




































































Como bancos de dados realmente salvam os dados
A fonte de armazenamento primária de um banco de dados é um disco não-volátil. Não-volátil significa que, mesmo após desligado, ele retém tudo que foi salvo. Na memória volátil os dados são perdidos. A memória volátil é mais rápida, tem menor capacidade de armazenamento e custa mais caro. Para que possa ler ou manipular dados, um banco de dados traz os dados para a memória. Para isso, ele aloca uma pool de memória chamada de buffer pool. Páginas de Dados Um banco de dados nada mais é do que uma coleção de arquivos em disco, e esses arquivos são quebrados em páginas para que fique mais fácil de acessar os dados. Uma página é um bloco de dados de tamanho fixo que pode conter linhas (tuplas) de dados, metadados, índices, logs. A maioria das páginas contém linhas de dados salvos por um usuário, e são chamadas de data pages (páginas de dados). Index pages (páginas de índices) contém referências sobre onde os dados se encontram utilizando o identificador único de cada página (Page ID). Páginas podem ter tamanhos variados, e cada um traz suas vantagens. Páginas menores são mais rápidas para ler e escrever, enquanto páginas maiores minimizam a necessidade de separar uma tupla de dados. SQLite usa páginas de 4KB, PostgreSQL 8KB e MySQL 16KB. Além dos diferentes tamanhos de página, cada banco de dados guarda os dados de formas diferentes. PostgreSQL, por exemplo, salva cada tabela e índice em um arquivo, e possui uma pasta para cada database. SQLite, por outro lado, guarda toda informação sobre um database em um único arquivo. A maioria dos bancos de dados não consegue ler arquivos de outro, mas alguns como DuckDB tentam ser compatíveis com vários através de extensões. Diferentes bancos de dados gerenciam arquivos em disco de maneiras diferentes, sendo um dos mais usados o Heap File Organization. Um Heap File é uma coleção de páginas nas quais os dados são guardados em ordem aleatória. São utilizados o Page ID e metadados adicionais para encontrar os dados que se procura. Num sistema que guarda os dados em múltiplos arquivos, se utiliza um diretório de páginas para informar em qual arquivo se encontram os dados desejados. Dentro do header desse arquivo pode conter mais metadados descrevendo as páginas e os dados contidos nelas. O diretório de páginas ainda pode conter metadados sobre a quantidade de espaço livre em cada página, uma lista de páginas vazias e ainda qual tipo de cada página (dados, metadados). Dessa forma, quando um insert é feito não precisa verificar página por página para saber qual está livre, pode-se apenas consultar o diretório. Layout da Página Slotted Pages é o layout de páginas mais utilizado. Ele funciona mantendo regiões de memória que vão crescendo em direções opostas, mantendo um “slot array” que liga os ponteiros às posições iniciais das tuplas. O header da página contém informações sobre tamanho da página, o início e fim do espaço vazio, versão e outras coisas que podem ser adicionadas. Overflow Pages Quando uma tupla ultrapassa o tamanho de uma página, algumas técnicas podem ser utilizadas. SQLite separa a tupla em diversos pedaços de tamanhos diferentes em páginas chamadas Overflow Pages, e um aponta para o outro como se fossem uma lista ligada. SQL Server move uma ou mais colunas de tamanhos variáveis para páginas em uma unidade específica, começando pela coluna de maior tamanho. Quando isso é feito, um ponteiro de 24 bytes é mantido na página original. Fontes: https://www.youtube.com/watch?v=dSxV5Sob5V8&t=130s&ab_channel=CMUDatabaseGroup https://www.youtube.com/watch?v=5Pc18ge9ohI&t=1652s&ab_channel=TonySaro https://learn.microsoft.com/en-us/sql/relational-databases/pages-and-extents-architecture-guide?view=sql-server-ver16 https://siemens.blog/posts/database-page-layout/ https://medium.com/@hnasr/database-pages-a-deep-dive-38cdb2c79eb5
A fonte de armazenamento primária de um banco de dados é um disco não-volátil. Não-volátil significa que, mesmo após desligado, ele retém tudo que foi salvo. Na memória volátil os dados são perdidos. A memória volátil é mais rápida, tem menor capacidade de armazenamento e custa mais caro.
Para que possa ler ou manipular dados, um banco de dados traz os dados para a memória. Para isso, ele aloca uma pool de memória chamada de buffer pool.
Páginas de Dados
Um banco de dados nada mais é do que uma coleção de arquivos em disco, e esses arquivos são quebrados em páginas para que fique mais fácil de acessar os dados. Uma página é um bloco de dados de tamanho fixo que pode conter linhas (tuplas) de dados, metadados, índices, logs. A maioria das páginas contém linhas de dados salvos por um usuário, e são chamadas de data pages (páginas de dados). Index pages (páginas de índices) contém referências sobre onde os dados se encontram utilizando o identificador único de cada página (Page ID).
