Elite Performance Is Wasted on Feature Factories
The whole point of achieving this performance level is to run more experiments with high confidence so your organization can learn more. Being an elite performer in DevOps means you can deploy early and often with low failure rates and fast recovery when things go wrong. It takes some serious dedication to technical practices and cultural capabilities, so if all you’re going to do is run the feature factory faster, you could be wasting your time. The whole point of achieving this performance level is to run more experiments with high confidence so your organization can learn more. What Is Elite Performance? The “elite performers” concept comes from the Accelerate State of DevOps Report, which groups performance into clusters based on software delivery performance. The top performers are able to deploy many times a day, with lead time for changes under an hour. They also have the lowest change failure rate and fastest recovery times. You can’t achieve this performance level for both throughput and stability without embedding the technical practices of continuous delivery in your organization. You need automated tests with managed test data, a loosely coupled architecture and deployment automation. It takes time to get good at these kinds of skills, so elite performance represents a serious undertaking. That’s why you need to make sure your organization is in a position to use this level of software delivery performance. That means moving away from feature-driven thinking to an experiment-based approach. Let’s look at feature-driven and experiment-based teams through the magic of our imagination. What if software delivery performance was so high it removed the constraint, giving us effectively infinite capacity? The Infinite Feature Team Feature factories work by queuing a roadmap of features that come from customer requests and internal moments of inspiration. There are always more feature requests than there is time to deliver them. If a feature-driven team could deliver features faster than the ideas arrive, they would simply produce features for each demand. The software would do practically anything and would have some mechanism that allows each user to configure the software to work in the way they want. When you fall into the trap of delivering every feature request, the software you produce fails. It collapses under its own weight, with users not understanding their own configurations. Having infinite capacity to deliver features would simply make it fail sooner. In the case of feature factories, not being able to deliver every request is the one thing saving them from failure. They survive a lack of product management because the backlog of work forces them to choose from an infinite list of options. Without this pressure to choose, the good features get drowned by the bad. Simply put, more features and more code do nothing to increase the value of software. This kind of software lacks the one thing that’s really valuable: a strong opinion. What about experiment-based approaches? The Infinite Experiment Team Experimental teams use techniques such as impact mapping to decide on goals and generate experiments to discover what will move them closer to each goal. With no constraints, an experimental team would maximize learning. They would try many alternative ideas to discover the best approach and could revisit what they learned from previous experiments to see if the results were still valid. Part of an experimental team’s DNA is removing things that don’t work. They might add an upsell screen to a checkout process to increase sales, but walk back on this if it increased abandoned shopping baskets with more value than the upsells. The process of experimentation requires a balance of sequential and simultaneous measurement. You don’t want to change many things at once, but you usually need to measure the current software against the proposed idea at the same time to avoid disruption from time-based events and seasonality. Experimental teams would gain more learning from an infinite capacity, which would be incredibly valuable. Elite performance is useful when it gets you fast high-quality feedback, not when it just means more features. Continuous Delivery Gets You Fast Feedback In the white paper “The Importance of Continuous Delivery,” I described how the technical practices of continuous delivery contribute to shorter feedback cycles. The goal of CD isn’t to create more features but more impact. Short feedback loops help in many ways. They decrease risk, reduce rework and improve well-being. Frequent feedback also maximizes learning, increases time spent on new work and makes you more likely to meet and exceed your goals. Everyone uses proxy-feedback loops as interim validation of changes, for example, internal testing. But the only meaningful feedback comes from getting the software to real users. When you work in large batches,
The whole point of achieving this performance level is to run more experiments with high confidence so your organization can learn more.
Being an elite performer in DevOps means you can deploy early and often with low failure rates and fast recovery when things go wrong. It takes some serious dedication to technical practices and cultural capabilities, so if all you’re going to do is run the feature factory faster, you could be wasting your time.
The whole point of achieving this performance level is to run more experiments with high confidence so your organization can learn more.
What Is Elite Performance?
The “elite performers” concept comes from the Accelerate State of DevOps Report, which groups performance into clusters based on software delivery performance. The top performers are able to deploy many times a day, with lead time for changes under an hour. They also have the lowest change failure rate and fastest recovery times.
You can’t achieve this performance level for both throughput and stability without embedding the technical practices of continuous delivery in your organization. You need automated tests with managed test data, a loosely coupled architecture and deployment automation.
It takes time to get good at these kinds of skills, so elite performance represents a serious undertaking. That’s why you need to make sure your organization is in a position to use this level of software delivery performance. That means moving away from feature-driven thinking to an experiment-based approach.
Let’s look at feature-driven and experiment-based teams through the magic of our imagination. What if software delivery performance was so high it removed the constraint, giving us effectively infinite capacity?
The Infinite Feature Team
Feature factories work by queuing a roadmap of features that come from customer requests and internal moments of inspiration. There are always more feature requests than there is time to deliver them.
If a feature-driven team could deliver features faster than the ideas arrive, they would simply produce features for each demand. The software would do practically anything and would have some mechanism that allows each user to configure the software to work in the way they want.
When you fall into the trap of delivering every feature request, the software you produce fails. It collapses under its own weight, with users not understanding their own configurations. Having infinite capacity to deliver features would simply make it fail sooner.
In the case of feature factories, not being able to deliver every request is the one thing saving them from failure. They survive a lack of product management because the backlog of work forces them to choose from an infinite list of options. Without this pressure to choose, the good features get drowned by the bad.
