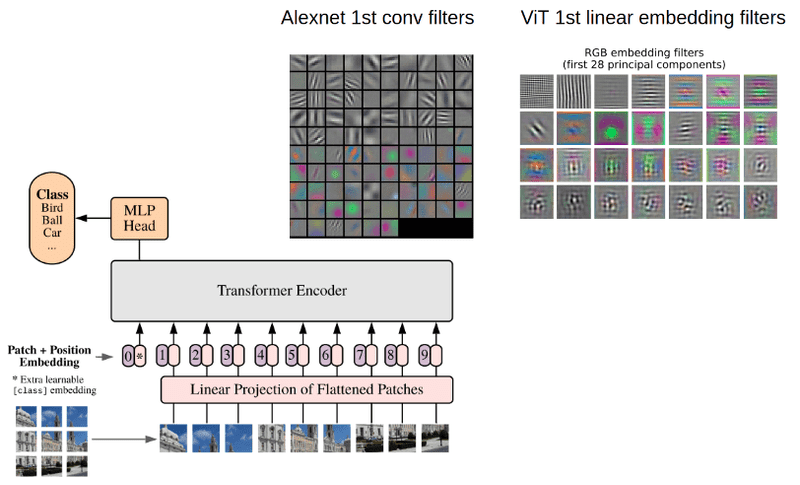
























































Vision Language models: towards multi-modal deep learning
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL
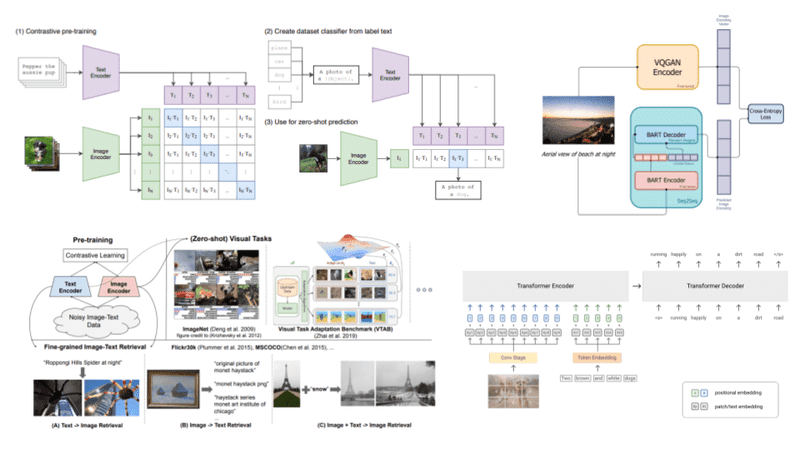
A review of state of the art vision-language models such as CLIP, DALLE, ALIGN and SimVL