















.webp?#)
.webp?#)











































Llama 4: Meta’s MoE-Powered Multimodal Revolution
Meta’s Llama 4 marks a paradigm shift in open-weight AI, combining groundbreaking architecture with practical efficiency. As the first natively multimodal models in the Llama family, Scout and Maverick redefine what developers can achieve with open-source AI. Here’s what you need to know: Architecture: Efficiency Through Specialization Llama 4 adopts a sparse Mixture-of-Experts (MoE) design, where only a subset of parameters activates per query[5]. For example: Llama 4 Scout: 17B active parameters (109B total) with 16 experts, optimized for code and long-context tasks. Llama 4 Maverick: 17B active parameters (400B total) with 128 experts, excelling in multilingual and creative workflows[8]. This architecture routes tokens to specialized subnetworks (“experts”), reducing compute costs by ~83% compared to dense models like Llama 3[5]. For Maverick, this means GPT-4-level performance at 1/9th the cost per token[7]. The models also use early-fusion multimodality, processing text, images, and video frames as unified token sequences from the first layer[1][5]. Unlike previous models that chain vision/text components, this enables deeper cross-modal reasoning—like explaining UI flows using both code and screenshots[2]. 10M Tokens: Context Window Breakthrough Llama 4 Scout’s 10 million token context (≈5M words) is a quantum leap for code and data analysis[1][3]. To put this in perspective: It can ingest the Linux kernel (~7M tokens) and its documentation in one pass. Enables holistic codebase refactoring without recursive chunking. This is powered by iRoPE, an interleaved attention architecture that alternates between positional and non-positional layers to maintain coherence over extreme distances[7]. While initial deployments on platforms like Cloudflare currently cap contexts at 131K tokens, scaling to 10M is underway. Use Cases: Beyond Chatbots 1) Codebase Intelligence Scout’s long context allows architectural analysis of entire repositories. Imagine: # Analyze a 5M-token codebase in one pass context = load_entire_repo("my_project") response = llama4.scout_query( prompt="Find race conditions in this async code", context=context ) 2) Multilingual Multimodal Apps Maverick supports 12 languages and image/text fusion—ideal for global apps needing visual context (e.g., troubleshooting manuals with diagrams)[8]. 3) Cost-Efficient Inference MoE’s selective activation lets Scout run on a single H100 GPU, democratizing access to enterprise-scale AI. Why It Matters Llama 4 isn’t just another LLM—it’s a toolkit for reimagining AI workflows. The MoE design proves that bigger isn’t always better: smarter parameter utilization enables higher performance at lower costs. For developers, this means building previously impractical applications (like real-time monolith decomposition) without GPU clusters. As the open-source community iterates on these models, expect a surge in multimodal agents, cross-repo analysis tools, and AI-augmented IDEs. The future of AI isn’t just about scale—it’s about working smarter, and Llama 4 is leading the charge. Ready to experiment? Grab the models on Hugging Face and share