










![How to Work With HAR Files: A Step-by-Step Guide [With Examples]](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F5wovh8gozs51ofbg0nks.png)





_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































สร้าง Logistic Regression Model อย่างง่ายโดยใช้ Python
การทำนายผลลัพธ์ในลักษณะ "ใช่หรือไม่ใช่" เป็นงานที่พบได้บ่อยในหลายๆ สถานการณ์ เช่น การทำนายว่าลูกค้าจะซื้อสินค้าหรือไม่ การประเมินความเสี่ยงในการเป็นเบาหวาน หรือการตัดสินใจว่าใบสมัครงานจะได้รับการพิจารณาหรือไม่ หนึ่งในวิธีที่นิยมใช้ในการทำนายผลลัพธ์ในลักษณะนี้ คือ Logistic Regression ซึ่งเป็นโมเดลทางสถิติที่ใช้สำหรับการจำแนกประเภทในรูปแบบ binary classification Logistic Regression จะคำนวณ ความน่าจะเป็น (probability) ที่ผลลัพธ์จะเป็น "ใช่" โดยค่าที่ได้จะอยู่ระหว่าง 0 และ 1 ซึ่งสามารถใช้ในการตัดสินใจว่าเราควรทำนายเป็น "ใช่" หรือ "ไม่ใช่" ตามเกณฑ์ที่กำหนด (เช่น ถ้าค่าความน่าจะเป็นมากกว่าหรือเท่ากับ 0.5 จะทำนายเป็น "ใช่") Logistic Regression ช่วยให้เราสร้างโมเดลที่สามารถทำนายผลลัพธ์ได้อย่างมีประสิทธิภาพจากข้อมูลที่มีอยู่ และเป็นเครื่องมือที่ได้รับความนิยมในงานวิจัยและการประยุกต์ใช้ในหลากหลายด้าน ไม่ว่าจะเป็นการตลาด การแพทย์ หรือการประเมินความเสี่ยงในธุรกิจต่างๆ. ในบทความนี้ เราจะมาดูการใช้งาน Logistic Regression ในภาษา Python โดยใช้ชุดข้อมูลที่มีชื่อว่า Iris Dataset ซึ่งเป็นชุดข้อมูลที่ได้รับความนิยมในงานวิเคราะห์ข้อมูลและใช้ในการสอนสร้างโมเดล Machine Learning เบื้องต้น ชุดข้อมูล Iris ประกอบด้วยข้อมูลลักษณะต่างๆ ของดอกไม้ เช่น ความยาวกลีบเลี้ยง (sepal length) ความกว้างกลีบเลี้ยง (sepal width) ความยาวกลีบดอก (petal length) และความกว้างกลีบดอก (petal width) โดยเราจะใช้ข้อมูลเหล่านี้ในการจำแนกว่า ดอกไม้แต่ละดอกเป็นสายพันธุ์ Setosa Versicolor หรือ Virginica. ขั้นตอนที่ 1 Import ไลบรารีที่จำเป็น ขั้นตอนที่ 2 โหลดข้อมูลจากไฟล์ CSV ตัวอย่างของข้อมูลสามารถโหลดได้ตามนี้เลย https://raw.githubusercontent.com/aero971/Logestic_Regression_on_iris_dataset/refs/heads/main/Iris.csv โหลดข้อมูลจากไฟล์ CSV เข้ามาในตัวแปร df (ย่อมาจาก DataFrame) ซึ่งเป็นโครงสร้างข้อมูลแบบตารางของ Pandas และ แสดงข้อมูล 5 แถวแรก ตัวอย่างผลที่ได้จากโค้ด ขั้นตอนที่ 3 ตรวจสอบขนาดของ DataFrame เพื่อแสดงขนาดของตารางข้อมูลว่ามีกี่แถวกี่ Colum จะได้เข้าใจขอบเขตของข้อมูล แสดงขนาดของตารางข้อมูล DataFrame ซึ่งผลลัพธ์คือ (150, 6) หมายความว่ามี 150 แถว 6 คอลัมน์ ขั้นตอนที่ 4 ตรวจสอบข้อมูลเบื้องต้น เราต้องเช็คสภาพข้อมูลก่อนที่จะใช้งานจริง เพื่อให้แน่ใจว่าข้อมูลสะอาด พร้อมใช้งาน และ เข้าใจข้อมูลที่เรากำลังจะวิเคราะห์ ตัวอย่างผลลัพธ์ที่ได้ ขั้นตอนที่ 6 ตรวจสอบจำนวนของแต่ละประเภทดอกไม้ เราจะนับจำนวนตัวอย่างของแต่ละสายพันธุ์ใน Colum Species เพื่อตรวจสอบความสมดุลของแต่ละ Class ผลลัพธ์ที่ได้ ขั้นตอนที่ 7 สร้าง Histogram