Páginas podem ter tamanhos variados, e cada um traz suas vantagens. Páginas menores são mais rápidas para ler e escrever, enquanto páginas maiores minimizam a necessidade de separar uma tupla de dados. SQLite usa páginas de 4KB, PostgreSQL 8KB e MySQL 16KB.
Além dos diferentes tamanhos de página, cada banco de dados guarda os dados de formas diferentes. PostgreSQL, por exemplo, salva cada tabela e índice em um arquivo, e possui uma pasta para cada database. SQLite, por outro lado, guarda toda informação sobre um database em um único arquivo. A maioria dos bancos de dados não consegue ler arquivos de outro, mas alguns como DuckDB tentam ser compatíveis com vários através de extensões.
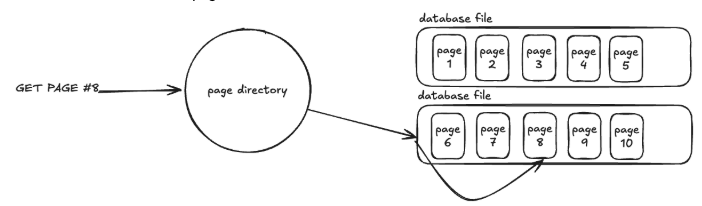
Diferentes bancos de dados gerenciam arquivos em disco de maneiras diferentes, sendo um dos mais usados o Heap File Organization. Um Heap File é uma coleção de páginas nas quais os dados são guardados em ordem aleatória. São utilizados o Page ID e metadados adicionais para encontrar os dados que se procura. Num sistema que guarda os dados em múltiplos arquivos, se utiliza um diretório de páginas para informar em qual arquivo se encontram os dados desejados. Dentro do header desse arquivo pode conter mais metadados descrevendo as páginas e os dados contidos nelas.
O diretório de páginas ainda pode conter metadados sobre a quantidade de espaço livre em cada página, uma lista de páginas vazias e ainda qual tipo de cada página (dados, metadados). Dessa forma, quando um insert é feito não precisa verificar página por página para saber qual está livre, pode-se apenas consultar o diretório.
Layout da Página
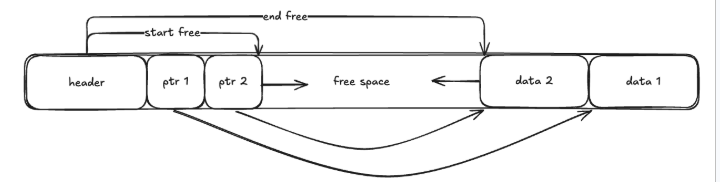
Slotted Pages é o layout de páginas mais utilizado. Ele funciona mantendo regiões de memória que vão crescendo em direções opostas, mantendo um “slot array” que liga os ponteiros às posições iniciais das tuplas.
O header da página contém informações sobre tamanho da página, o início e fim do espaço vazio, versão e outras coisas que podem ser adicionadas.
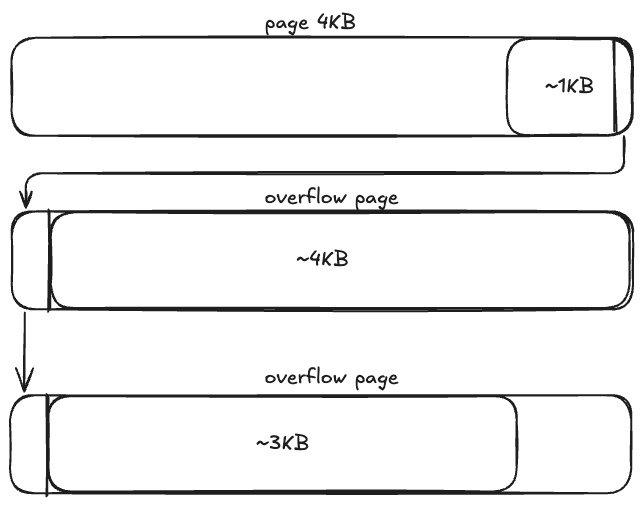
Overflow Pages
Quando uma tupla ultrapassa o tamanho de uma página, algumas técnicas podem ser utilizadas. SQLite separa a tupla em diversos pedaços de tamanhos diferentes em páginas chamadas Overflow Pages, e um aponta para o outro como se fossem uma lista ligada. SQL Server move uma ou mais colunas de tamanhos variáveis para páginas em uma unidade específica, começando pela coluna de maior tamanho. Quando isso é feito, um ponteiro de 24 bytes é mantido na página original.
Fontes:
- https://www.youtube.com/watch?v=dSxV5Sob5V8&t=130s&ab_channel=CMUDatabaseGroup
- https://www.youtube.com/watch?v=5Pc18ge9ohI&t=1652s&ab_channel=TonySaro
- https://learn.microsoft.com/en-us/sql/relational-databases/pages-and-extents-architecture-guide?view=sql-server-ver16
- https://siemens.blog/posts/database-page-layout/
- https://medium.com/@hnasr/database-pages-a-deep-dive-38cdb2c79eb5








