
























































Vacuum your Apache Iceberg table with Athena and Step Functions with this Terraform module
Apache Iceberg tables are a cost-effective solution to store tabular data, run ACID transactions and analytics at scale, and effectively the foundation of most data lakes. However, since Iceberg tables retain snapshot data (enabling time travel queries), as data gets updated the table storage can grow indefinitely. Vacuum is then required to expire snapshots and remove orphan data files. How Apache Iceberg stores your data I'll quote from the Apache Iceberg documentation there: Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table. As update, delete and insert queries are performed on your Iceberg table, for instance when performing Change Data Capture on a relational database with Firehose, your table storage grows. Vacuuming it will save you a lot on storage. Vacuuming a table can be done in multiple ways (using Glue or any Iceberg client, for instance). Using Amazon Athena is an interesting approach as the compute used to perform vacuuming is provided for free by AWS (whatever the solution, you still pay for the underlying S3 queries). Introducing the Iceberg Vacuum Cleaner Terraform module Today, I'm glad to release the Iceberg Vacuum Cleaner Terraform module, that will help you deploy a serverless solution to perform vacuuming of your whole Database. This module will deploy an AWS Step Functions state machine (and an EventBridge Scheduler) that will: list all Iceberg table within a user-defined Glue database for each table, perform a "VACUUM " query using Amazon Athena. How the Iceberg Vacuum Cleaner vacuums a full Iceberg-based database Two types of state machines are provided: Sequential queries: this mode enables you to vacuum tables one by one. While slower, it will not consume your AWS Athena DML quota Concurrent queries: a Map state will trigger a sub workflow for each table. In both cases, the state machine will perform retries: If Athena rejects a StartQueryExecution API call by throwing a TooManyRequestsException (which means you've reach the max concurrency... ask for a Quota increase to speed up the process) If Athena Query Execution fails with the "ICEBERG_VACUUM_MORE_RUNS_NEEDED: Removed 20000 files in this round of vacuum" error, which means it needs to be ran again the finish the vacuuming process. A cost-effective solution Apart from S3 costs (which you'll pay whatever the solution) you'll pay only for the Step Functions state transitions $0.025 per 1000 transitions (with 4,000 transitions included in monthly free tier). I've run these step functions workflow on a 80 tables database. Sequential run used 300 state transitions (costing $0.0075, yes that's less than a cent!) and lasted 4h21min Concurrent run (with the default 20 DML quota) used 650 state transitions, costing $0.01625, running for 1h20min. I hope you'll enjoy this solution! If you do or hit any difficulty in using this module, please provide feedback here or via GitHub! My name is Paul SANTUS, I'm an independent Consultant on all-things AWS. You can follow me here or connect on LinkedIn!
Apache Iceberg tables are a cost-effective solution to store tabular data, run ACID transactions and analytics at scale, and effectively the foundation of most data lakes.
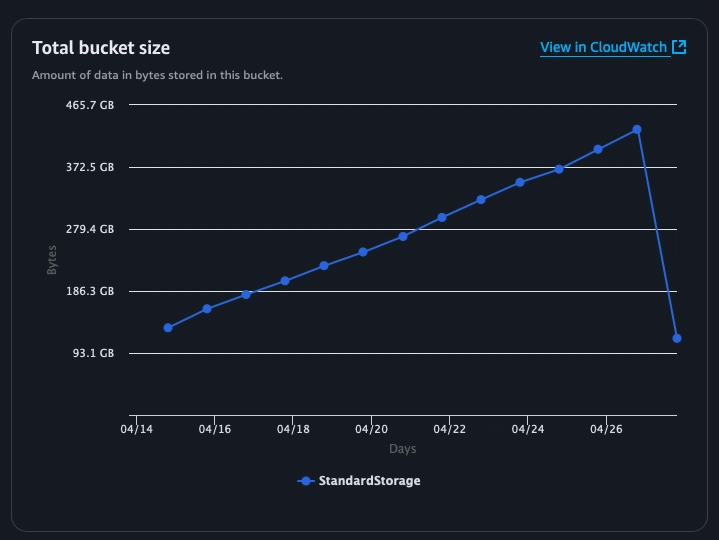
However, since Iceberg tables retain snapshot data (enabling time travel queries), as data gets updated the table storage can grow indefinitely. Vacuum is then required to expire snapshots and remove orphan data files.
How Apache Iceberg stores your data
I'll quote from the Apache Iceberg documentation there:
Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
As update, delete and insert queries are performed on your Iceberg table, for instance when performing Change Data Capture on a relational database with Firehose, your table storage grows. Vacuuming it will save you a lot on storage.
Vacuuming a table can be done in multiple ways (using Glue or any Iceberg client, for instance). Using Amazon Athena is an interesting approach as the compute used to perform vacuuming is provided for free by AWS (whatever the solution, you still pay for the underlying S3 queries).
Introducing the Iceberg Vacuum Cleaner Terraform module
Today, I'm glad to release the Iceberg Vacuum Cleaner Terraform module, that will help you deploy a serverless solution to perform vacuuming of your whole Database.