ต่อมาเราจะมาสร้างแผนภูมิแทง ด้วยไลบรารี matplotlib และ seaborn เพื่อดูการกระจายของข้อมูล (distribution) ของแต่ละฟีเจอร์ใน DataFrame โดยเฉพาะคอลัมน์ที่เกี่ยวกับความยาวและความกว้างของกลีบดอกและกลีบเลี้ยง ผลลัพธ์ ความยาวและความกว้างกลีบเลี้ยง ความยาวและความกว้างของกลีบดอก ต่อมาเราจะใช้ FacetGrid จาก seaborn เพื่อแสดง ความสัมพันธ์ระหว่างตัวแปร 2 ตัว (PetalLengthCm และ SepalWidthCm) โดยแยกตามค่าในคอลัมน์ Species (ชนิดของดอก) ผลลัพธ์ ต่อมาเราจะลบ ID ออกเนื่องจากไม่ได้ช่วยในการวิเคราะห์ และวาดกราฟจับคู่ตัวแปรทุกตัว และใช้สีแยกชนิดดอกไม้ตาม Species ผลลัพธ์ที่ได้ ขั้นตอนที่ 8 สร้าง Boxplot 4 รูป เราจะสร้างกราฟ Boxplot 4 รูปเพื่อเปรียบเทียบค่าความยาวและความกว้างของกลีบดอกและกลีบเลี้ยงของดอกไม้แต่ละสายพันธุ์ในชุดข้อมูล DataFrame โดยใช้ Seaborn และ Matplotlib จัดวางในรูปแบบ 2x2 บนพื้นที่ขนาด 16x9 นิ้ว ช่วยให้เห็นการกระจายตัวและค่าผิดปกติของแต่ละชนิดดอกไม้ได้ชัดเจน ผลลัพธ์ ต่อมาเราจะสร้าง heatmap แสดงค่า correlation ระหว่างคุณลักษณะของดอกไม้ในชุดข้อมูล DataFrame โดยที่เราจะลบคอลัมน์ Id ออก เพราะไม่ใช่ข้อมูลเชิงวิเคราะห์ และคำนวณค่า Pearson correlation ระหว่างแต่ละ feature พร้อมทั้งแสดง heatmap พร้อมตัวเลขในแต่ละช่อง เราจะใช้ figsize=(8,6) เพื่อกำหนดขนาดแผนภาพให้พอดี ดูชัด เข้าใจง่ายว่า feature ไหนมีความสัมพันธ์กันสูง ผลลัพธ์ ขั้นตอนที่ 9 สร้างโมเดล Logistic Regression เราจะใช้ Logistic Regression เพื่อจำแนกชนิดของดอกไม้ (Species) โดยอิงจากคุณลักษณะ 4 อย่าง ได้แก่ SepalLengthCm SepalWidthCm PetalLengthCm และ PetalWidthCm โดยที่ X คือ ตัวแปรอิสระ (features) แปลงจาก DataFrame เป็น array เพื่อให้โมเดลใช้ได้ y คือ ตัวแปรตาม (target) ยังอยู่ในรูปแบบ DataFrame ผลลัพธ์ ต่อมาเราจะมาดูความแม่นยำของโมเดลกัน ผลลัพธ์คือ 97.33 แสดงให้เห็นว่ามีความแม่นยำสูง ต่อมาเราจะมาทำนายผลลัพธ์จากโมเดลที่เราสร้างและฝึกมาแล้ว เพื่อทำนายผลจากข้อมูลทดสอบ (Test Data) ผลลัพธ์ เรามาดูผลการประเมินโมเดลแบบละเอียดกัน ผลลัพธ์ที่ได้ Setosa มี precision และ recall เท่ากับ 1.00 หมายความว่าโมเดลสามารถทำนาย Setosa ได้ถูกต้องทั้งหมด Versicolor และ Virginica มี precision และ recall ใกล้เคียง 1.00 เช่นกัน Accuracy (ค่าความแม่นยำโดยรวม) คือ 98% ซึ่งแสดงว่าโมเดลทำนายได้ถูกต้อง 98% ของทั้งหมด สุดท้ายนี้เราใช้ confusion matrix ซึ่งเป็นเครื่องมือในการประเมินประสิทธิภาพของโมเดลโดยการเปรียบเทียบ ค่าทำนาย (predicted) กับ ค่าจริง (expected) ของข้อมูลทดสอบ เราใช้โมเดลจำแนกประเภทดอกไม้ 3 ชนิด (Setosa Versicolor และ Virginica) ผลลัพธ์ที่ได้ แสดงให้เห็นว่า แถวแรก ([50 0 0]): Setosa โมเดลทำนาย ถูกต้องทั้งหมด (50 ตัวอย่าง) แถวที่สอง ([0 47 3]): Versicolor โมเดลทำนาย ผิด 3 ตัวอย่าง เป็น Virginica แถวที่สาม ([0 2 48]): Virginica โมเดลทำนาย ผิด 2 ตัวอย่าง เป็น Versicolor จากตัวอย่างนี้ เราได้เรียนรู้กระบวนการวิเคราะห์ข้อมูลและก

