






























































Create a Custom MCP Server for Working with AWS Services - Adding a RAG Knowledge Base and Utilities
In the last post, we built a custom server that uses the Model Context Protocol (MCP) to expose tools that give LLM clients direct insight into the Amazon Interactive Video Service (Amazon IVS) resources in an AWS account. The server also has the ability to get health and metric data on our Amazon IVS resources via CloudWatch. This gives us the ability to get deep insight and perform custom queries into our environment, setting us up for great success when it comes to managing our Amazon IVS resources. Having an MCP server with insight into our resources is amazing, but we can make this server even more powerful by giving it some documentation and contextually knowledge about Amazon IVS as a service. In this post, we're going to add some additional tools to that MCP server to add that knowledge as well as some other helpful utilities. Don't worry, we'll get to building an MCP client in the future. For now, let's supercharge this server so that our client will have all the tools that it needs to help us build amazing Amazon IVS prototypes and demos. Adding RAG Support to Our MCP Server With the popularity and rise of MCP, some have wondered if it meant the death of Retrieval Augmented Generation. However, this couldn't be further from the truth. Like MCP, RAG is a valuable tool that can be an additional source of domain-specific data that an LLM might not otherwise be aware of. To add RAG functionality to our IVS MCP server, we'll create a Knowledge Base in Amazon Bedrock and populate it with some Amazon IVS documentation. Creating the Knowledge Base We could use the AWS CLI, or other methods to create the knowledge base, but I prefer to use the console since it takes care of creating the necessary data store and IAM roles for us. First, head to the Amazon Bedrock console and click 'Create' and select 'Knowledge Base with vector store'. Name it, and choose or create a new service role. Choose 'Web Crawler' as the data source and click 'Next'. On the next step, give the data source a name and optional description. Now we can define up to 9 URLs for the data source to crawl that will be used to populate the data source. Here's the list of the URLs that I used. I focused on official documentation sources for Amazon IVS, as well as all of the blog posts here on dev.to tagged with 'amazonivs'. https://dev.to/t/amazonivs https://aws.github.io/amazon-ivs-web-broadcast/ https://docs.aws.amazon.com/ivs/latest/LowLatencyUserGuide/ https://docs.aws.amazon.com/ivs/latest/RealTimeUserGuide/ Choose the best settings for your use case in the 'Sync Scope' section, but pay attention to 'Exclude patterns'. Your mileage may vary, but I found that excluding PDFs and RSS feeds provided better results for my knowledge base. I used the pattern (.*.pdf|.*.rss) to exclude these. In my testing, letting it crawl these would end up confuse the client later on because it would often return results from the 'index' page of the PDF instead of from the documentation body. For 'Content chunking and parsing', again choose the best options for your use case. I found the default options to work fine for me. On the next step of the wizard, choose an 'Embeddings model'. This is the model that is used to convert the crawled data to vector data. The Titan Embeddings G1 - Text v1.2 model worked great for me. Finally, choose or create a vector database that will be used to store, update and manage the embeddings. I chose to create a new one with Amazon OpenSearch Serverless. Click 'Next', review the settings, and click 'Create Knowledge Base'. At this point, the necessary roles and databases will be created. Once they're ready, you can 'Sync' your data source which should take about 15 minutes. After the data source is synced, we're ready to integrate the knowledge base into our MCP server! Creating a Knowledge Base Retrieval Tool With a RAG knowledge base created and synced up, we can create a tool in our MCP server to retrieve data based on a query. We'll use the Amazon Bedrock Agent Runtime for this, so install that module and create a client. npm install @aws-sdk/client-bedrock-agent-runtime import { BedrockAgentRuntimeClient, RetrieveCommand } from "@aws-sdk/client-bedrock-agent-runtime"; const bedrockAgentRuntimeClient = new BedrockAgentRuntimeClient(config); Next, add a server tool. server.tool( "ivs-knowledgebase-retrieve", "Retrieve information from the Amazon IVS Bedrock Knowledgebase for queries specific to the latest Amazon IVS documentation or service information.", { query: z.string().describe('The query to search the knowledgebase for'), }, async ({ query }) => { const input = { knowledgeBaseId, retrievalQuery: { text: query, }, vectorSearchConfiguration: { numberOfResults: 5, overrideSearchType: 'HYBRID', } }; const command = new RetrieveCommand(inpu
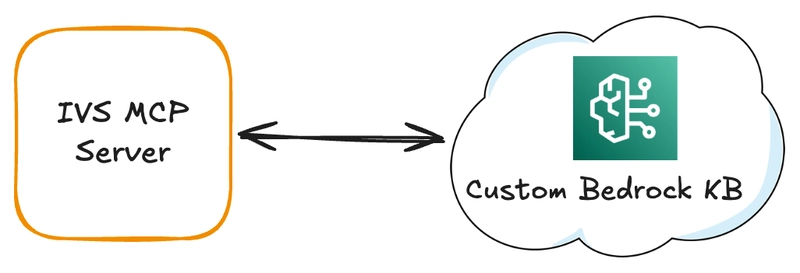
In the last post, we built a custom server that uses the Model Context Protocol (MCP) to expose tools that give LLM clients direct insight into the Amazon Interactive Video Service (Amazon IVS) resources in an AWS account. The server also has the ability to get health and metric data on our Amazon IVS resources via CloudWatch. This gives us the ability to get deep insight and perform custom queries into our environment, setting us up for great success when it comes to managing our Amazon IVS resources.
