





















































From Words to Vectors: A Gentle Introduction to Word Embeddings
Have you ever wondered how computers can understand and process human language? We effortlessly grasp the meaning of words and sentences, but for a machine, text is just a sequence of characters. This is where word embeddings come into play. They are a cornerstone of modern Natural Language Processing (NLP), acting as a bridge that translates our rich, nuanced language into a format that machines can comprehend and manipulate effectively. Imagine trying to explain the concept of "happiness" to a computer. You can't just show it a picture. You need to represent it in a way the machine can process numerically. Word embeddings achieve this by transforming words into dense vectors of numbers. But these aren't just random numbers; they are carefully crafted to capture the meaning and context of words. In this article, we'll demystify word embeddings, exploring what they are, how they work, and why they've become so crucial in the world of AI. Understanding Word Embeddings: Meaning in Numbers At their heart, word embeddings are numerical representations of words in a continuous vector space. Think of it like a map where each word is a point. Words with similar meanings are located closer together on this map, while words with dissimilar meanings are further apart. Let's take a simple example. Consider the words "king," "queen," "man," and "woman." In a well-trained word embedding space: "King" and "queen" would be relatively close to each other, as they both represent royalty. "Man" and "woman" would also be near each other, sharing the concept of gender. "King" and "man," as well as "queen" and "woman," would be even closer, reflecting the male/female relationship within royalty. This spatial arrangement is crucial because it allows machine learning models to understand semantic relationships between words. Instead of treating words as isolated, discrete units, embeddings reveal their connections and nuances. How Do Word Embeddings Work? Learning Meaning from Context The magic of word embeddings lies in their ability to learn these meaningful vector representations from vast amounts of text data. Instead of relying on hand-crafted rules or dictionaries, algorithms learn to associate words based on the contexts in which they appear. 1. One-Hot Encoding: The Starting Point (and its Limitations) Before the advent of embeddings, a common way to represent words was one-hot encoding. Imagine you have a vocabulary of four words: "cat," "dog," "fish," "bird." One-hot encoding would represent each word as a vector of length four, with a '1' at the index corresponding to the word and '0's everywhere else: "cat": [1, 0, 0, 0] "dog": [0, 1, 0, 0] "fish": [0, 0, 1, 0] "bird": [0, 0, 0, 1] Limitations of One-Hot Encoding: High Dimensionality: For a large vocabulary, the vectors become extremely long and sparse, leading to computational inefficiency. No Semantic Meaning: Crucially, one-hot encoding fails to capture any relationships between words. The vectors for "cat" and "dog" are just as distant as "cat" and "house," even though "cat" and "dog" are semantically related. 2. Word Embeddings: Learning Meaningful Vectors Word embeddings overcome these limitations by creating dense, low-dimensional vectors that encode semantic meaning. Several techniques exist, but let's explore some of the most influential: Word2Vec: Predicting Context Developed by Google, Word2Vec is a groundbreaking algorithm that learns word embeddings by predicting surrounding words in a sentence. It comes in two main architectures: Continuous Bag of Words (CBOW): Predicts a target word based on the context of surrounding words. For example, given the context "the fluffy brown," it might predict the target word "cat." Skip-gram: Works in reverse. Given a target word, it predicts the surrounding context words. For instance, given "cat," it might predict "the," "fluffy," and "brown." Both CBOW and Skip-gram are trained on massive text datasets. During training, the models adjust the word vectors so that words appearing in similar contexts end up having similar vectors. Example of vector arithmetic: Vector("King") - Vector("Man") + Vector("Woman") ≈ Vector("Queen") This shows that the embedding space has learned to represent the relationships between gender and royalty! GloVe (Global Vectors for Word Representation): Leveraging Co-occurrence GloVe, developed at Stanford, takes a different approach. Instead of focusing on local context windows like Word2Vec, GloVe leverages global word co-occurrence statistics from the entire corpus. It constructs a word co-occurrence matrix, which counts how often words appear together in a given context. GloVe then factorizes this matrix to learn word embeddings that capture these global co-occurrence patterns. FastText: Embracing Subword Information FastText, developed by Fa

Have you ever wondered how computers can understand and process human language? We effortlessly grasp the meaning of words and sentences, but for a machine, text is just a sequence of characters. This is where word embeddings come into play. They are a cornerstone of modern Natural Language Processing (NLP), acting as a bridge that translates our rich, nuanced language into a format that machines can comprehend and manipulate effectively.
