proxy integrations.
FAQ’S
1. What is protocol parsing and why does it matter?
Protocol parsing is the act of examining and retrieving structured data out of raw network packets. Protocol parsing assists programmers in comprehending how data gets transmitted between systems by interpreting headers, payloads, and metadata. This is required for debugging, monitoring, and creating network-sensitive tools. Effective parsing guarantees that transmitted data gets handled and interpreted correctly.
2. What is a protocol data unit (PDU)?
A Protocol Data Unit (PDU) is the lowest unit of data passed between entities in a given layer of a network protocol. Every layer, e.g., TCP or HTTP, has its own PDU format. Knowledge of PDUs is essential for proper protocol parsing and application behavior examination. It forms the basis of packet data decoding and packet data structuring.
3. What does protocol parsing have to do with tools such as Keploy?
Protocol parsing is utilized by tools such as Keploy to capture and interpret automatically API calls from live traffic. By unpacking packets into structured requests and responses, Keploy can create test cases and mocks. This is done without the need for manual writing of tests and makes the tests more reliable. Protocol parsing allows this effortless conversion of traffic to test assets.
4. What are the challenges in protocol parsing?
Parsing protocols can be challenging because protocols have different formats, have nested data, or contain encrypted content. Dealing with edge cases, corrupted packets, or special protocol extensions involves strong parsing logic. Performance is also a consideration for developers as they need to process large amounts of data. In spite of difficulties, efficient parsing is important to develop accurate and responsive systems.




