


































































C4.5 Decision Trees in Go: Optimizing for Performance and Scalability
Decision trees are a fundamental machine learning algorithm used for classification and regression tasks. Among them, C4.5, an improvement over ID3, is widely known for handling both categorical and continuous data, pruning trees to reduce overfitting, and dealing with missing values. Implementing C4.5 in Go presents unique challenges and opportunities, particularly in optimizing for performance and scalability. Why Implement C4.5 in Go? Go is well-suited for high-performance computing due to its: Efficiency: Go compiles directly to machine code, avoiding runtime interpretation overhead. Concurrency Model: Goroutines and channels allow parallel execution, crucial for large datasets. Memory Management: A balance between garbage collection and low-level memory handling. Scalability: Go’s lightweight nature makes it ideal for handling large datasets efficiently. Core Concepts of C4.5 Algorithm C4.5 builds a decision tree using entropy and information gain ratio as key metrics for splitting nodes. The key steps include: Calculate Entropy: Measure impurity in a dataset. Compute Information Gain Ratio: Evaluate the usefulness of a feature. Choose the Best Split: Select the feature with the highest gain ratio. Handle Continuous Values: Convert numerical data into discrete bins. Pruning: Reduce overfitting by removing irrelevant branches. Optimizing C4.5 in Go 1. Efficient Data Structures Using structs and slices instead of traditional object-oriented classes keeps memory footprint low. // Decision Tree Node type Node struct { Feature int Threshold float64 Left, Right *Node Label string } 2. Parallelizing Training with Goroutines Instead of iterating through all possible splits sequentially, we can use goroutines for parallel computation. func computeGain(data [][]float64, results []string, feature int, threshold float64, ch chan
Decision trees are a fundamental machine learning algorithm used for classification and regression tasks. Among them, C4.5, an improvement over ID3, is widely known for handling both categorical and continuous data, pruning trees to reduce overfitting, and dealing with missing values. Implementing C4.5 in Go presents unique challenges and opportunities, particularly in optimizing for performance and scalability.
Why Implement C4.5 in Go?
Go is well-suited for high-performance computing due to its:
- Efficiency: Go compiles directly to machine code, avoiding runtime interpretation overhead.
- Concurrency Model: Goroutines and channels allow parallel execution, crucial for large datasets.
- Memory Management: A balance between garbage collection and low-level memory handling.
- Scalability: Go’s lightweight nature makes it ideal for handling large datasets efficiently.
Core Concepts of C4.5 Algorithm
C4.5 builds a decision tree using entropy and information gain ratio as key metrics for splitting nodes. The key steps include:
- Calculate Entropy: Measure impurity in a dataset.
- Compute Information Gain Ratio: Evaluate the usefulness of a feature.
- Choose the Best Split: Select the feature with the highest gain ratio.
- Handle Continuous Values: Convert numerical data into discrete bins.
- Pruning: Reduce overfitting by removing irrelevant branches.
Optimizing C4.5 in Go
1. Efficient Data Structures
Using structs and slices instead of traditional object-oriented classes keeps memory footprint low.
// Decision Tree Node
type Node struct {
Feature int
Threshold float64
Left, Right *Node
Label string
}
2. Parallelizing Training with Goroutines
Instead of iterating through all possible splits sequentially, we can use goroutines for parallel computation.
func computeGain(data [][]float64, results []string, feature int, threshold float64, ch chan<- float64) {
gain := calculateGain(data, results, feature, threshold) // Custom function
ch <- gain
}
By spawning multiple goroutines, we improve efficiency when working with large datasets.
3. Memory Optimization
Go’s garbage collector is efficient, but large datasets can cause overhead. Using sync.Pool helps reuse memory and reduce allocations.
var nodePool = sync.Pool{
New: func() interface{} { return new(Node) },
}
4. Efficient Sorting for Continuous Values
Sorting is required for handling continuous data splits. Instead of a naive sort, Go’s sort.Slice() function is optimized for performance.
sort.Slice(data, func(i, j int) bool {
return data[i][feature] < data[j][feature]
})
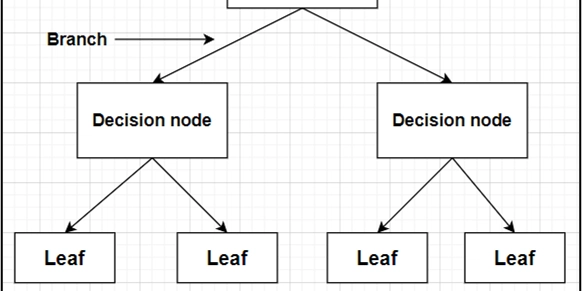
Visualization: Understanding the Decision Tree Structure
To better visualize the structure of a trained C4.5 tree, here’s an example of a simple decision tree graph:
[Feature1 < 5.0]
/ \
[Feature2 < 3.5] [Class: Yes]
/ \
[Class: No] [Feature3 < 2.0]
/ \
[Class: No] [Class: Yes]
For performance visualization, tools like pprof in Go can be used to analyze memory and CPU usage.
go test -bench . -cpuprofile cpu.prof
go tool pprof cpu.prof
Scaling Up: Handling Large Datasets
For large datasets:
- Batch Processing: Instead of loading all data into memory, stream data in chunks.
- Distributed Execution: Integrate with frameworks like Ray (via Go bindings) or gRPC for parallel computation across multiple nodes.
- Persistence with SQLite: Store intermediate results in SQLite or a key-value store for checkpointing.
Conclusion
Implementing C4.5 Decision Trees in Go is a powerful approach for creating scalable and efficient classification models. By leveraging Go’s concurrency, memory management, and efficient data structures, we can significantly optimize performance.