การทำนายผลลัพธ์ในลักษณะ "ใช่หรือไม่ใช่" เป็นงานที่พบได้บ่อยในหลายๆ สถานการณ์ เช่น การทำนายว่าลูกค้าจะซื้อสินค้าหรือไม่ การประเมินความเสี่ยงในการเป็นเบาหวาน หรือการตัดสินใจว่าใบสมัครงานจะได้รับการพิจารณาหรือไม่
หนึ่งในวิธีที่นิยมใช้ในการทำนายผลลัพธ์ในลักษณะนี้ คือ Logistic Regression ซึ่งเป็นโมเดลทางสถิติที่ใช้สำหรับการจำแนกประเภทในรูปแบบ binary classification
Logistic Regression จะคำนวณ ความน่าจะเป็น (probability) ที่ผลลัพธ์จะเป็น "ใช่" โดยค่าที่ได้จะอยู่ระหว่าง 0 และ 1 ซึ่งสามารถใช้ในการตัดสินใจว่าเราควรทำนายเป็น "ใช่" หรือ "ไม่ใช่" ตามเกณฑ์ที่กำหนด (เช่น ถ้าค่าความน่าจะเป็นมากกว่าหรือเท่ากับ 0.5 จะทำนายเป็น "ใช่")
Logistic Regression ช่วยให้เราสร้างโมเดลที่สามารถทำนายผลลัพธ์ได้อย่างมีประสิทธิภาพจากข้อมูลที่มีอยู่ และเป็นเครื่องมือที่ได้รับความนิยมในงานวิจัยและการประยุกต์ใช้ในหลากหลายด้าน ไม่ว่าจะเป็นการตลาด การแพทย์ หรือการประเมินความเสี่ยงในธุรกิจต่างๆ.
ในบทความนี้ เราจะมาดูการใช้งาน Logistic Regression ในภาษา Python โดยใช้ชุดข้อมูลที่มีชื่อว่า Iris Dataset ซึ่งเป็นชุดข้อมูลที่ได้รับความนิยมในงานวิเคราะห์ข้อมูลและใช้ในการสอนสร้างโมเดล Machine Learning เบื้องต้น
ชุดข้อมูล Iris ประกอบด้วยข้อมูลลักษณะต่างๆ ของดอกไม้ เช่น ความยาวกลีบเลี้ยง (sepal length) ความกว้างกลีบเลี้ยง (sepal width) ความยาวกลีบดอก (petal length) และความกว้างกลีบดอก (petal width) โดยเราจะใช้ข้อมูลเหล่านี้ในการจำแนกว่า ดอกไม้แต่ละดอกเป็นสายพันธุ์ Setosa Versicolor หรือ Virginica.
ขั้นตอนที่ 1 Import ไลบรารีที่จำเป็น
ขั้นตอนที่ 2 โหลดข้อมูลจากไฟล์ CSV
ตัวอย่างของข้อมูลสามารถโหลดได้ตามนี้เลย
https://raw.githubusercontent.com/aero971/Logestic_Regression_on_iris_dataset/refs/heads/main/Iris.csv
โหลดข้อมูลจากไฟล์ CSV เข้ามาในตัวแปร df (ย่อมาจาก DataFrame) ซึ่งเป็นโครงสร้างข้อมูลแบบตารางของ Pandas และ แสดงข้อมูล 5 แถวแรก
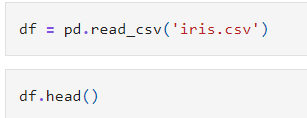
ตัวอย่างผลที่ได้จากโค้ด