your projects below! Sources: [1] https://azure.microsoft.com/en-us/blog/introducing-the-llama-4-herd-in-azure-ai-foundry-and-azure-databricks/ [2] https://dev.to/maxprilutskiy/llama-4-breaking-down-metas-latest-powerhouse-model-3k0p [3] https://www.youtube.com/watch?v=xCxuNE2wMPA [4] https://economictimes.com/tech/technology/how-to-use-metas-llama-4-a-quick-guide-for-developers-and-enterprises/articleshow/120031266.cms [5] https://blog.cloudflare.com/meta-llama-4-is-now-available-on-workers-ai/ [6] https://www.googlecloudcommunity.com/gc/Community-Blogs/Introducing-Llama-4-on-Vertex-AI/ba-p/892578 [7] https://apidog.com/blog/llama-4-api/ [8] https://www.together.ai/blog/llama-4 [9] https://venturebeat.com/ai/metas-answer-to-deepseek-is-here-llama-4-launches-with-long-context-scout-and-maverick-models-and-2t-parameter-behemoth-on-the-way/ [10] https://www.snowflake.com/en/blog/meta-llama-4-now-available-snowflake-cortex-ai/ [11] https://www.ibm.com/think/topics/context-window [12] https://groq.com/llama-4-now-live-on-groq-build-fast-at-the-lowest-cost-without-compromise/ [13] https://www.aboutamazon.com/news/aws/aws-meta-llama-4-models-available [14] https://codingscape.com/blog/llms-with-largest-context-windows [15] https://www.llama.com/developer-use-guide/ [16] https://www.databricks.com/blog/introducing-metas-llama-4-databricks-data-intelligence-platform [17] https://www.reddit.com/r/singularity/comments/1jsb7ug/do_you_think_llama_4_will_have_a_10_million_token/ [18] https://developers.redhat.com/articles/2025/04/05/llama-4-herd-here-day-zero-inference-support-vllm [19] https://www.llama.com [20] https://www.instagram.com/artificialintelligencenews.in/reel/DIFmw79oXXq/
Meta’s Llama 4 marks a paradigm shift in open-weight AI, combining groundbreaking architecture with practical efficiency. As the first natively multimodal models in the Llama family, Scout and Maverick redefine what developers can achieve with open-source AI. Here’s what you need to know:
Architecture: Efficiency Through Specialization
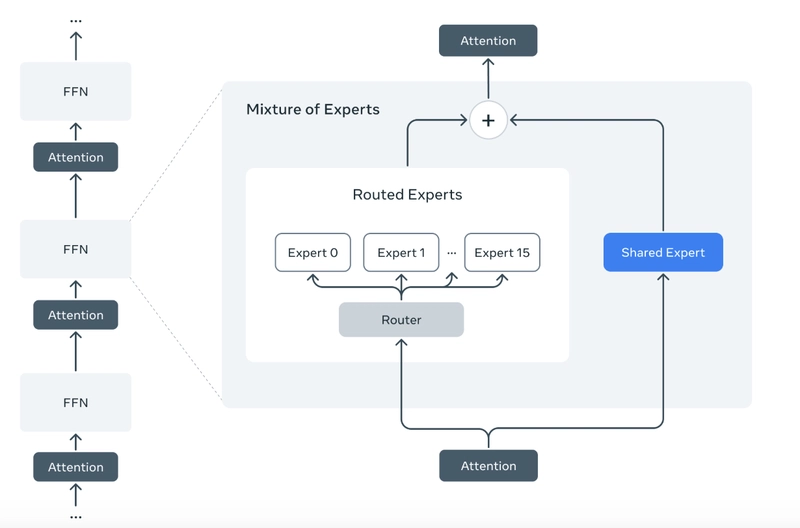
Llama 4 adopts a sparse Mixture-of-Experts (MoE) design, where only a subset of parameters activates per query[5]. For example:
- Llama 4 Scout: 17B active parameters (109B total) with 16 experts, optimized for code and long-context tasks.
- Llama 4 Maverick: 17B active parameters (400B total) with 128 experts, excelling in multilingual and creative workflows[8].
This architecture routes tokens to specialized subnetworks (“experts”), reducing compute costs by ~83% compared to dense models like Llama 3[5]. For Maverick, this means GPT-4-level performance at 1/9th the cost per token[7].
The models also use early-fusion multimodality, processing text, images, and video frames as unified token sequences from the first layer[1][5]. Unlike previous models that chain vision/text components, this enables deeper cross-modal reasoning—like explaining UI flows using both code and screenshots[2].
10M Tokens: Context Window Breakthrough
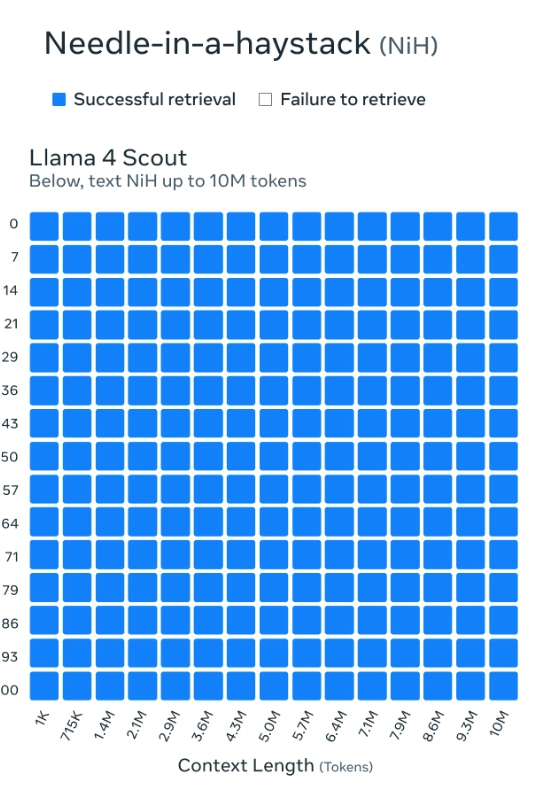
Llama 4 Scout’s 10 million token context (≈5M words) is a quantum leap for code and data analysis[1][3]. To put this in perspective:
- It can ingest the Linux kernel (~7M tokens) and its documentation in one pass.