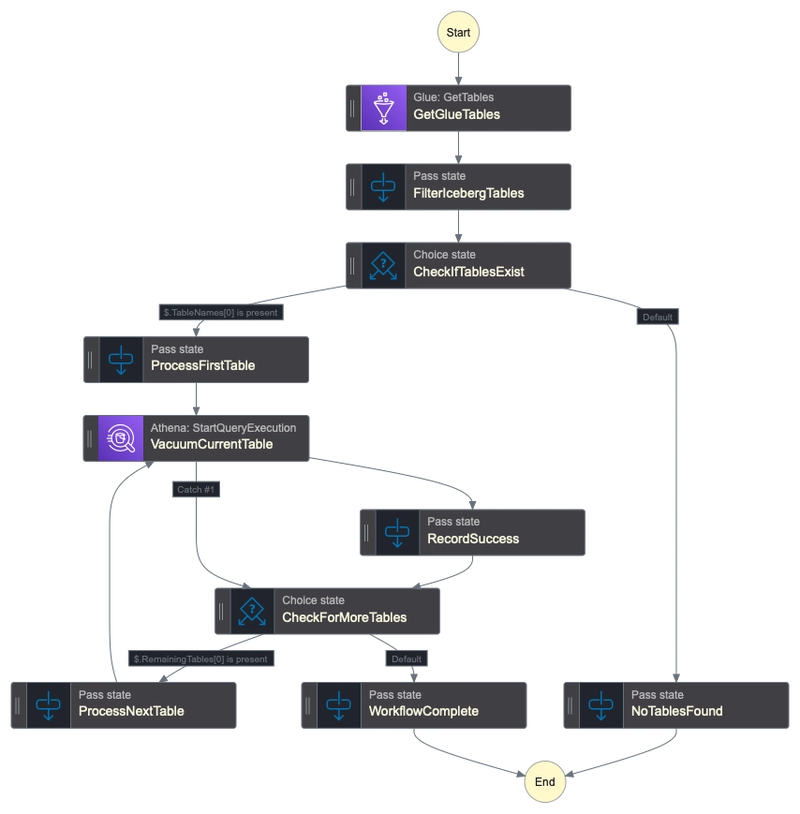
This module will deploy an AWS Step Functions state machine (and an EventBridge Scheduler) that will:
- list all Iceberg table within a user-defined Glue database
- for each table, perform a "VACUUM
" query using Amazon Athena.
How the Iceberg Vacuum Cleaner vacuums a full Iceberg-based database
Two types of state machines are provided:
Sequential queries: this mode enables you to vacuum tables one by one. While slower, it will not consume your AWS Athena DML quota
Concurrent queries: a Map state will trigger a sub workflow for each table.
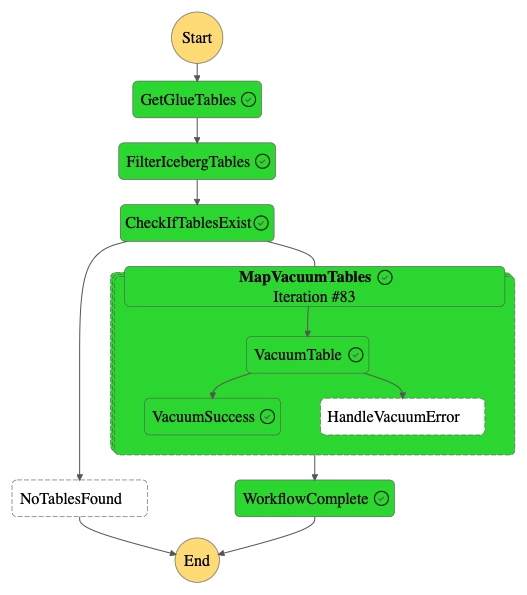
In both cases, the state machine will perform retries:
- If Athena rejects a StartQueryExecution API call by throwing a TooManyRequestsException (which means you've reach the max concurrency... ask for a Quota increase to speed up the process)
- If Athena Query Execution fails with the "ICEBERG_VACUUM_MORE_RUNS_NEEDED: Removed 20000 files in this round of vacuum" error, which means it needs to be ran again the finish the vacuuming process.
A cost-effective solution
Apart from S3 costs (which you'll pay whatever the solution) you'll pay only for the Step Functions state transitions $0.025 per 1000 transitions (with 4,000 transitions included in monthly free tier).
I've run these step functions workflow on a 80 tables database.
- Sequential run used 300 state transitions (costing $0.0075, yes that's less than a cent!) and lasted 4h21min
- Concurrent run (with the default 20 DML quota) used 650 state transitions, costing $0.01625, running for 1h20min.
I hope you'll enjoy this solution! If you do or hit any difficulty in using this module, please provide feedback here or via GitHub!
 My name is Paul SANTUS, I'm an independent Consultant on all-things AWS. You can follow me here or connect on LinkedIn!
My name is Paul SANTUS, I'm an independent Consultant on all-things AWS. You can follow me here or connect on LinkedIn!