































































Leveraging ServBay's Local AI Capabilities: Effortlessly Batch Translate Markdown Documents
Introduction In today's increasingly globalized world, the demand for multilingual content is exploding. Whether it's technical documentation, blog posts, research reports, or personal notes, translating them into different languages can significantly expand their audience and impact. However, traditional translation methods, such as manual translation, are costly and time-consuming. Using online translation services (like Google Translate, DeepL, etc.) might involve concerns about data privacy, API call fees, and network connectivity limitations. For developers, content creators, and tech enthusiasts seeking efficiency, data privacy, and cost-effectiveness, is there a way to perform high-quality batch translation locally, offline, and at a low cost? The answer is yes! With the maturation and popularization of local Large Language Model (LLM) technology, we can now run powerful AI models on our own computers to accomplish various tasks, including text translation. And for ServBay users, this becomes even simpler and more integrated. ServBay, as a powerful integrated Web development environment, not only provides convenient management of web servers, databases, and language environments but its latest version also keeps pace with technological trends by incorporating built-in support for AI/LLM, specifically integrating the popular Ollama framework. This means you can easily deploy and manage local AI models within the ServBay environment without complex configurations and leverage their powerful capabilities. This tutorial, based on ServBay, will guide you in detail on how to: Understand ServBay's latest AI/LLM support, particularly its integrated Ollama features. Easily install and configure the Ollama service within ServBay. Search, download, and manage Ollama models suitable for translation tasks through ServBay's graphical interface. Write a Python script that utilizes the Ollama API endpoint provided by ServBay to automate the batch translation of all Markdown (.md) files within a specified folder (e.g., docs). Through this tutorial, you will master a powerful, private, and efficient local document translation solution, fully unleashing the potential of ServBay and local AI. Let's embark on this exciting local AI journey! Part 1: ServBay's AI / LLM New Era: Embracing Local Intelligence ServBay has always been committed to providing developers with a one-stop, efficient, and convenient local development environment. From managing multiple versions of PHP, Python, Java, .Net, Node.js, switching between Nginx/Apache/Caddy, to supporting MySQL/PostgreSQL/MongoDB databases, ServBay greatly simplifies the setup and maintenance of development environments. Now, ServBay is once again at the forefront, integrating powerful AI/LLM capabilities into its core features, opening a new chapter of local intelligence for its users. Integrating Ollama: The Swiss Army Knife for Local LLMs The core of ServBay's AI functionality is the integration of Ollama. Ollama is an open-source project designed to enable users to easily run large language models like Llama 3, Mistral, Phi-3, Gemma3, etc., locally. It significantly simplifies the process of setting up, running, and managing models, providing a standard API interface that allows developers to interact with local models as conveniently as calling cloud services. ServBay's integration of Ollama brings numerous advantages: One-Click Installation and Configuration: ServBay provides a dedicated graphical interface to manage Ollama. Users don't need to manually download Ollama, configure environment variables, or manage complex dependencies. Simply enable and configure it briefly in ServBay's AI panel, and you have a ready-to-use local LLM service. Visual Configuration Management: ServBay offers rich configuration options, such as Model Download Threads, Bind IP, Bind Port (defaults to 127.0.0.1:11434, the standard Ollama configuration), debug switches (Debug, Flash Attention, No History, No Prune, Schedule Spread, Multi-user Cache), cache type (K/V Cache Type), GPU optimization (GPU Overhead), connection persistence (Keepalive), load timeout (Load Timeout), maximum loaded models (Max loaded models), maximum queue (Max Queue), parallel processing number (Parallel Num.), LLM library path (LLM Library), model storage path (Models folder), and access origin control (origins). This allows users to fine-tune Ollama's runtime parameters based on their hardware and needs without memorizing command-line arguments. Unified Ecosystem: Integrating Ollama into ServBay means your web development environment and AI inference environment can work together under the same management platform. This provides great convenience for developing web applications that require AI functions (such as intelligent customer service, content generation, local data analysis, etc.). Convenient Model Management Just having a running framewor
Introduction
In today's increasingly globalized world, the demand for multilingual content is exploding. Whether it's technical documentation, blog posts, research reports, or personal notes, translating them into different languages can significantly expand their audience and impact. However, traditional translation methods, such as manual translation, are costly and time-consuming. Using online translation services (like Google Translate, DeepL, etc.) might involve concerns about data privacy, API call fees, and network connectivity limitations.
