


































































MCP Memory Bank
What is MCP For those following AI trends, since the last quarter of 2024 Anthropic has open-sourced a new protocol, called Model Context Protocol. For those who are not familiar with it: MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools. Since MCP’s release, I’ve experimented with potential MCP clients like Cline and Cursor. The issue A major issue with LLM agents is their lack of memory—each new discussion starts from scratch. You either would need to waste lots of time copy pasting context or manually fixing the same mistakes committed by agents when iterating with them. The solution One of Cline maintainers came up with a simple, but powerful solution: a memory bank. A simple way to give agents memory. The Cline team proposed a simple yet effective idea: using custom instructions to guide agents in writing and maintaining memory files for future reference. For those who don't know, custom instructions are a pattern commonly used in Cline, Cursor and Windsurf. It is a file that accepts text. Agents interacting with any of these clients will read this file, in theory before doing stuff (it might skip it eventually as agents are non-deterministic). Good models usually never skip the custom instructions by omission. You can read the whole file for a better understanding. TLDR: according to certain conditions, an agent should determine on how to create/maintain the following files: projectbrief.md is your foundation activeContext.md changes most often progress.md tracks milestones .clinerules captures learning These decisions would usually be decided by the agent itself and sometimes triggered by the user by prompting something like: "follow your customs instructions...." The files would therefore be written inside the repository being worked on. This is also a very similar pattern that is used by Aider. Aider has this feature out-of-the-box. The files are also written on the repository + gitignore is automatically updated to ignore the chat history files. I tried it I really enjoyed the idea from the Cline team as it was very simple and effective. With small .md files, well distributed, you should not need to worry about RAG, Vector search, etc. I started using it and the first thing that I did not like: The files sit on the repositories I personally don't like this as it pollutes the repos Other devs might dislike this, especially in team environments where tool use shouldn’t be mandatory. Use it with other clients Let's say I use Cline then want to jump to Claude, or Cursor. I cannot interoperate this memory bank with other clients easily. Consume/operate a memory bank remotely In distributed systems we might want to consume info from different layers of a system or a dedicated project just for special rules. Impossible to be done while the files sit in the repo related to the project My Idea While Cline’s approach works well, I saw an opportunity to extend it beyond a local repository-based solution—leading me to develop an MCP-based alternative. How I began: 1. Bootstrap a simple solution and make it work I created a two file solution, quite ugly, and made it work. I actually used AI to make it. Once done I managed to solve all of the aforementioned issues. But now new ideas came to life: Make the mcp server sharable with a whole team, allowing a team to consume and manage the same remote memory bank. Allow different types of integrations: databases, git (manage the memory bank directly through git operations, being a repository itself), etc Add new use cases (delete projects, files) that I did not create before Add RAG All of these ideas sparked a serious internal debate: I had to refactor this so it can grow. 2. Create a project. Time to wear the Tech Lead hat I have created a project, milestones and a roadmap. Overkill? Yeah! But I love it, affter working as a Senior software engineer owning/maintaining/evolving/pushing a full fledged FE technical roadmap at work, I really see the value of properly managing any project. Here is the public MCP server's project. Here is my repo: Memory Bank MCP 3. Fun time! Refactoring! After bootstrapping my project and publishing the server to npm, it was now time to start by the most important foundation: The Architecture. I chose Clean Architecture. Some might advocate that it is too verbose? For some it might, but I love it, and once you grasp its core idea, it’s great to work with. So this is how I divided the architecture: Domain Data Infra Presentation Validation Main I will not delve into this architectura
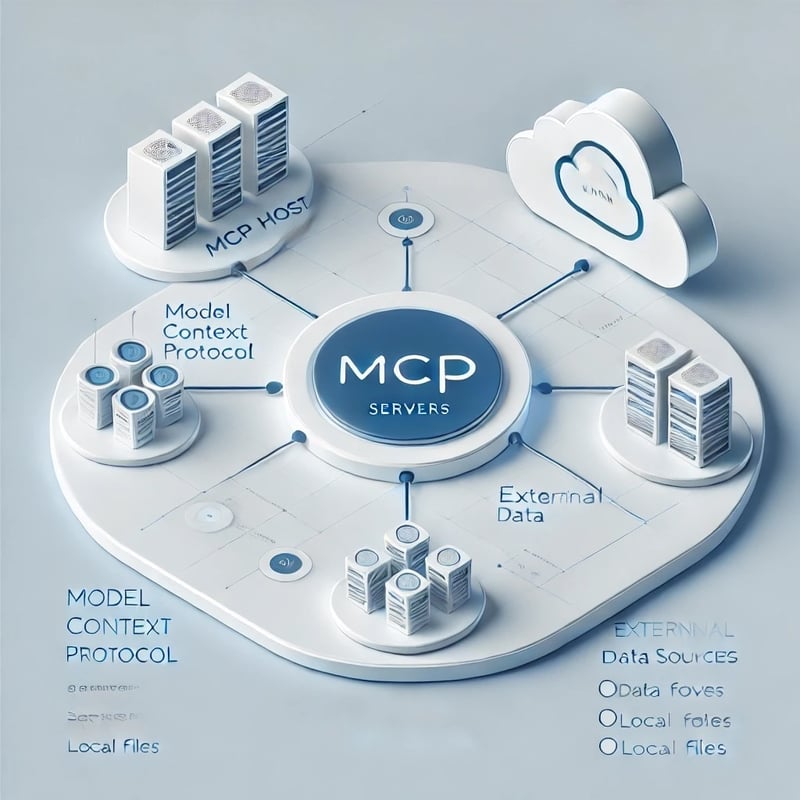
What is MCP
For those following AI trends, since the last quarter of 2024 Anthropic has open-sourced a new protocol, called Model Context Protocol. For those who are not familiar with it:
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
Since MCP’s release, I’ve experimented with potential MCP clients like Cline and Cursor.
