

































































Migraciones en Drupal
Estoy con un proyecto que es una migración imporante, tanto por la importancia de la web como por el volumen de datos que se tienen que mover entre versiones, y la verdad es que mirando para atras entre el conocimiento de lo que sabía de las migraciones que había hecho antes con Drupal y lo que se ahora puede decir que es todo un mundo. ¿Cuál es el problema que le estoy viendo al framework de migraciones de Drupal? Pues que sinceramente no lo veo pensado para grandes migraciones con las casuistícas que se tienen en la vida real. Casuisticas de la vida real: El servidor de desarrollo no es solo tuyo y no puede bloquear los despliegues mientras migras ergo una parte del día es para el resto de compañeros y la otra parte del día el servidor es tuyo, lo que supone lanzar migraciones a las 15.00 y tener que estar chequeando a las 20.00 y a las 23:50 para comprobar que todo va bien. Los procesos de backups hacen de las suyas, y más cuando Cliente no es capaz de decirte cuando se lanza el backup sino que te dice una franja horaria estimadas (desde las 00:00 hasta las 04:00 de la madrugada). También es cierto que el proyecto no es un proyecto cualquiera y tiene sus propias casuisticas: Archivos grandes, videos, audios, etc... Muchos archivos, cerca de 300.000 entradas en la tabla file_managed y subiendo. Muchos archivos duplicados, a día de hoy tenemos migrados 200k archivos de los cuales +70k archivos son duplicados (1) Usar la función hash_file te deja sin memoria, parece ser que hash_file no cierra al momento los archivos que abre y al usarla con muchos archivos, más los archivos propios que usa la app funcionando, etc... y puede terminar en un error de PHP de muchos archivos abiertos. ¿Qué retos nos hemos encontrado migrando volúmenos de datos tan grandes? Lo primero es que se pueden lanzar migraciones controladasa por el flag "--limit=" (no recuerdo si viene en migration_tools o en migrations_plus), pero si lanzas una migración de 10k registros, y luego vuelves a lanzar otra migración de 10 registros, el proceso demigración de Drupal pasa primero por esos primeros 10k registros ya migrados y luego migra los siguientes 10k registros. Existe una opción de configuración que es Highwater Marks, esta opción nos permite definir un campo, por ejemplo un campo timestamp, updated, created, etc.... Cual es la casuistica del proyecto de Cliente, pues que hace cargas masivas de archivos, lo que significa que si tenemos 30 archivos con el mismo timestamp y el proceso de migración no completa esos 30 archivos, sino que hace 15, la siguiente vez que migra empieza en el timestamp mayor que el último timestamp migrado por lo que se deja elementos sin migrar. En esta foto, los números entre paréntesis son los fids, tienen grandes saltos por lo que he comentado, tenemos muchos archivos con el mismo timestamp ya que se dan tanto cargas masivas de imágenes como el uso de VBO para actualizar contenido. Aquí que Ana María Picón Sánchez, vino con la idea de definir el fid en vez de un campo de tipo fecha en Highwater Marks, y si funciona, pero tiene el problema de que no sirve con los contenidos ya migrados, sino que empieza de cero a remigrar todo, y no es plan de decirle a Iñigo Gascon Royo que tenemos que lanzar otra vez toda la migración. Además de que por lo que sea de cuando en cuando nos da errores en las migraciones que posteriores migraciones se solucionan del tipo archivos que desaparecen, etc. Otra solución a esto la dió Francisco Bocanegra Rodríguez, y es que como tenemos nuestro propio source para las migraciones, benditos custom sources, se puede indicar en las migraciones que se quiere migrar por lotes y controlar también lo que se migra mediante un condition indicando una fecha y decir que se migre todo lo anteior a esa fecha o todo lo posterior a esa fecha. En una migración normal esto sería posible, pero para migrar la tabla de archivos nos encontramos de que no existe una correlación entre el timestamp y el fid. (En esta tabla ordenados las imágenes por la fecha, las más antiguas las primeras) (La misma tabla pero ordenando por id de las imágenes) Nos pasa lo mismo que con High WaterMark; una vez iniciado el proceso de migración si se usa es arriesgado usarlo. La solucción alternativa/final al problema es hacer lo que comentó Francisco Bocanegra Rodríguez, pero de forma dinámica en vez de forma estática, y usando los ids de entidades. Esto es, añadimos un método a la clase de tipo source: /** * Get the last id. * * Get the last id from the migration map table. * * @return int * Return the last id from the map table. */ private function getLastId(): int { $table_map = $this->idMap->mapTableName(); $connection = Database::getConnection('default', 'default'); $query = $connection->select($table_map, 'map'); $query->fields('map', ['sourceid1']); $query->orderBy('sourceid1', 'DESC'); $query->range(0,1); $result = $query->execute()->fe
Estoy con un proyecto que es una migración imporante, tanto por la importancia de la web como por el volumen de datos que se tienen que mover entre versiones, y la verdad es que mirando para atras entre el conocimiento de lo que sabía de las migraciones que había hecho antes con Drupal y lo que se ahora puede decir que es todo un mundo.
