




































































Learn How to Build Robust RAG Applications Using Llama 4!
Exciting developments are unfolding in the AI landscape with Meta's introduction of the Llama 4 models. This blog will delve into the features and capabilities of these advanced models, including Llama 4 Scout, Llama 4 Maverick, and Llama 4 Behemoth, and provide a step-by-step tutorial on building a robust RAG system using Llama 4 Maverick. Introduction to Llama 4 Models The Llama 4 models from Meta represent a significant leap in artificial intelligence technology. These models are designed to cater to diverse needs, ranging from lightweight tasks to complex data analysis. With a focus on open-source availability, Meta aims to democratize access to advanced AI capabilities, enabling developers and researchers to leverage cutting-edge tools in their projects. Llama 4 models stand out due to their versatility and performance. By offering various configurations, they allow users to choose a model that best fits their specific requirements. This flexibility is crucial in a landscape where the demands on AI systems are ever-increasing. Overview of Llama 4 Scout Llama 4 Scout is the smallest and fastest model in the Llama 4 lineup. It is engineered for efficiency, making it ideal for light AI tasks and applications that require a long memory. With the capability to handle up to ten million tokens of context, Scout leads the industry in context length. Use Cases for Llama 4 Scout Lightweight AI Tasks: Perfect for applications that require quick responses. Long Memory Applications: Its extensive context length allows it to maintain relevant information over extended interactions. Research and Development: An excellent choice for prototyping and testing new ideas in AI. Features of Llama 4 Maverick Llama 4 Maverick is the powerhouse of the Llama 4 series. With 17 million active parameters and 128 experts, it offers unmatched performance in various applications. Its multimodal capabilities allow it to process different types of data seamlessly, making it a top choice for developers. Key Features of Llama 4 Maverick High Performance: Surpasses similar models, including GPT-4, in speed and reliability. Multimodal Capabilities: Handles text, images, and other data types efficiently. Scalability: Suitable for both small-scale projects and large enterprise applications. The Intelligence of Llama 4 Behemoth Llama 4 Behemoth is described as the smartest model in the series. Though not yet publicly available, it promises to deliver advanced AI capabilities that can handle complex tasks requiring deep understanding and reasoning. Potential Applications of Llama 4 Behemoth Internal Distillation: Ideal for organizations looking to refine their AI models. Benchmarking: Can serve as a reference point for evaluating other AI models. Complex Problem Solving: Designed for tasks that require higher cognitive functions. Performance Comparison on LM Arena Leaderboard The performance of Llama 4 models on the LM Arena Leaderboard speaks volumes about their capabilities. Llama 4 Maverick consistently ranks at the top, outperforming models like GPT-4 and DeepSea Carbon. Credits: LMArena Insights from the LM Arena Leaderboard Top Performer: Llama 4 Maverick's performance is unmatched in its class. Value Proposition: Offers superior performance at a competitive cost. Real-World Applications: Demonstrated effectiveness in diverse scenarios, from coding to enterprise solutions. Detailed Model Comparisons A comprehensive comparison of the Llama 4 models reveals distinct strengths and ideal use cases. Understanding these differences helps users select the right model for their specific needs. Credits: Analytics Vidhya Hands-On with Llama 4: Setting Up the RAG System! Building a RAG (Retrieval-Augmented Generation) system using Llama 4 Maverick is straightforward. This system can efficiently retrieve and generate responses based on user queries. We will be using LangChain, the open-source