Having an MCP server with insight into our resources is amazing, but we can make this server even more powerful by giving it some documentation and contextually knowledge about Amazon IVS as a service. In this post, we're going to add some additional tools to that MCP server to add that knowledge as well as some other helpful utilities. Don't worry, we'll get to building an MCP client in the future. For now, let's supercharge this server so that our client will have all the tools that it needs to help us build amazing Amazon IVS prototypes and demos.
Adding RAG Support to Our MCP Server
With the popularity and rise of MCP, some have wondered if it meant the death of Retrieval Augmented Generation. However, this couldn't be further from the truth. Like MCP, RAG is a valuable tool that can be an additional source of domain-specific data that an LLM might not otherwise be aware of. To add RAG functionality to our IVS MCP server, we'll create a Knowledge Base in Amazon Bedrock and populate it with some Amazon IVS documentation.
Creating the Knowledge Base
We could use the AWS CLI, or other methods to create the knowledge base, but I prefer to use the console since it takes care of creating the necessary data store and IAM roles for us.
First, head to the Amazon Bedrock console and click 'Create' and select 'Knowledge Base with vector store'.

Name it, and choose or create a new service role.
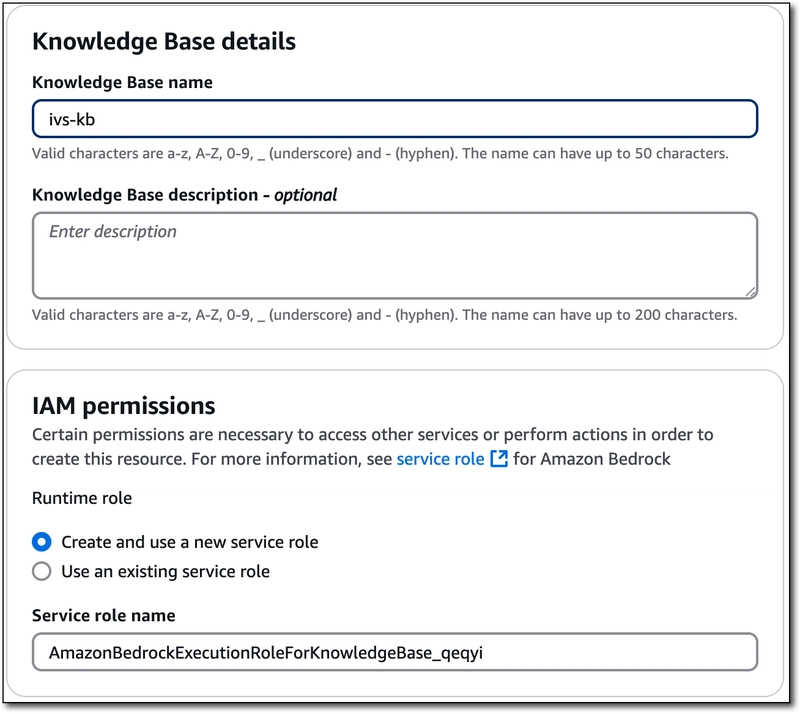
Choose 'Web Crawler' as the data source and click 'Next'.