¿Cuál es el problema que le estoy viendo al framework de migraciones de Drupal?
Pues que sinceramente no lo veo pensado para grandes migraciones con las casuistícas que se tienen en la vida real.
Casuisticas de la vida real:
El servidor de desarrollo no es solo tuyo y no puede bloquear los despliegues mientras migras ergo una parte del día es para el resto de compañeros y la otra parte del día el servidor es tuyo, lo que supone lanzar migraciones a las 15.00 y tener que estar chequeando a las 20.00 y a las 23:50 para comprobar que todo va bien.
Los procesos de backups hacen de las suyas, y más cuando Cliente no es capaz de decirte cuando se lanza el backup sino que te dice una franja horaria estimadas (desde las 00:00 hasta las 04:00 de la madrugada).
También es cierto que el proyecto no es un proyecto cualquiera y tiene sus propias casuisticas:
- Archivos grandes, videos, audios, etc...
- Muchos archivos, cerca de 300.000 entradas en la tabla file_managed y subiendo.
- Muchos archivos duplicados, a día de hoy tenemos migrados 200k archivos de los cuales +70k archivos son duplicados (1)
- Usar la función hash_file te deja sin memoria, parece ser que hash_file no cierra al momento los archivos que abre y al usarla con muchos archivos, más los archivos propios que usa la app funcionando, etc... y puede terminar en un error de PHP de muchos archivos abiertos.
¿Qué retos nos hemos encontrado migrando volúmenos de datos tan grandes?
Lo primero es que se pueden lanzar migraciones controladasa por el flag "--limit=" (no recuerdo si viene en migration_tools o en migrations_plus), pero si lanzas una migración de 10k registros, y luego vuelves a lanzar otra migración de 10 registros, el proceso demigración de Drupal pasa primero por esos primeros 10k registros ya migrados y luego migra los siguientes 10k registros.
Existe una opción de configuración que es Highwater Marks, esta opción nos permite definir un campo, por ejemplo un campo timestamp, updated, created, etc....
Cual es la casuistica del proyecto de Cliente, pues que hace cargas masivas de archivos, lo que significa que si tenemos 30 archivos con el mismo timestamp y el proceso de migración no completa esos 30 archivos, sino que hace 15, la siguiente vez que migra empieza en el timestamp mayor que el último timestamp migrado por lo que se deja elementos sin migrar.
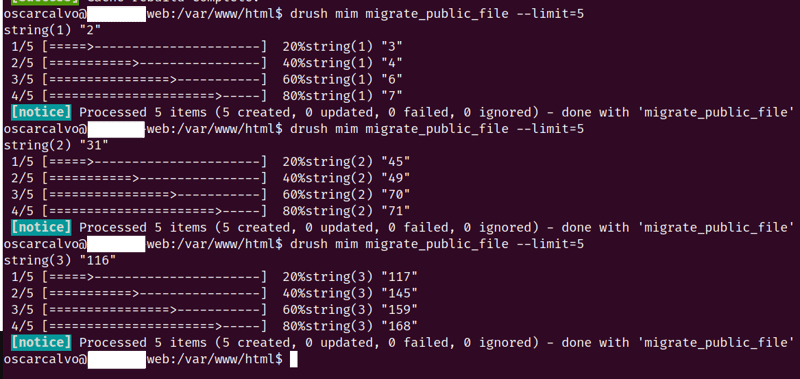
En esta foto, los números entre paréntesis son los fids, tienen grandes saltos por lo que he comentado, tenemos muchos archivos con el mismo timestamp ya que se dan tanto cargas masivas de imágenes como el uso de VBO para actualizar contenido.