The issue
A major issue with LLM agents is their lack of memory—each new discussion starts from scratch. You either would need to waste lots of time copy pasting context or manually fixing the same mistakes committed by agents when iterating with them.
The solution
One of Cline maintainers came up with a simple, but powerful solution: a memory bank. A simple way to give agents memory.
The Cline team proposed a simple yet effective idea: using custom instructions to guide agents in writing and maintaining memory files for future reference.
For those who don't know, custom instructions are a pattern commonly used in Cline, Cursor and Windsurf. It is a file that accepts text. Agents interacting with any of these clients will read this file, in theory before doing stuff (it might skip it eventually as agents are non-deterministic). Good models usually never skip the custom instructions by omission.
You can read the whole file for a better understanding. TLDR: according to certain conditions, an agent should determine on how to create/maintain the following files:
- projectbrief.md is your foundation
- activeContext.md changes most often
- progress.md tracks milestones
- .clinerules captures learning
These decisions would usually be decided by the agent itself and sometimes triggered by the user by prompting something like: "follow your customs instructions...."
The files would therefore be written inside the repository being worked on.
This is also a very similar pattern that is used by Aider. Aider has this feature out-of-the-box. The files are also written on the repository + gitignore is automatically updated to ignore the chat history files.
I tried it
I really enjoyed the idea from the Cline team as it was very simple and effective. With small .md files, well distributed, you should not need to worry about RAG, Vector search, etc.
I started using it and the first thing that I did not like:
The files sit on the repositories
I personally don't like this as it pollutes the repos
Other devs might dislike this, especially in team environments where tool use shouldn’t be mandatory.
Use it with other clients
Let's say I use Cline then want to jump to Claude, or Cursor. I cannot interoperate this memory bank with other clients easily.
Consume/operate a memory bank remotely
In distributed systems we might want to consume info from different layers of a system or a dedicated project just for special rules. Impossible to be done while the files sit in the repo related to the project
My Idea
While Cline’s approach works well, I saw an opportunity to extend it beyond a local repository-based solution—leading me to develop an MCP-based alternative.
How I began:
1. Bootstrap a simple solution and make it work
I created a two file solution, quite ugly, and made it work. I actually used AI to make it.
Once done I managed to solve all of the aforementioned issues.
But now new ideas came to life:
- Make the mcp server sharable with a whole team, allowing a team to consume and manage the same remote memory bank.
- Allow different types of integrations: databases, git (manage the memory bank directly through git operations, being a repository itself), etc
- Add new use cases (delete projects, files) that I did not create before
- Add RAG
All of these ideas sparked a serious internal debate: I had to refactor this so it can grow.
2. Create a project. Time to wear the Tech Lead hat
I have created a project, milestones and a roadmap. Overkill? Yeah! But I love it, affter working as a Senior software engineer owning/maintaining/evolving/pushing a full fledged FE technical roadmap at work, I really see the value of properly managing any project.
Here is the public MCP server's project.
Here is my repo: Memory Bank MCP
3. Fun time! Refactoring!
After bootstrapping my project and publishing the server to npm, it was now time to start by the most important foundation: The Architecture.
I chose Clean Architecture. Some might advocate that it is too verbose? For some it might, but I love it, and once you grasp its core idea, it’s great to work with.
So this is how I divided the architecture:
- Domain
- Data
- Infra
- Presentation
- Validation
- Main
I will not delve into this architectural pattern, but I really encourage anyone to study it, along side with other pattern, hexagonal, etc.
