
































































Diffusing Images on a Laptop with no GPU
This weekend I learned that it is possible to diffuse images without a GPU. I didn't think this would work but it's not only possible, it's easy and actually pretty fast! (Disclaimer: you need a good amount of RAM, I have 20GB) To keep this simple and portable. I have used docker to run fastsdcpu. FROM ubuntu:24.04 AS base RUN apt update \ && apt-get install -y python3 python3-venv python3-pip python3-wheel ffmpeg git wget nano \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* \ && pip install uv --break-system-packages FROM base AS fastsd ARG FASTSDCPU_VERSION=v1.0.0-beta.200 RUN git clone https://github.com/rupeshs/fastsdcpu /app \ && cd app \ && git checkout -b $FASTSDCPU_VERSION \ && wget https://huggingface.co/rupeshs/FastSD-Flux-GGUF/resolve/main/libstable-diffusion.so?download=true -O libstable-diffusion.so WORKDIR /app SHELL [ "/bin/bash", "-c" ] RUN echo y | bash -x ./install.sh --disable-gui VOLUME /app/models/gguf/ VOLUME /app/lora_models/ VOLUME /app/controlnet_models/ VOLUME /root/.cache/huggingface/hub/ ENV GRADIO_SERVER_NAME=0.0.0.0 EXPOSE 7860 CMD [ "/app/start-webui.sh" ] And start this container with Docker Compose, mapping the volumes to directories on your host system to store models outside of the container. services: fastsdcpu: build: context: . dockerfile: Dockerfile ports: - "7860:7860" volumes: - gguf:/app/models/gguf/ - lora:/app/lora_models/ - ctrl:/app/controlnet_models/ - cache:/root/.cache/huggingface/hub/ deploy: resources: limits: memory: 20g stdin_open: true tty: true environment: - GRADIO_SERVER_NAME=0.0.0.0 volumes: gguf: driver: local driver_opts: type: none o: bind device: ./models/gguf lora: driver: local driver_opts: type: none o: bind device: ./models/lora cache: driver: local driver_opts: type: none o: bind device: ./models/cache ctrl: driver: local driver_opts: type: none o: bind device: ./models/ctrl $ sudo docker compose up --build Once the web service has started you can access it at http://localhost:7860. This app is designed to auto-download the selected model the first time you try to generate an image. You'll have to experiment with what works best for your use-case. The default model LCM -> stabilityai/sd-turbo works pretty well for objects and scenery but does not do so well with realistic images of people. LCM-Lora -> Lykon/dreamshaper-8 is much better at people and quite surprisingly fast. Even with my modest Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz with no dedicated GPU, I can generate crisp, consistent images in ~30 seconds. Of course your generation settings will affect this. Higher resolution images or more inference steps will take longer. I found the best settings for dreamshaper to be 4-5 steps with guidance scale 1. I can quickly generate 256x256 images for testing prompts and after I get roughly what I want, I increase the resolution and other settings gradually until I get exactly the image I'm looking for. Using tiny auto encoder for SD makes a significant difference in speed. I tried using LCM-OpenVINO -> rupeshs/sd-turbo-openvino which is specifically for Intel setups but I found this took longer and bogged my system down. If you have a newer Intel Arc based system this will probably work better for you. Sadly I was not able to get Flux1 working. I think it requires CPU instructions that my system does not possess. If you have an i7 or higher, this would be the ideal model to choose if you want highly creative images especially in a fantasy setting. Also, Flux1 can generate coherent text which Stable Diffusion notoriously fails at.
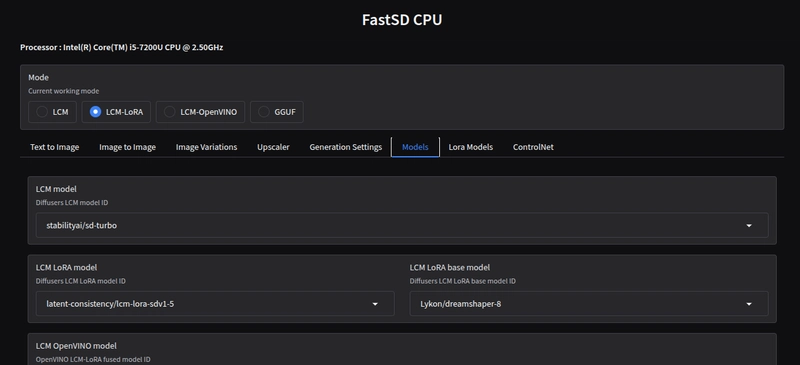
This weekend I learned that it is possible to diffuse images without a GPU. I didn't think this would work but it's not only possible, it's easy and actually pretty fast! (Disclaimer: you need a good amount of RAM, I have 20GB)
To keep this simple and portable. I have used docker to run fastsdcpu.