- Enables holistic codebase refactoring without recursive chunking.
This is powered by iRoPE, an interleaved attention architecture that alternates between positional and non-positional layers to maintain coherence over extreme distances[7]. While initial deployments on platforms like Cloudflare currently cap contexts at 131K tokens, scaling to 10M is underway.
Use Cases: Beyond Chatbots
1) Codebase Intelligence
Scout’s long context allows architectural analysis of entire repositories. Imagine:
# Analyze a 5M-token codebase in one pass
context = load_entire_repo("my_project")
response = llama4.scout_query(
prompt="Find race conditions in this async code",
context=context
)
2) Multilingual Multimodal Apps
Maverick supports 12 languages and image/text fusion—ideal for global apps needing visual context (e.g., troubleshooting manuals with diagrams)[8].
3) Cost-Efficient Inference
MoE’s selective activation lets Scout run on a single H100 GPU, democratizing access to enterprise-scale AI.
Why It Matters
Llama 4 isn’t just another LLM—it’s a toolkit for reimagining AI workflows. The MoE design proves that bigger isn’t always better: smarter parameter utilization enables higher performance at lower costs. For developers, this means building previously impractical applications (like real-time monolith decomposition) without GPU clusters.
As the open-source community iterates on these models, expect a surge in multimodal agents, cross-repo analysis tools, and AI-augmented IDEs. The future of AI isn’t just about scale—it’s about working smarter, and Llama 4 is leading the charge.
Ready to experiment? Grab the models on Hugging Face and share your projects below!
Sources:
[1] https://azure.microsoft.com/en-us/blog/introducing-the-llama-4-herd-in-azure-ai-foundry-and-azure-databricks/
[2] https://dev.to/maxprilutskiy/llama-4-breaking-down-metas-latest-powerhouse-model-3k0p
[3] https://www.youtube.com/watch?v=xCxuNE2wMPA
[4] https://economictimes.com/tech/technology/how-to-use-metas-llama-4-a-quick-guide-for-developers-and-enterprises/articleshow/120031266.cms
[5] https://blog.cloudflare.com/meta-llama-4-is-now-available-on-workers-ai/
[6] https://www.googlecloudcommunity.com/gc/Community-Blogs/Introducing-Llama-4-on-Vertex-AI/ba-p/892578
[7] https://apidog.com/blog/llama-4-api/
[8] https://www.together.ai/blog/llama-4
[9] https://venturebeat.com/ai/metas-answer-to-deepseek-is-here-llama-4-launches-with-long-context-scout-and-maverick-models-and-2t-parameter-behemoth-on-the-way/
[10] https://www.snowflake.com/en/blog/meta-llama-4-now-available-snowflake-cortex-ai/
[11] https://www.ibm.com/think/topics/context-window
[12] https://groq.com/llama-4-now-live-on-groq-build-fast-at-the-lowest-cost-without-compromise/
[13] https://www.aboutamazon.com/news/aws/aws-meta-llama-4-models-available
[14] https://codingscape.com/blog/llms-with-largest-context-windows
[15] https://www.llama.com/developer-use-guide/
[16] https://www.databricks.com/blog/introducing-metas-llama-4-databricks-data-intelligence-platform
[17] https://www.reddit.com/r/singularity/comments/1jsb7ug/do_you_think_llama_4_will_have_a_10_million_token/
[18] https://developers.redhat.com/articles/2025/04/05/llama-4-herd-here-day-zero-inference-support-vllm
[19] https://www.llama.com
[20] https://www.instagram.com/artificialintelligencenews.in/reel/DIFmw79oXXq/