ขั้นตอนที่ 3 ตรวจสอบขนาดของ DataFrame
เพื่อแสดงขนาดของตารางข้อมูลว่ามีกี่แถวกี่ Colum จะได้เข้าใจขอบเขตของข้อมูล
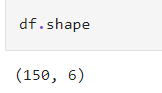
แสดงขนาดของตารางข้อมูล DataFrame ซึ่งผลลัพธ์คือ (150, 6) หมายความว่ามี 150 แถว 6 คอลัมน์
ขั้นตอนที่ 4 ตรวจสอบข้อมูลเบื้องต้น
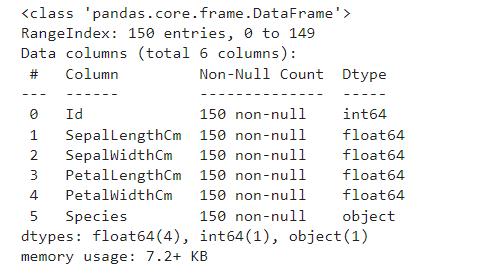
เราต้องเช็คสภาพข้อมูลก่อนที่จะใช้งานจริง เพื่อให้แน่ใจว่าข้อมูลสะอาด พร้อมใช้งาน และ เข้าใจข้อมูลที่เรากำลังจะวิเคราะห์
![]()
ตัวอย่างผลลัพธ์ที่ได้
ขั้นตอนที่ 6 ตรวจสอบจำนวนของแต่ละประเภทดอกไม้
เราจะนับจำนวนตัวอย่างของแต่ละสายพันธุ์ใน Colum Species เพื่อตรวจสอบความสมดุลของแต่ละ Class
![]()
ผลลัพธ์ที่ได้
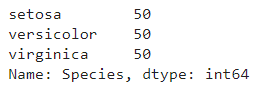
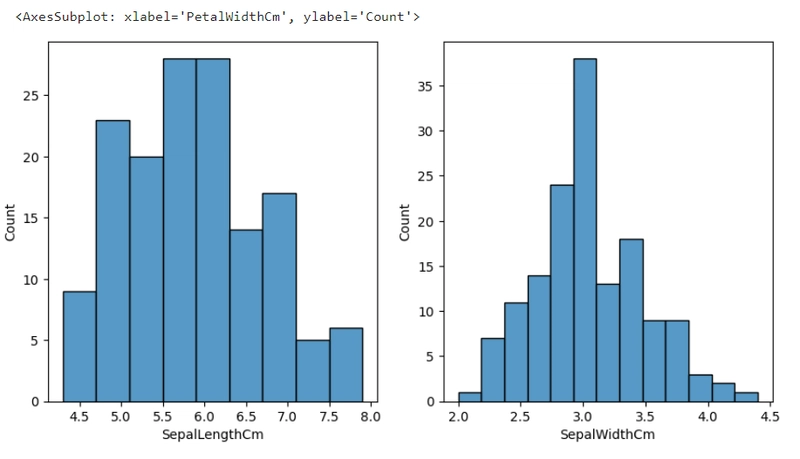
ขั้นตอนที่ 7 สร้าง Histogram
ต่อมาเราจะมาสร้างแผนภูมิแทง ด้วยไลบรารี matplotlib และ seaborn เพื่อดูการกระจายของข้อมูล (distribution) ของแต่ละฟีเจอร์ใน DataFrame โดยเฉพาะคอลัมน์ที่เกี่ยวกับความยาวและความกว้างของกลีบดอกและกลีบเลี้ยง

ผลลัพธ์
ความยาวและความกว้างกลีบเลี้ยง
ความยาวและความกว้างของกลีบดอก
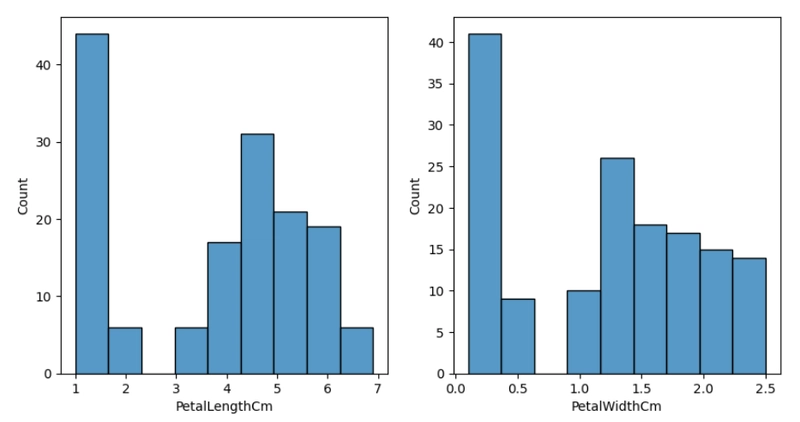
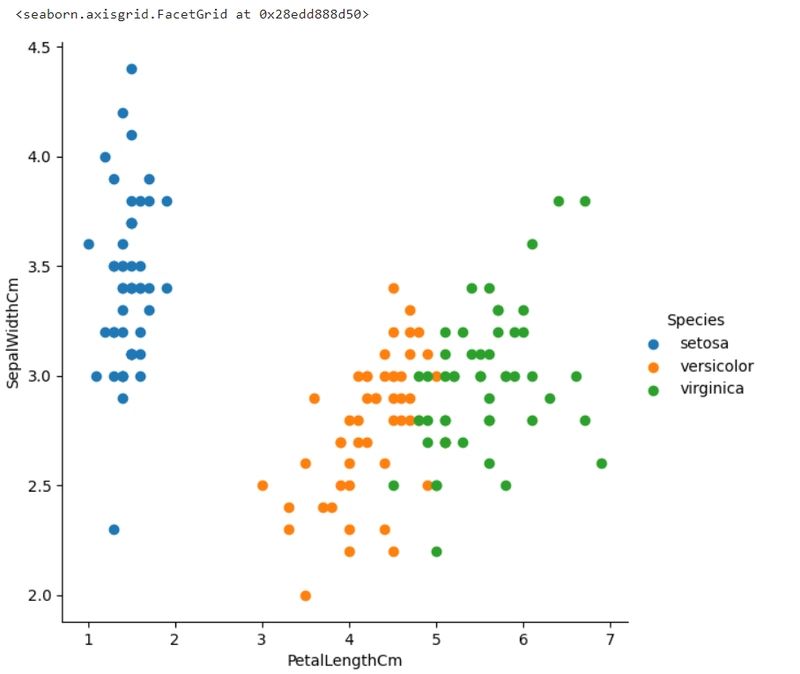
ต่อมาเราจะใช้ FacetGrid จาก seaborn เพื่อแสดง ความสัมพันธ์ระหว่างตัวแปร 2 ตัว (PetalLengthCm และ SepalWidthCm) โดยแยกตามค่าในคอลัมน์ Species (ชนิดของดอก)