Imagine trying to explain the concept of "happiness" to a computer. You can't just show it a picture. You need to represent it in a way the machine can process numerically. Word embeddings achieve this by transforming words into dense vectors of numbers. But these aren't just random numbers; they are carefully crafted to capture the meaning and context of words.
In this article, we'll demystify word embeddings, exploring what they are, how they work, and why they've become so crucial in the world of AI.
Understanding Word Embeddings: Meaning in Numbers
At their heart, word embeddings are numerical representations of words in a continuous vector space. Think of it like a map where each word is a point. Words with similar meanings are located closer together on this map, while words with dissimilar meanings are further apart.
Let's take a simple example. Consider the words "king," "queen," "man," and "woman." In a well-trained word embedding space:
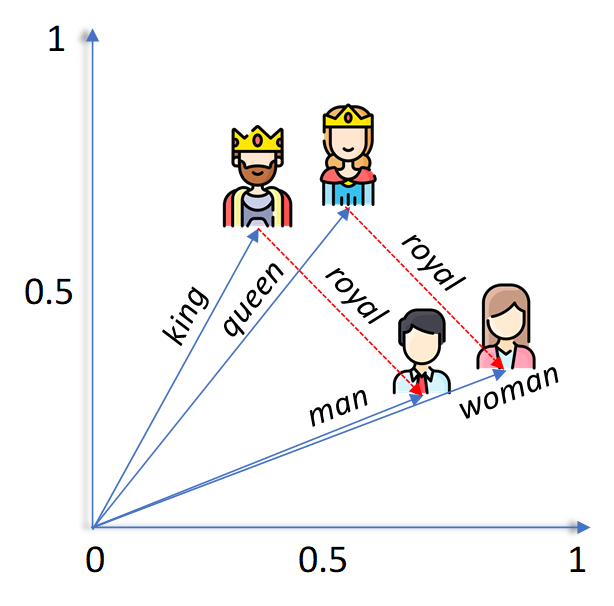
- "King" and "queen" would be relatively close to each other, as they both represent royalty.
- "Man" and "woman" would also be near each other, sharing the concept of gender.
- "King" and "man," as well as "queen" and "woman," would be even closer, reflecting the male/female relationship within royalty.
This spatial arrangement is crucial because it allows machine learning models to understand semantic relationships between words. Instead of treating words as isolated, discrete units, embeddings reveal their connections and nuances.
How Do Word Embeddings Work? Learning Meaning from Context
The magic of word embeddings lies in their ability to learn these meaningful vector representations from vast amounts of text data. Instead of relying on hand-crafted rules or dictionaries, algorithms learn to associate words based on the contexts in which they appear.
1. One-Hot Encoding: The Starting Point (and its Limitations)
Before the advent of embeddings, a common way to represent words was one-hot encoding. Imagine you have a vocabulary of four words: "cat," "dog," "fish," "bird." One-hot encoding would represent each word as a vector of length four, with a '1' at the index corresponding to the word and '0's everywhere else:
"cat": [1, 0, 0, 0]
"dog": [0, 1, 0, 0]
"fish": [0, 0, 1, 0]
"bird": [0, 0, 0, 1]
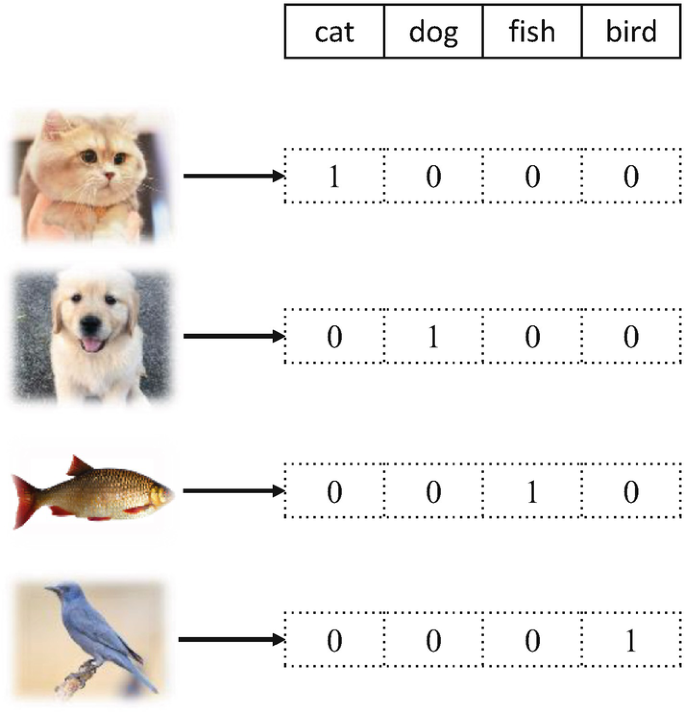
Limitations of One-Hot Encoding:
- High Dimensionality: For a large vocabulary, the vectors become extremely long and sparse, leading to computational inefficiency.