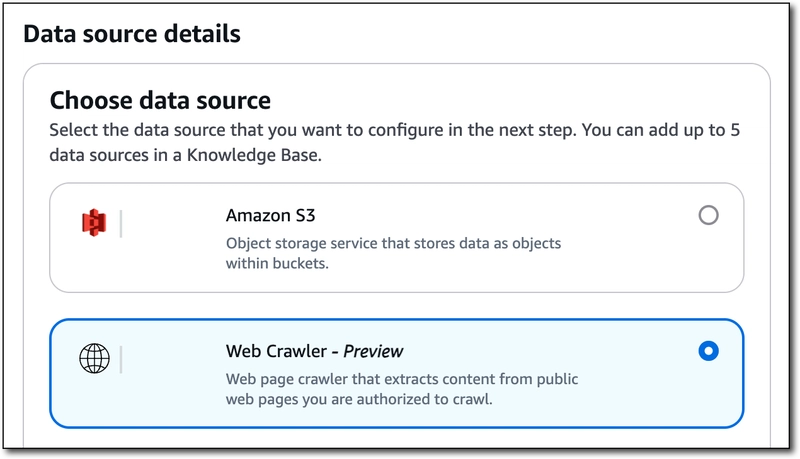
On the next step, give the data source a name and optional description.
Now we can define up to 9 URLs for the data source to crawl that will be used to populate the data source.
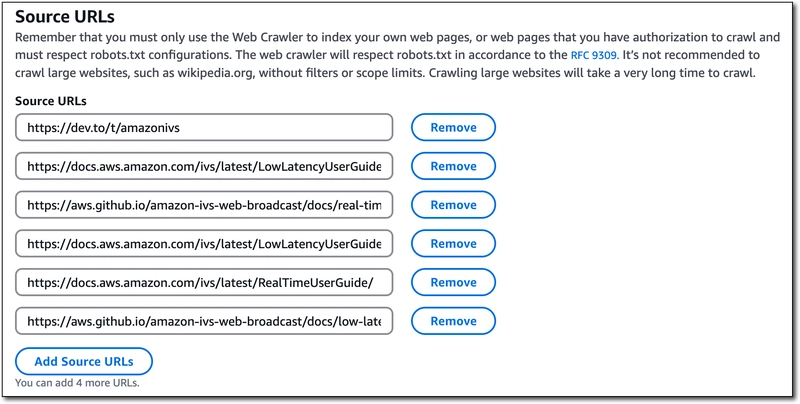
Here's the list of the URLs that I used. I focused on official documentation sources for Amazon IVS, as well as all of the blog posts here on dev.to tagged with 'amazonivs'.
https://dev.to/t/amazonivs
https://aws.github.io/amazon-ivs-web-broadcast/
https://docs.aws.amazon.com/ivs/latest/LowLatencyUserGuide/
https://docs.aws.amazon.com/ivs/latest/RealTimeUserGuide/
Choose the best settings for your use case in the 'Sync Scope' section, but pay attention to 'Exclude patterns'. Your mileage may vary, but I found that excluding PDFs and RSS feeds provided better results for my knowledge base. I used the pattern (.*.pdf|.*.rss) to exclude these. In my testing, letting it crawl these would end up confuse the client later on because it would often return results from the 'index' page of the PDF instead of from the documentation body.
For 'Content chunking and parsing', again choose the best options for your use case. I found the default options to work fine for me.
On the next step of the wizard, choose an 'Embeddings model'. This is the model that is used to convert the crawled data to vector data. The Titan Embeddings G1 - Text v1.2 model worked great for me.
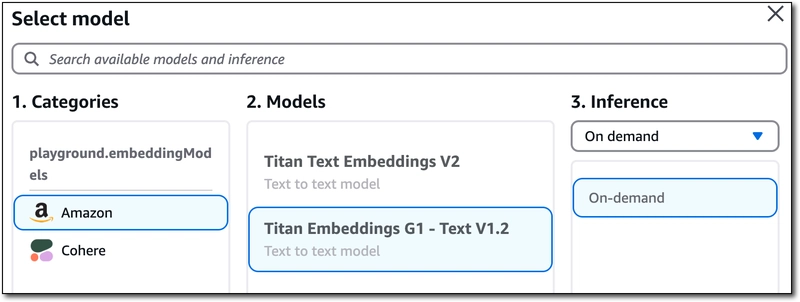
Finally, choose or create a vector database that will be used to store, update and manage the embeddings. I chose to create a new one with Amazon OpenSearch Serverless.