FROM ubuntu:24.04 AS base
RUN apt update \
&& apt-get install -y python3 python3-venv python3-pip python3-wheel ffmpeg git wget nano \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& pip install uv --break-system-packages
FROM base AS fastsd
ARG FASTSDCPU_VERSION=v1.0.0-beta.200
RUN git clone https://github.com/rupeshs/fastsdcpu /app \
&& cd app \
&& git checkout -b $FASTSDCPU_VERSION \
&& wget https://huggingface.co/rupeshs/FastSD-Flux-GGUF/resolve/main/libstable-diffusion.so?download=true -O libstable-diffusion.so
WORKDIR /app
SHELL [ "/bin/bash", "-c" ]
RUN echo y | bash -x ./install.sh --disable-gui
VOLUME /app/models/gguf/
VOLUME /app/lora_models/
VOLUME /app/controlnet_models/
VOLUME /root/.cache/huggingface/hub/
ENV GRADIO_SERVER_NAME=0.0.0.0
EXPOSE 7860
CMD [ "/app/start-webui.sh" ]
And start this container with Docker Compose, mapping the volumes to directories on your host system to store models outside of the container.
services:
fastsdcpu:
build:
context: .
dockerfile: Dockerfile
ports:
- "7860:7860"
volumes:
- gguf:/app/models/gguf/
- lora:/app/lora_models/
- ctrl:/app/controlnet_models/
- cache:/root/.cache/huggingface/hub/
deploy:
resources:
limits:
memory: 20g
stdin_open: true
tty: true
environment:
- GRADIO_SERVER_NAME=0.0.0.0
volumes:
gguf:
driver: local
driver_opts:
type: none
o: bind
device: ./models/gguf
lora:
driver: local
driver_opts:
type: none
o: bind
device: ./models/lora
cache:
driver: local
driver_opts:
type: none
o: bind
device: ./models/cache
ctrl:
driver: local
driver_opts:
type: none
o: bind
device: ./models/ctrl
$ sudo docker compose up --build
Once the web service has started you can access it at http://localhost:7860.
This app is designed to auto-download the selected model the first time you try to generate an image. You'll have to experiment with what works best for your use-case. The default model LCM -> stabilityai/sd-turbo works pretty well for objects and scenery but does not do so well with realistic images of people. LCM-Lora -> Lykon/dreamshaper-8 is much better at people and quite surprisingly fast. Even with my modest Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz with no dedicated GPU, I can generate crisp, consistent images in ~30 seconds.
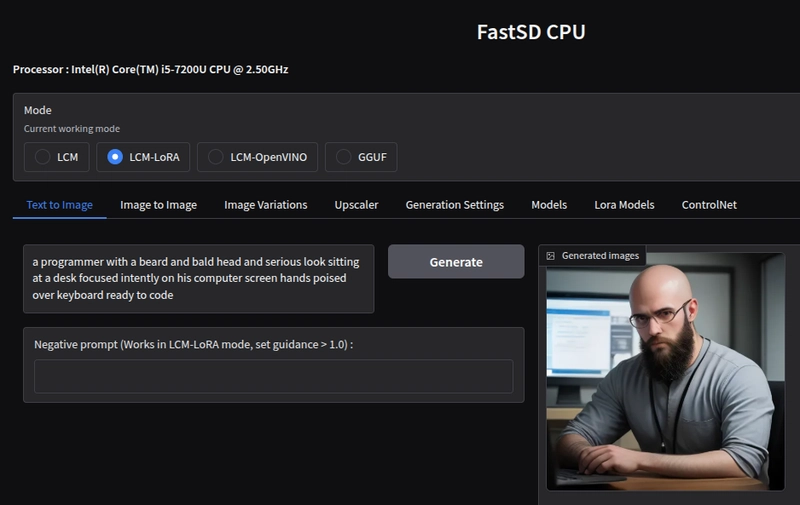
Of course your generation settings will affect this. Higher resolution images or more inference steps will take longer. I found the best settings for dreamshaper to be 4-5 steps with guidance scale 1. I can quickly generate 256x256 images for testing prompts and after I get roughly what I want, I increase the resolution and other settings gradually until I get exactly the image I'm looking for. Using tiny auto encoder for SD makes a significant difference in speed.
I tried using LCM-OpenVINO -> rupeshs/sd-turbo-openvino which is specifically for Intel setups but I found this took longer and bogged my system down. If you have a newer Intel Arc based system this will probably work better for you.
Sadly I was not able to get Flux1 working. I think it requires CPU instructions that my system does not possess. If you have an i7 or higher, this would be the ideal model to choose if you want highly creative images especially in a fantasy setting. Also, Flux1 can generate coherent text which Stable Diffusion notoriously fails at.