- No Semantic Meaning: Crucially, one-hot encoding fails to capture any relationships between words. The vectors for "cat" and "dog" are just as distant as "cat" and "house," even though "cat" and "dog" are semantically related.
2. Word Embeddings: Learning Meaningful Vectors
Word embeddings overcome these limitations by creating dense, low-dimensional vectors that encode semantic meaning. Several techniques exist, but let's explore some of the most influential:
Word2Vec: Predicting Context
Developed by Google, Word2Vec is a groundbreaking algorithm that learns word embeddings by predicting surrounding words in a sentence. It comes in two main architectures:
- Continuous Bag of Words (CBOW): Predicts a target word based on the context of surrounding words. For example, given the context "the fluffy brown," it might predict the target word "cat."
- Skip-gram: Works in reverse. Given a target word, it predicts the surrounding context words. For instance, given "cat," it might predict "the," "fluffy," and "brown."
Both CBOW and Skip-gram are trained on massive text datasets. During training, the models adjust the word vectors so that words appearing in similar contexts end up having similar vectors.
Example of vector arithmetic:
Vector("King") - Vector("Man") + Vector("Woman") ≈ Vector("Queen")
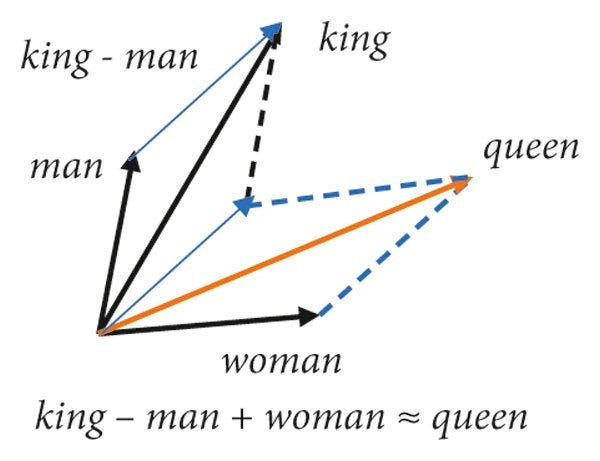
This shows that the embedding space has learned to represent the relationships between gender and royalty!
GloVe (Global Vectors for Word Representation): Leveraging Co-occurrence
GloVe, developed at Stanford, takes a different approach. Instead of focusing on local context windows like Word2Vec, GloVe leverages global word co-occurrence statistics from the entire corpus. It constructs a word co-occurrence matrix, which counts how often words appear together in a given context. GloVe then factorizes this matrix to learn word embeddings that capture these global co-occurrence patterns.
FastText: Embracing Subword Information
FastText, developed by Facebook, is an extension of Word2Vec that addresses some of its limitations, particularly for morphologically rich languages and handling out-of-vocabulary words.
FastText considers words as being composed of character n-grams (subword units). For example, the word "apple" can be broken down into n-grams like "ap," "pp," "pl," "le," "app," "pple," etc. This subword information makes FastText more robust to unseen words and beneficial for languages with complex word structures.
3. Contextual Embeddings in Modern LLMs
While Word2Vec, GloVe, and FastText were revolutionary in their time, the landscape of word embeddings has significantly evolved, especially with the rise of Large Language Models (LLMs) such as Llama and others.
Contextual Embeddings:
Unlike the static embeddings of Word2Vec or GloVe, contextual embeddings are dynamic. The vector representation of a word changes depending on the sentence and surrounding words in which it appears. This is made possible by transformer architectures and their powerful attention mechanisms.
For example, consider the word "bank":
- In "I went to the bank to deposit money," "bank" refers to a financial institution.
- In "We sat by the riverbank," "bank" refers to the edge of a river.
Traditional embeddings would give "bank" the same vector in both cases, but contextual embeddings adjust dynamically based on context, improving AI understanding of natural language.
Conclusion: The Power of Representation, Evolving into the Future
Word embeddings have revolutionized NLP by transforming words into meaningful numerical vectors, empowering machines to understand, process, and generate human language with unprecedented accuracy.
While traditional methods like Word2Vec, GloVe, and FastText laid the foundation, the current era is dominated by contextual embeddings within LLMs. These dynamic representations, enhanced by advanced training techniques, are pushing the boundaries of AI's language understanding capabilities.
If you're curious to dive deeper, consider experimenting with pre-trained word embeddings from models like Llama using libraries like Hugging Face Transformers. The world of word embeddings is rich, constantly evolving, and offers incredible opportunities to explore the fascinating intersection of language and artificial intelligence.