Aquí que Ana María Picón Sánchez, vino con la idea de definir el fid en vez de un campo de tipo fecha en Highwater Marks, y si funciona, pero tiene el problema de que no sirve con los contenidos ya migrados, sino que empieza de cero a remigrar todo, y no es plan de decirle a Iñigo Gascon Royo que tenemos que lanzar otra vez toda la migración. Además de que por lo que sea de cuando en cuando nos da errores en las migraciones que posteriores migraciones se solucionan del tipo archivos que desaparecen, etc.
Otra solución a esto la dió Francisco Bocanegra Rodríguez, y es que como tenemos nuestro propio source para las migraciones, benditos custom sources, se puede indicar en las migraciones que se quiere migrar por lotes y controlar también lo que se migra mediante un condition indicando una fecha y decir que se migre todo lo anteior a esa fecha o todo lo posterior a esa fecha.
En una migración normal esto sería posible, pero para migrar la tabla de archivos nos encontramos de que no existe una correlación entre el timestamp y el fid.
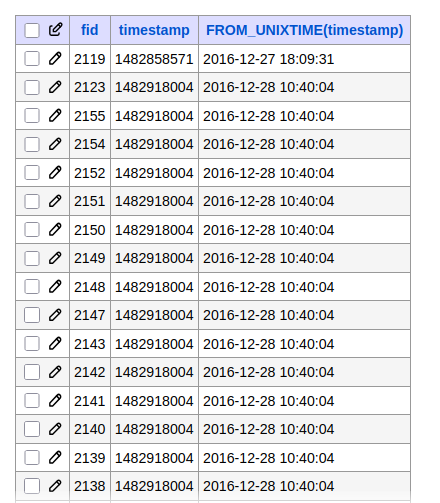
(En esta tabla ordenados las imágenes por la fecha, las más antiguas las primeras)
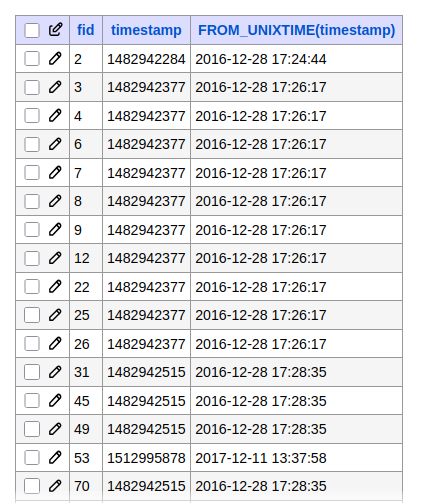
(La misma tabla pero ordenando por id de las imágenes)
Nos pasa lo mismo que con High WaterMark; una vez iniciado el proceso de migración si se usa es arriesgado usarlo.
La solucción alternativa/final al problema es hacer lo que comentó Francisco Bocanegra Rodríguez, pero de forma dinámica en vez de forma estática, y usando los ids de entidades.
Esto es, añadimos un método a la clase de tipo source:
/**
* Get the last id.
*
* Get the last id from the migration map table.
*
* @return int
* Return the last id from the map table.
*/
private function getLastId(): int {
$table_map = $this->idMap->mapTableName();
$connection = Database::getConnection('default', 'default');
$query = $connection->select($table_map, 'map');
$query->fields('map', ['sourceid1']);
$query->orderBy('sourceid1', 'DESC');
$query->range(0,1);
$result = $query->execute()->fetchAll();
return empty($result) ? (int) 0 : (int) reset($result)->sourceid1;
}
Y en el método query del plugin source añadimos:
static $last_id;
if(!isset($last_id)){
$last_id = $this->getLastId();
}
$query->condition('f.fid', $last_id, '>');
(1) Obviamente no se están migrando los archivos duplicados, se han creado una serie de plugin: process de migration para evitar esto, en cuanto el proyecto esté más encarrilado se cogerán un par de viernes para contribuirlos al módulo hash_file.