For developers, content creators, and tech enthusiasts seeking efficiency, data privacy, and cost-effectiveness, is there a way to perform high-quality batch translation locally, offline, and at a low cost? The answer is yes! With the maturation and popularization of local Large Language Model (LLM) technology, we can now run powerful AI models on our own computers to accomplish various tasks, including text translation.
And for ServBay users, this becomes even simpler and more integrated. ServBay, as a powerful integrated Web development environment, not only provides convenient management of web servers, databases, and language environments but its latest version also keeps pace with technological trends by incorporating built-in support for AI/LLM, specifically integrating the popular Ollama framework. This means you can easily deploy and manage local AI models within the ServBay environment without complex configurations and leverage their powerful capabilities.
This tutorial, based on ServBay, will guide you in detail on how to:
- Understand ServBay's latest AI/LLM support, particularly its integrated Ollama features.
- Easily install and configure the Ollama service within ServBay.
- Search, download, and manage Ollama models suitable for translation tasks through ServBay's graphical interface.
- Write a Python script that utilizes the Ollama API endpoint provided by ServBay to automate the batch translation of all Markdown (
.md) files within a specified folder (e.g.,docs).
Through this tutorial, you will master a powerful, private, and efficient local document translation solution, fully unleashing the potential of ServBay and local AI. Let's embark on this exciting local AI journey!
Part 1: ServBay's AI / LLM New Era: Embracing Local Intelligence
ServBay has always been committed to providing developers with a one-stop, efficient, and convenient local development environment. From managing multiple versions of PHP, Python, Java, .Net, Node.js, switching between Nginx/Apache/Caddy, to supporting MySQL/PostgreSQL/MongoDB databases, ServBay greatly simplifies the setup and maintenance of development environments. Now, ServBay is once again at the forefront, integrating powerful AI/LLM capabilities into its core features, opening a new chapter of local intelligence for its users.
Integrating Ollama: The Swiss Army Knife for Local LLMs
The core of ServBay's AI functionality is the integration of Ollama. Ollama is an open-source project designed to enable users to easily run large language models like Llama 3, Mistral, Phi-3, Gemma3, etc., locally. It significantly simplifies the process of setting up, running, and managing models, providing a standard API interface that allows developers to interact with local models as conveniently as calling cloud services.
ServBay's integration of Ollama brings numerous advantages:
- One-Click Installation and Configuration: ServBay provides a dedicated graphical interface to manage Ollama. Users don't need to manually download Ollama, configure environment variables, or manage complex dependencies. Simply enable and configure it briefly in ServBay's AI panel, and you have a ready-to-use local LLM service.
- Visual Configuration Management: ServBay offers rich configuration options, such as
Model Download Threads,Bind IP,Bind Port(defaults to127.0.0.1:11434, the standard Ollama configuration), debug switches (Debug,Flash Attention,No History,No Prune,Schedule Spread,Multi-user Cache), cache type (K/V Cache Type), GPU optimization (GPU Overhead), connection persistence (Keepalive), load timeout (Load Timeout), maximum loaded models (Max loaded models), maximum queue (Max Queue), parallel processing number (Parallel Num.), LLM library path (LLM Library), model storage path (Models folder), and access origin control (origins). This allows users to fine-tune Ollama's runtime parameters based on their hardware and needs without memorizing command-line arguments. - Unified Ecosystem: Integrating Ollama into ServBay means your web development environment and AI inference environment can work together under the same management platform. This provides great convenience for developing web applications that require AI functions (such as intelligent customer service, content generation, local data analysis, etc.).