This is the issue I wrote with the help of AI (with my guidance, I am not a vibe coder xd)
I really enjoyed doing this refactor. The part I was eager about was to adapt the the presentation layer to the mcp layer. This can be seen under main/protocols/mcp.
The way these servers are done are very ugly. Instead of a router pattern like on what we see with Express for instance, with the MCP protocol what you will see everywhere is a primitive horrible switch case with hundreds of lines of code shoving "handlers" to the MCP Server request handler.
Another horrible thing is that when writing an MCP server we usually need to register the tools twice, which is also ugly.
Then there is the weird lack of association between a tool capability and a tool request handler.
I have addressed all of these, making the MCP protocol itself easily replaceable in the future.
I have created a way to address SOC regarding the tool registry + server registry
Router adapter:
It allows us to register a tool + capabilities in a way that will serve all the requirements of a MCP Server instantiation without spreading slope code all over the place.
import {
Request as MCPRequest,
ServerResult as MCPResponse,
Tool,
} from "@modelcontextprotocol/sdk/types.js";
export type MCPRequestHandler = (request: MCPRequest) => Promise;
export type MCPRoute = {
schema: Tool;
handler: Promise;
};
export class McpRouterAdapter {
private tools: Map = new Map();
public getToolHandler(name: string): MCPRoute["handler"] | undefined {
return this.tools.get(name)?.handler;
}
private mapTools(callback: (name: string) => any) {
return Array.from(this.tools.keys()).map(callback);
}
public getToolsSchemas() {
return Array.from(this.tools.keys()).map(
(name) => this.tools.get(name)?.schema
);
}
public getToolCapabilities() {
return Array.from(this.tools.keys()).reduce((acc, name: string) => {
acc[name] = this.tools.get(name)?.schema!;
return acc;
}, {} as Record);
}
public setTool({ schema, handler }: MCPRoute): McpRouterAdapter {
this.tools.set(schema.name, { schema, handler });
return this;
}
}
Request adapter
Here we are adapting our protocols, which do not depend on MCP, HTTP, or whatever comes later (Majors such as OpenAI will probably never implement MCP protocol, for instance) to MCP protocol so our controllers work with the MCP handlers:
export const adaptMcpRequestHandler = async <
T extends any,
R extends Error | any
>(
controller: Controller
): Promise => {
return async (request: MCPRequest): Promise => {
const { params } = request;
const body = params?.arguments as T;
const response = await controller.handle({
body,
});
const isError = response.statusCode < 200 || response.statusCode >= 300;
return {
tools: [],
isError,
content: [
{
type: "text",
text: isError
? JSON.stringify(serializeError(response.body))
: response.body?.toString(),
},
],
};
};
};
A route declaration. This means that when declaring a tool, we need to declare all metadata to be served as server capability, tool schema and it's handler.
router.setTool({
schema: {
name: "memory_bank_read",
description: "Read a memory bank file for a specific project",
inputSchema: {
type: "object",
properties: {
projectName: {
type: "string",
description: "The name of the project",
},
fileName: {
type: "string",
description: "The name of the file",
},
},
required: ["projectName", "fileName"],
},
},
handler: adaptMcpRequestHandler(makeReadController()),
});
Server Adapter
Here is a way that I found to abstract concrete implementations from the server while allowing my little adapted mcp routing framework to be injected here so we don't need to repeat on how the tools are declared and ditch the switch case approach for the request handling:
export class McpServerAdapter {
private server: Server | null = null;
constructor(private readonly mcpRouter: McpRouterAdapter) {}
public register({ name, version }: { name: string; version: string }) {
this.server = new Server(
{
name,
version,
},
{
capabilities: {
tools: this.mcpRouter.getToolCapabilities(),
},
}
);
this.server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools: this.mcpRouter.getToolsSchemas(),
}));
this.server.setRequestHandler(
CallToolRequestSchema,
async (request): Promise => {
const { name } = request.params;
const handler = await this.mcpRouter.getToolHandler(name);
if (!handler) {
throw new McpError(
ErrorCode.MethodNotFound,
`Tool ${name} not found`
);
}
return await handler(request);
}
);
}
async start(): Promise {
if (!this.server) {
throw new Error("Server not initialized");
}
const transport = new StdioServerTransport();
try {
await this.server.connect(transport);
console.log("Memory Bank MCP server running on stdio");
} catch (error) {
console.error(error);
}
}
}
In the end you have the app =)
import { McpServerAdapter } from "./adapters/mcp-server-adapter.js";
import routes from "./routes.js";
const router = routes();
const app = new McpServerAdapter(router);
app.register({
name: "memory-bank",
version: "1.0.0",
});
export default app;
Thanks for reading so far!
Here is my repo again if you wish to collaborate or check it out: Memory Bank MCP