ผลลัพธ์
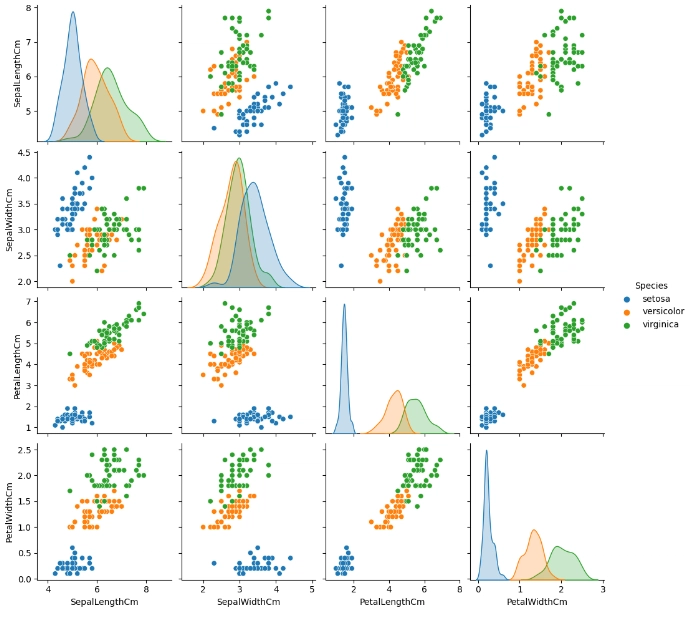
ต่อมาเราจะลบ ID ออกเนื่องจากไม่ได้ช่วยในการวิเคราะห์ และวาดกราฟจับคู่ตัวแปรทุกตัว และใช้สีแยกชนิดดอกไม้ตาม Species

ผลลัพธ์ที่ได้
ขั้นตอนที่ 8 สร้าง Boxplot 4 รูป
เราจะสร้างกราฟ Boxplot 4 รูปเพื่อเปรียบเทียบค่าความยาวและความกว้างของกลีบดอกและกลีบเลี้ยงของดอกไม้แต่ละสายพันธุ์ในชุดข้อมูล DataFrame โดยใช้ Seaborn และ Matplotlib จัดวางในรูปแบบ 2x2 บนพื้นที่ขนาด 16x9 นิ้ว ช่วยให้เห็นการกระจายตัวและค่าผิดปกติของแต่ละชนิดดอกไม้ได้ชัดเจน
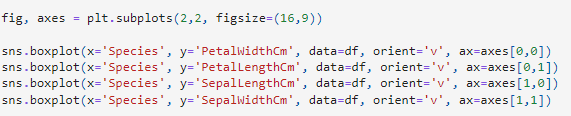
ผลลัพธ์

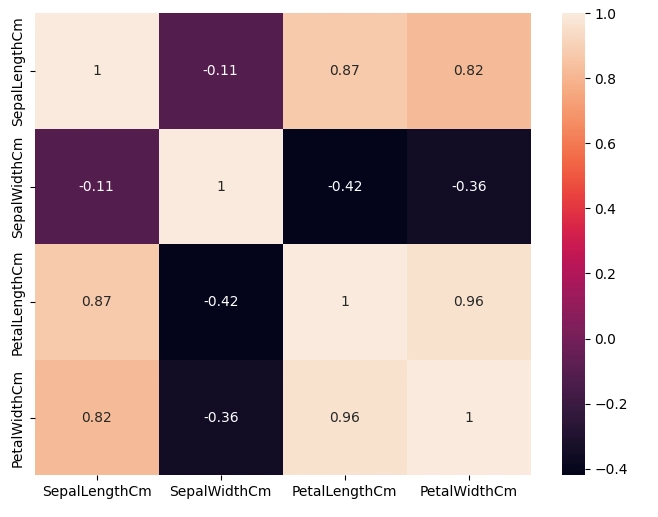
ต่อมาเราจะสร้าง heatmap แสดงค่า correlation ระหว่างคุณลักษณะของดอกไม้ในชุดข้อมูล DataFrame โดยที่เราจะลบคอลัมน์ Id ออก เพราะไม่ใช่ข้อมูลเชิงวิเคราะห์ และคำนวณค่า Pearson correlation ระหว่างแต่ละ feature พร้อมทั้งแสดง heatmap พร้อมตัวเลขในแต่ละช่อง