Convenient Model Management
Just having a running framework isn't enough; selecting and managing appropriate AI models is equally important. ServBay excels in this area as well:
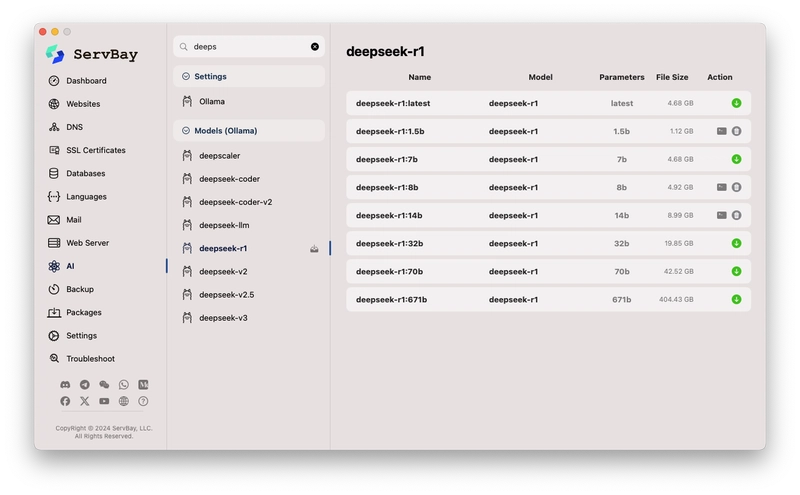
- Model Listing and Search: ServBay provides a model list interface where users can directly search for available models in the official Ollama model library (e.g., the screenshot shows searching for
deepsdisplaying different versions ofdeepseek-r1). - One-Click Download and Deletion: For searched models, the interface clearly displays the model name (including tags like
latest,1.5b,7b, etc.), base model, number of parameters (Parameters), file size (File Size), and action buttons (download+or delete). Users simply click a button, and ServBay automatically handles the download and storage of the model (the storage path can be specified in the Ollama configuration, defaulting to/Applications/ServBay/db/ollama/models). - Local Model Overview: In the
Ollama Configinterface (first screenshot), the left-side list shows the models currently downloaded locally (e.g.,alfred,all-minilm,codellama, etc.). This gives users a clear overview of the local AI "brains" they possess.
Core Value of Local AI
Why use local AI (via Ollama in ServBay) for translation instead of continuing with online services?
- Data Privacy and Security: This is the most crucial advantage. All data processing is done on your own computer; your document content doesn't need to be sent to any third-party servers. This is essential for documents containing sensitive information or trade secrets.
- Cost-Effectiveness: Running LLMs locally incurs no API call fees. While there might be an initial hardware investment (especially if GPU acceleration is needed), the long-term cost for large or frequent tasks is far lower than pay-as-you-go cloud services.
- Offline Availability: Once a model is downloaded locally, you can perform translation or other AI tasks without an internet connection, which is very useful in environments with unstable networks or scenarios requiring complete offline operation.
- Customization and Control: You have the freedom to choose the model best suited for your task and hardware, experiment with different model versions and parameters, and even perform fine-tuning (although ServBay itself doesn't directly provide fine-tuning features, the localized Ollama environment lays the foundation for it).
- Low Latency: Requests are sent directly to the locally running service, typically resulting in lower latency and faster responses compared to calling remote APIs over the internet.
In summary, by integrating Ollama, ServBay significantly lowers the barrier for users to utilize local large language models, seamlessly incorporating their powerful AI capabilities into a familiar development environment, providing a solid foundation for implementing advanced automation tasks like batch document translation.
Part 2: Installing and Configuring Ollama and Models in ServBay
Now, let's walk through setting up the Ollama service in ServBay step-by-step and download a model suitable for translation tasks.
Step 1: Navigate to ServBay's AI Configuration
- Launch the ServBay application.
- In the left-hand navigation bar of the ServBay main interface, find and click AI.
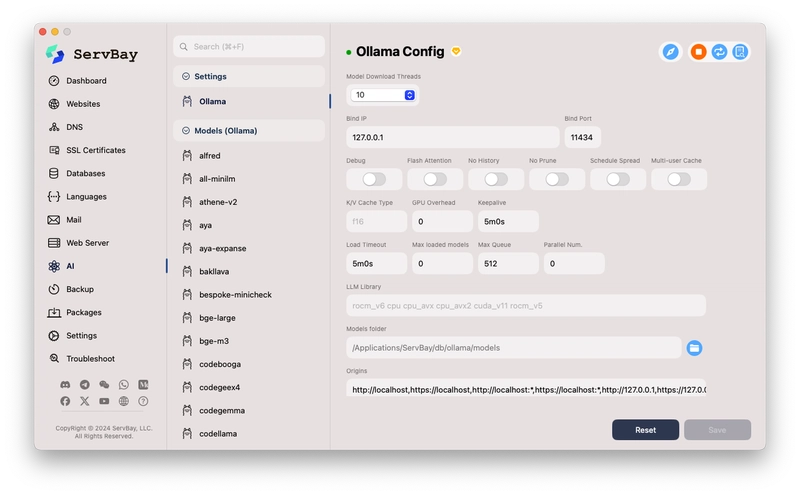
- In the AI sub-menu, click Ollama. You should see an interface similar to the
Ollama Configshown in the first screenshot.