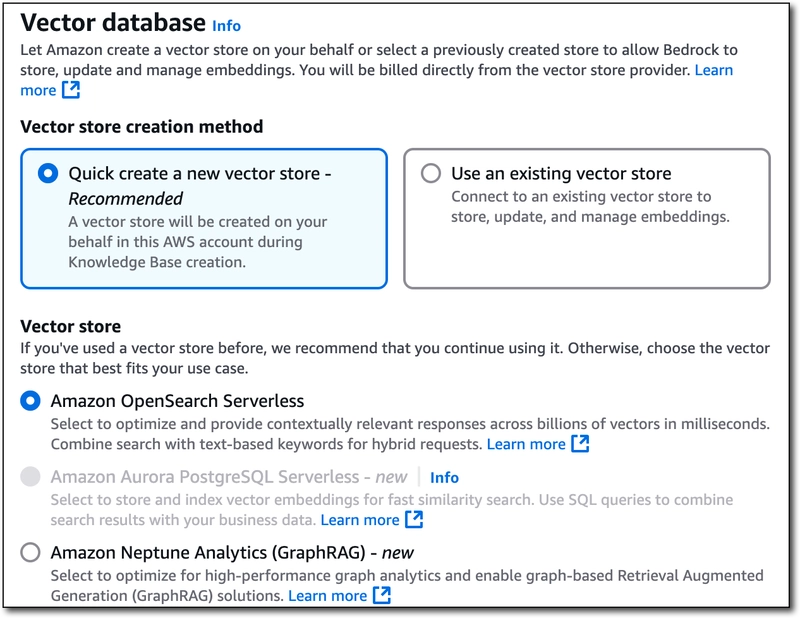
Click 'Next', review the settings, and click 'Create Knowledge Base'. At this point, the necessary roles and databases will be created. Once they're ready, you can 'Sync' your data source which should take about 15 minutes. After the data source is synced, we're ready to integrate the knowledge base into our MCP server!
Creating a Knowledge Base Retrieval Tool
With a RAG knowledge base created and synced up, we can create a tool in our MCP server to retrieve data based on a query. We'll use the Amazon Bedrock Agent Runtime for this, so install that module and create a client.
npm install @aws-sdk/client-bedrock-agent-runtime
import {
BedrockAgentRuntimeClient,
RetrieveCommand
} from "@aws-sdk/client-bedrock-agent-runtime";
const bedrockAgentRuntimeClient =
new BedrockAgentRuntimeClient(config);
Next, add a server tool.
server.tool(
"ivs-knowledgebase-retrieve",
"Retrieve information from the Amazon IVS Bedrock Knowledgebase for queries specific to the latest Amazon IVS documentation or service information.",
{
query: z.string().describe('The query to search the knowledgebase for'),
},
async ({ query }) => {
const input = {
knowledgeBaseId,
retrievalQuery: {
text: query,
},
vectorSearchConfiguration: {
numberOfResults: 5,
overrideSearchType: 'HYBRID',
}
};
const command = new RetrieveCommand(input);
const response = await bedrockAgentRuntimeClient.send(command);
return {
content: [{ type: "text", text: JSON.stringify(response) }]
};
}
);
That's it! Now that we've exposed a tool, our client can query this knowledge base whenever it feels that it needs additional documentation regarding Amazon IVS.
Adding Miscellaneous Tools to the MCP Server
One of my favorite parts of MCP servers is the ability to provide utilities and tools. Beyond domain specific knowledge, we can provide clients with tools to help our LLM with things that it is normally not that great at handling. Things like math and date handling. For example, if you were to use a client with the MCP server that we've created and asked it to tell you how long ago a specific IVS channel was created, it might give you a surprising answer and tell you that the channel was created in the future! This is because the model has no direct knowledge of the current date and time. We can easily solve this by creating a tool to return the current date and time. Then, when we expose that tool to a client, it'll know how to get that information!
server.tool(
"get-current-date-time",
"Gets the current date and time",
{},
async () => {
return {
content: [{ type: "text", text: JSON.stringify(new Date().toISOString()) }]
};
}
);
Simple, but beautiful