Simply put, more features and more code do nothing to increase the value of software. This kind of software lacks the one thing that’s really valuable: a strong opinion.
What about experiment-based approaches?
The Infinite Experiment Team
Experimental teams use techniques such as impact mapping to decide on goals and generate experiments to discover what will move them closer to each goal.
With no constraints, an experimental team would maximize learning. They would try many alternative ideas to discover the best approach and could revisit what they learned from previous experiments to see if the results were still valid.
Part of an experimental team’s DNA is removing things that don’t work. They might add an upsell screen to a checkout process to increase sales, but walk back on this if it increased abandoned shopping baskets with more value than the upsells.
The process of experimentation requires a balance of sequential and simultaneous measurement. You don’t want to change many things at once, but you usually need to measure the current software against the proposed idea at the same time to avoid disruption from time-based events and seasonality.
Experimental teams would gain more learning from an infinite capacity, which would be incredibly valuable.
Elite performance is useful when it gets you fast high-quality feedback, not when it just means more features.
Continuous Delivery Gets You Fast Feedback
In the white paper “The Importance of Continuous Delivery,” I described how the technical practices of continuous delivery contribute to shorter feedback cycles. The goal of CD isn’t to create more features but more impact.
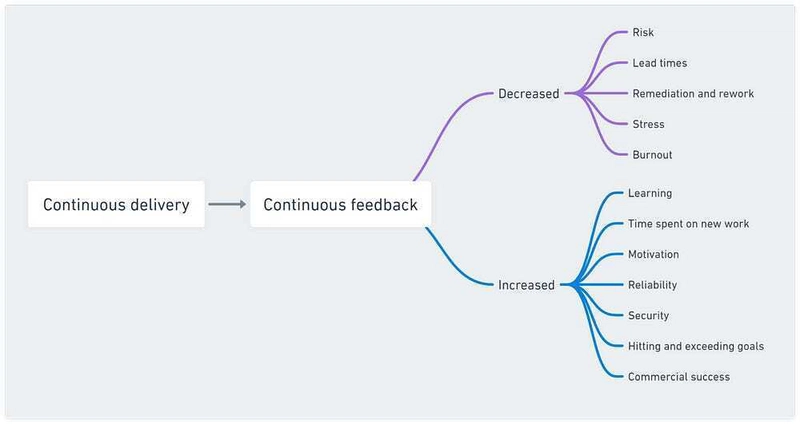
Short feedback loops help in many ways. They decrease risk, reduce rework and improve well-being. Frequent feedback also maximizes learning, increases time spent on new work and makes you more likely to meet and exceed your goals.
Everyone uses proxy-feedback loops as interim validation of changes, for example, internal testing. But the only meaningful feedback comes from getting the software to real users.
When you work in large batches, you delay this real feedback. The effects of delayed feedback can be hidden because internal feedback cycles confirm features are being “completed,” which looks a lot like progress in the absence of real signals. The further you travel on proxy feedback, the more market risk you accumulate.
Comparison Case Study
I worked on a content management system (CMS) used by a network of companies across 1,500 locations in more than 20 countries. One of the classic problems with a CMS is that you can’t always predict the content the users will add.
Users often shoot photographs on digital cameras and upload them at full size but still expect the web page to load quickly for their visitors. A good CMS will need to manage the images to handle good practices the user may not be aware of, whether that’s file size, format or some other facet.
This case study is interesting because the image-optimization problem was solved twice. Once with an experimental approach and once in a feature-driven way. This provides a way to compare the approach with most other factors being equal.
The experimental approach:
- Introduce measurements to capture the current state.
- Define an ideal target state.
- Try an idea.
- Determine the impact of the idea.
- Learn and embed the knowledge.
- Positive progress — Try another idea until the target state is reached.
- Negative progress — Remove the changes and try something else.
The feature-driven approach:
- Migrate images to a new storage technology.
- Serve the images from a different domain.
- Cache the images.
The technological result of the experimental approach was that the original image was never served to a website visitor. Instead, several resized versions of the image were stored and the appropriate size was selected by the browser from a source set containing the various options. Images below the fold were set to lazy-load, further increasing the perceived speed.
The outcome of this approach was that sites were much faster, though it took several experiments to find an acceptable balance between image quality and site speed.
The feature-driven approach resulted in several large technological changes being made. Many of the changes are widely believed to improve performance, but the team didn’t validate this with any measurements.
The outcome of the feature-driven approach was that the site was slower. The speed of the storage technology, the benefit of serving images from a domain with no cookies and the benefits of caching didn’t solve the underlying issue of many large images being served over typical network speeds.
The lesson isn’t that resizing images leads to more improvement than other performance changes. It’s that validating your assumptions by measuring the impact of changes allows you to achieve the desired outcome and learn from the attempts you make.
When taking an experimental approach, trying out each theory is crucial. It’s also standard practice to remove code for experiments you reject. If the change doesn’t advance you toward your goal, you don’t want to keep it.
Yet, this is what many organizations are doing by failing to measure the impact of their changes.
Elite Performance Allows Fluid Experimentation
When a software product is highly feature-driven, limiting throughput is beneficial as the pressure forces decisions about each feature’s potential value. Feature-driven organizations need a reason to say no, and without a limiting factor, they’ll quickly ruin their software.
When a product is experiment-focused, higher levels of performance result in the faster accumulation of knowledge. That makes the approach vastly superior to the feature factory.
I originally published this article on The New Stack.