Step 2: Check and (Optionally) Adjust Ollama Configuration
ServBay usually provides a reasonable set of default configurations, often sufficient for initial use or basic tasks. However, understanding these options helps with future optimization:
- Ollama Service Status: There is usually a toggle switch or status indicator at the top of the interface (a green dot in the screenshot). Ensure the Ollama service is enabled. If ServBay provides Start/Stop buttons, make sure it's running.
- Bind IP and Bind Port: The defaults
127.0.0.1and11434are standard configurations, meaning the Ollama service listens only for requests from the local machine on port 11434. This is the address our Python script will need to connect to later. Usually, no changes are needed. - Models folder: This is the path where downloaded LLM models are stored. The screenshot shows
/Applications/ServBay/db/ollama/models. You can change this to another location with sufficient disk space if needed, but ensure the path exists and ServBay has write permissions. Note this path; although the script doesn't use it directly, knowing where the models are is helpful. - Model Download Threads: The number of concurrent threads used when downloading models. If you have a good network connection, you can increase this slightly to speed up downloads. The default is 10.
- Other Options (e.g., GPU Overhead, Max loaded models, etc.): These are more advanced performance tuning options. If you have a compatible GPU (NVIDIA or Apple Silicon), Ollama usually detects and uses it automatically.
Max loaded modelslimits the number of models loaded into memory/VRAM simultaneously, depending on your RAM/VRAM size. For batch translation tasks, usually only one model is loaded at a time, so the default value is generally sufficient. - Origins: This is the CORS (Cross-Origin Resource Sharing) setting, controlling which web pages (origins) can access the Ollama API. The default includes various variations of
http://localhostandhttp://127.0.0.1, which is usually sufficient for local scripts or local web applications.
Important Note: If you modify any configuration, be sure to click the Save button in the lower right corner of the interface to apply the changes. If you encounter problems, you can try clicking Reset to restore the default settings.
Step 3: Navigate to the Model Management Interface
- In the left-hand navigation bar of ServBay, under the AI category, click Models (Ollama).
- You will see a model management interface similar to the second screenshot. This lists models available for download and those already installed locally.
Step 4: Search for and Download a Translation Model
Now we need to select and download an LLM suitable for translation tasks. An LLM's translation capability is often related to its general instruction-following ability and multilingual training data. Some good choices might include (as of writing):
- Llama 3 series (e.g.,
llama3:8b): Meta AI's latest open-source model, with strong general capabilities and good instruction following, usually handles translation tasks well. The 8B version has relatively moderate hardware requirements. - Mistral series (e.g.,
mistral:7b): Another very popular high-performance open-source model known for its efficiency. - DeepSeek Coder/LLM series (e.g.,
deepseek-llm:7b-chat): Although DeepSeek is known for its coding abilities, its general chat models usually also possess translation capabilities. Thedeepseek-r1in the screenshot might be one of its variants or a specific version. - Specialized Translation Models (if available in the Ollama library): Sometimes there are models specifically optimized for translation, but strong general instruction-following models often perform very well too.
Performing Search and Download:
- In the search box at the top of the model management interface, enter the name of the model you want to find, e.g.,
llama3ormistral. - The interface will dynamically display a list of matching models, including different parameter sizes (like 7b, 8b, 70b, etc.) and tags (like
latest,instruct,chat). - Considerations when selecting a model:
-
Parameters: Such as
7b(7 billion),8b(8 billion),70b(70 billion). Larger parameter counts usually mean stronger capabilities but also higher requirements for memory (RAM) and video memory (VRAM), and slower inference speed. For batch translation, a7bor8bmodel is often a good starting point, balancing performance and resource consumption. -
Tags: Models tagged
instructorchatare usually better at following instructions (like "Please translate the following text into..."). - File Size: Note that model files can be large (from several GB to tens of GB). Ensure you have sufficient disk space.
-
Parameters: Such as
- Find the model version you want to download (e.g.,
llama3:8b) and click the download icon next to it (usually a downward arrow). - ServBay will start downloading the model. You can see the download progress. The download time depends on your network speed and the model size.
Step 5: Verify Model Installation
Once the model download is complete, it should appear in the list of installed models on the left side of the Ollama Config interface. Also, in the Models (Ollama) interface, the action button for that model might change to a delete icon (