เราจะใช้ figsize=(8,6) เพื่อกำหนดขนาดแผนภาพให้พอดี ดูชัด เข้าใจง่ายว่า feature ไหนมีความสัมพันธ์กันสูง
ผลลัพธ์
ขั้นตอนที่ 9 สร้างโมเดล Logistic Regression
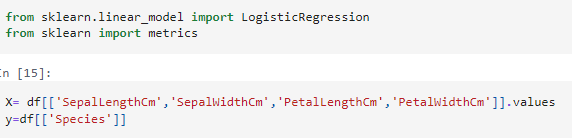
เราจะใช้ Logistic Regression เพื่อจำแนกชนิดของดอกไม้ (Species) โดยอิงจากคุณลักษณะ 4 อย่าง ได้แก่ SepalLengthCm SepalWidthCm PetalLengthCm และ PetalWidthCm
โดยที่ X คือ ตัวแปรอิสระ (features) แปลงจาก DataFrame
เป็น array เพื่อให้โมเดลใช้ได้
y คือ ตัวแปรตาม (target) ยังอยู่ในรูปแบบ DataFrame

ผลลัพธ์
![]()
ต่อมาเราจะมาดูความแม่นยำของโมเดลกัน
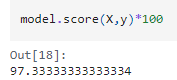
ผลลัพธ์คือ 97.33 แสดงให้เห็นว่ามีความแม่นยำสูง
ต่อมาเราจะมาทำนายผลลัพธ์จากโมเดลที่เราสร้างและฝึกมาแล้ว เพื่อทำนายผลจากข้อมูลทดสอบ (Test Data)

ผลลัพธ์

เรามาดูผลการประเมินโมเดลแบบละเอียดกัน
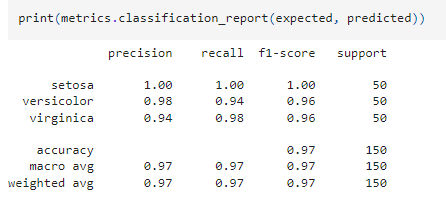
ผลลัพธ์ที่ได้
- Setosa มี precision และ recall เท่ากับ 1.00 หมายความว่าโมเดลสามารถทำนาย Setosa ได้ถูกต้องทั้งหมด
- Versicolor และ Virginica มี precision และ recall ใกล้เคียง 1.00 เช่นกัน
- Accuracy (ค่าความแม่นยำโดยรวม) คือ 98% ซึ่งแสดงว่าโมเดลทำนายได้ถูกต้อง 98% ของทั้งหมด
สุดท้ายนี้เราใช้ confusion matrix ซึ่งเป็นเครื่องมือในการประเมินประสิทธิภาพของโมเดลโดยการเปรียบเทียบ ค่าทำนาย (predicted) กับ ค่าจริง (expected) ของข้อมูลทดสอบ
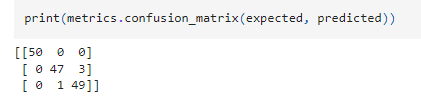
เราใช้โมเดลจำแนกประเภทดอกไม้ 3 ชนิด (Setosa Versicolor และ Virginica)
ผลลัพธ์ที่ได้ แสดงให้เห็นว่า
- แถวแรก ([50 0 0]): Setosa โมเดลทำนาย ถูกต้องทั้งหมด (50 ตัวอย่าง)
- แถวที่สอง ([0 47 3]): Versicolor โมเดลทำนาย ผิด 3 ตัวอย่าง เป็น Virginica
- แถวที่สาม ([0 2 48]): Virginica โมเดลทำนาย ผิด 2 ตัวอย่าง เป็น Versicolor
จากตัวอย่างนี้ เราได้เรียนรู้กระบวนการวิเคราะห์ข้อมูลและการจำแนกประเภทด้วย Logistic Regression อย่างเป็นระบบ ตั้งแต่การทำความเข้าใจข้อมูล การวิเคราะห์ผ่านกราฟ จนถึงการประเมินโมเดลอย่างรอบด้าน โดยใช้เครื่องมือสำคัญในภาษา Python
ตัวอย่างเพิ่มเติม
เราจะมาลองใช้ข้อมูลอื่นบ้าง โดยชุดข้อมูลต่อมาที่เราจะใช้กันนั้นก็คือ ข้อมูลของมิจฉาชีพ (scampass) ซึ่งเราจะมาจำแนกว่าเป็นมิจฉาชีพหรือไม่ จากข้อมูลเบอร์โทรหรือบัญชีธนาคาร ซึ่งเป็นข้อมูลที่น่าสนใจ เราจะมาลองจำแนกด้วย Logistic Regression เช่นกันกับตัวอย่างที่แล้ว
ข้อมูล scampass ประกอบด้วย 60 แถว 7 คอลัมน์
- num_reports (จำนวนครั้งที่มีคนรายงานหมายเลขนี้ว่าเป็นสแปมหรือหลอกลวง)
- is_foreign_number (เป็นเบอร์ต่างประเทศหรือไม่)
- account_age_days (จำนวนวันที่บัญชีหรือเบอร์นี้เปิดใช้งาน)
- transaction_count (จำนวนธุรกรรมที่ทำผ่านบัญชีหรือเบอร์นี้)
- avg_transaction_amount (ยอดเฉลี่ยของธุรกรรม)
- used_in_known_cases (เคยปรากฏในคดีหรือข่าวมาก่อน)
- is_scam (เป็นมิจฉาชีพหรือไม่)
ขั้นตอนที่ 1 mport Libraries

