




























































AI Breakthrough: Training Vision Models Without Images Cuts Computing Costs by 37x
This is a Plain English Papers summary of a research paper called AI Breakthrough: Training Vision Models Without Images Cuts Computing Costs by 37x. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Unicorn synthesizes text-only data for training Vision Language Models (VLMs) Eliminates need for image generation during training Uses text-to-text transformations with LLMs to create text pairs Achieves 90% performance of image-based methods Reduces computational cost by 37x compared to methods using synthetic images Proves VLMs can learn visual concepts from purely textual data Plain English Explanation Imagine training a system to understand both images and text without ever showing it a single image. That's what Unicorn accomplishes. The traditional way to train vision-language models requires massive datasets of paired images and text. When researchers don't have enough re... Click here to read the full summary of this paper
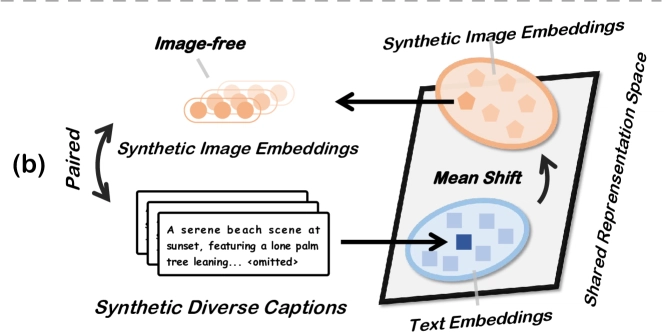
This is a Plain English Papers summary of a research paper called AI Breakthrough: Training Vision Models Without Images Cuts Computing Costs by 37x. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Unicorn synthesizes text-only data for training Vision Language Models (VLMs)
- Eliminates need for image generation during training
- Uses text-to-text transformations with LLMs to create text pairs
- Achieves 90% performance of image-based methods
- Reduces computational cost by 37x compared to methods using synthetic images
- Proves VLMs can learn visual concepts from purely textual data
Plain English Explanation
Imagine training a system to understand both images and text without ever showing it a single image. That's what Unicorn accomplishes.
The traditional way to train vision-language models requires massive datasets of paired images and text. When researchers don't have enough re...