ขั้นตอนที่ 2 Load Dataset
ตัวอย่างของข้อมูลสามารถโหลดได้ตามนี้เลย
https://raw.githubusercontent.com/kessarin22/datascampass/refs/heads/main/scampass.csv
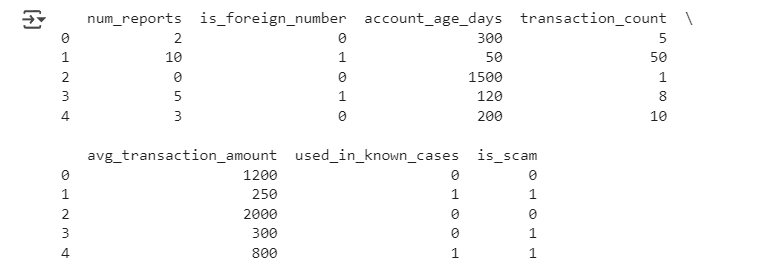
โหลดข้อมูลจากไฟล์ CSV ชื่อ scampass.csv และ แสดง 5 แถวแรกของข้อมูลแสดงข้อมูล 5 แถวแรก
ผลลัพธ์
ขั้นตอนที่ 3 ตรวจสอบข้อมูลเบื้องต้น
เราจะดูขนาดข้อมูล และรายละเอียดของคอลัมน์ พร้อมทั้งดูว่าข้อมูลในคอลัมน์ is_scam มีจำนวน class เท่าไร เพื่อให้แน่ใจว่าข้อมูลสะอาด พร้อมใช้งาน และ เข้าใจข้อมูลที่เรากำลังจะวิเคราะห์
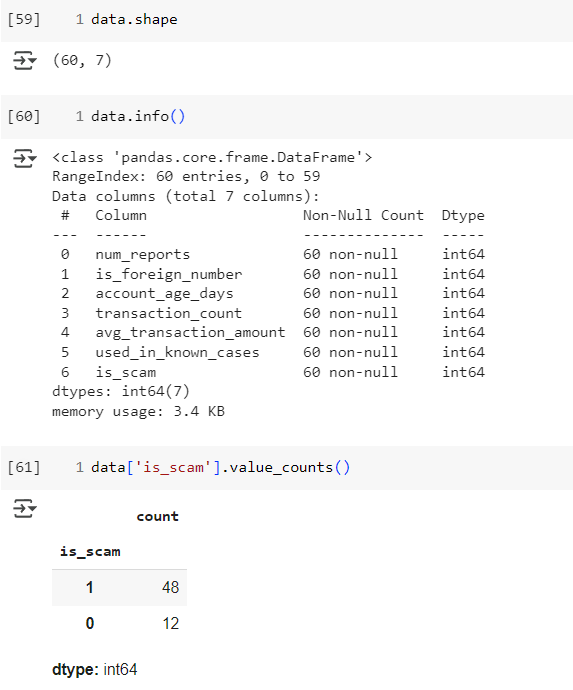
จะสังเกตุเห็นว่า class ของเราไม่สมดุล เพราะ class 0 1มีเยอะกว่า class 1 เราจะไปแก้ปัญหากันที่ขั้นตอนที่ ....
ขั้นตอนที่ 4 แยก Features และ Target

X คือ features ข้อมูลจริงที่ใช้ในการทำนาย ก็คือทุกคอลัมน์ยกเว้น is_scam
y คือ target สิ่งที่ต้องการทำนาย คือคอลัมน์ is_scam
ขั้นตอนที่ 5 แบ่งข้อมูล train/test
เราจะแบ่งข้อมูล 80% สำหรับ train, 20% สำหรับ test และใช้ random_state=42 เพื่อให้ผลเหมือนกันทุกครั้งที่รัน
![]()
ขั้นตอนที่ 6 สร้างโมเดล Logistic Regression
เราจะแก้ปัญหาข้อมูล class ไม่สมดุลด้วยการใช้ class_weight='balanced' โมเดลจะชดเชยให้ class ที่น้อยมีน้ำหนักมากขึ้น ถ้าเราไม่แก้ปัญหา class ไม่สมดุล โมเดลอาจทายแต่ class 0 แล้วได้ accuracy สูง แต่ไม่ได้ช่วยให้ตรวจจับมิจฉาชีพได้จริง

ต่อมาก็มาทำนายข้อมูล test กันเลย
![]()
ขั้นตอนที่ 8 แสดง Confusion Matrix
เราจะสร้าง confusion matrix เพื่อเปรียบเทียบผลจริงกับผลทำนาย และใช้ seaborn วาดเป็น heatmap เพื่อดูผลที่ชัดเจน
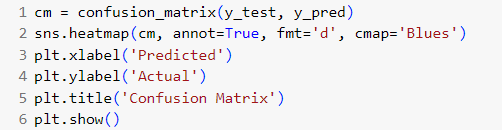
ผลลัพธ์

เราจะอธิบายผลลัพธ์แต่ละค่า โดยเรียงจากช่องซ้ายบนสุดไปขวา ดูจากเลขในช่อง
True Negative (TN) = 2 → ทำนายว่าไม่เป็นมิจฉาชีพ แต่ไม่เป็นจริง
False Positive (FP) = 1 → ทำนายว่าเป็นมิจฉาชีพ แต่ไม่ใช่
False Negative (FN) = 1 → ทำนายว่าไม่เป็นมิจฉาชีพ แต่จริง ๆ เป็น
True Positive (TP) = 8 → ทำนายว่าเป็นมิจฉาชีพ และเป็นจริง
แสดงให้เห็นว่าโมเดลสามารถ จับ scam ได้แม่นยำสูง (TP = 8 จาก 9 เคส)
ขั้นตอนที่ 9 แสดงผลลัพธ์
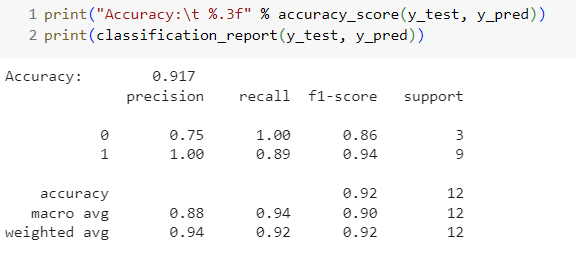
จะเห็นว่า ค่า Accuracy = 0.917 โมเดลสามารถจับมิจฉาชีพได้แม่นยำสูง
สุดท้ายเราจะมาดูว่า feature (ข้อมูลส่วนไหน) ส่งผลต่อการทำนายมากที่สุด โดยการแสดง Coefficients ของแต่ละ Feature
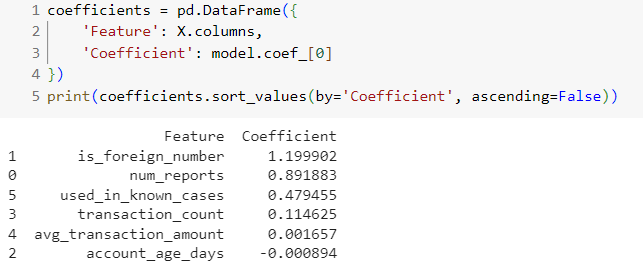
ผลลัพธ์ก็คือ เบอร์จากต่างประเทศ เพราะมีค่า Coefficients สูงที่สุด
สรุปผล
บทความนี้ได้แสดงตัวอย่างการทำ Logistic Regression ด้วยข้อมูล 2 ชุด ได้แก่ ชุดข้อมูล Iris และ Scampass ซึ่งทั้งสองชุดข้อมูลนี้ถูกเลือกมาเพื่อเน้นการแยกประเภท (classification) และแสดงให้เห็นถึงวิธีการใช้ Logistic Regression ในการทำนายและแยกประเภทข้อมูลตามลักษณะต่าง ๆ
การใช้ Logistic Regression ในทั้งสองชุดข้อมูลนี้ทำให้เราเห็นถึงความยืดหยุ่นและความสามารถในการทำงานของโมเดลในการแยกประเภทข้อมูลที่มีคุณลักษณะหลากหลาย อีกทั้งยังสามารถนำไปประยุกต์ใช้กับชุดข้อมูลที่หลากหลายประเภทในงานด้านการจำแนกประเภทต่อไปได้
referent : https://github.com/aero971/Logestic_Regression_on_iris_dataset