LLM framework to build this RAG setup along with SingleStore. Step-by-Step Guide to Setup Choose Your Database: Select a vector database such as SingleStore to store your embeddings. Load Your Data: Ingest a document, such as a PDF file, and create text chunks. Create Embeddings: Use an embedding model to convert your text chunks into vector embeddings. Store Embeddings: Save the vector embeddings in your selected database. Query the Model: Convert user queries into vector embeddings and retrieve relevant information from the database. Generate Responses: Use Llama 4 Maverick to generate contextually relevant responses based on the retrieved data. Initializing Llama 4 Maverick via OpenRouter Setting up Llama 4 Maverick is straightforward with OpenRouter. This platform provides a user-friendly interface for accessing advanced AI models. Begin by signing up at OpenRouter and creating y
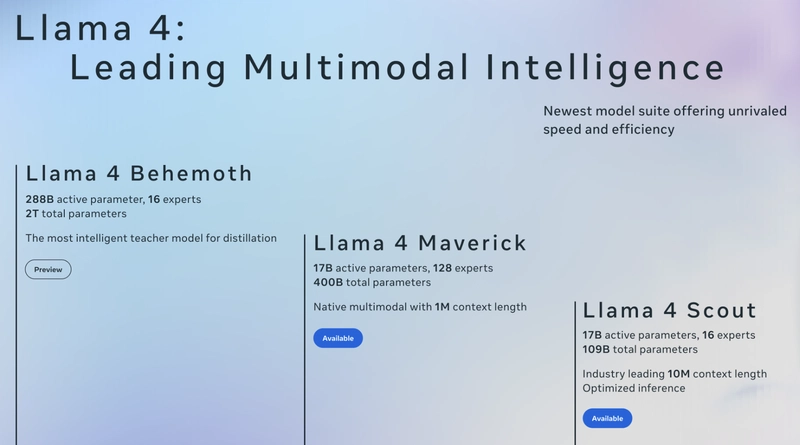
Exciting developments are unfolding in the AI landscape with Meta's introduction of the Llama 4 models. This blog will delve into the features and capabilities of these advanced models, including Llama 4 Scout, Llama 4 Maverick, and Llama 4 Behemoth, and provide a step-by-step tutorial on building a robust RAG system using Llama 4 Maverick.
Introduction to Llama 4 Models
The Llama 4 models from Meta represent a significant leap in artificial intelligence technology. These models are designed to cater to diverse needs, ranging from lightweight tasks to complex data analysis. With a focus on open-source availability, Meta aims to democratize access to advanced AI capabilities, enabling developers and researchers to leverage cutting-edge tools in their projects.
Llama 4 models stand out due to their versatility and performance. By offering various configurations, they allow users to choose a model that best fits their specific requirements. This flexibility is crucial in a landscape where the demands on AI systems are ever-increasing.
Overview of Llama 4 Scout
Llama 4 Scout is the smallest and fastest model in the Llama 4 lineup. It is engineered for efficiency, making it ideal for light AI tasks and applications that require a long memory. With the capability to handle up to ten million tokens of context, Scout leads the industry in context length.
Use Cases for Llama 4 Scout
- Lightweight AI Tasks: Perfect for applications that require quick responses.
- Long Memory Applications: Its extensive context length allows it to maintain relevant information over extended interactions.
- Research and Development: An excellent choice for prototyping and testing new ideas in AI.
Features of Llama 4 Maverick
Llama 4 Maverick is the powerhouse of the Llama 4 series. With 17 million active parameters and 128 experts, it offers unmatched performance in various applications. Its multimodal capabilities allow it to process different types of data seamlessly, making it a top choice for developers.
Key Features of Llama 4 Maverick
- High Performance: Surpasses similar models, including GPT-4, in speed and reliability.
- Multimodal Capabilities: Handles text, images, and other data types efficiently.
- Scalability: Suitable for both small-scale projects and large enterprise applications.
The Intelligence of Llama 4 Behemoth
Llama 4 Behemoth is described as the smartest model in the series. Though not yet publicly available, it promises to deliver advanced AI capabilities that can handle complex tasks requiring deep understanding and reasoning.
Potential Applications of Llama 4 Behemoth
- Internal Distillation: Ideal for organizations looking to refine their AI models.
- Benchmarking: Can serve as a reference point for evaluating other AI models.
- Complex Problem Solving: Designed for tasks that require higher cognitive functions.
Performance Comparison on LM Arena Leaderboard
The performance of Llama 4 models on the LM Arena Leaderboard speaks volumes about their capabilities. Llama 4 Maverick consistently ranks at the top, outperforming models like GPT-4 and DeepSea Carbon.
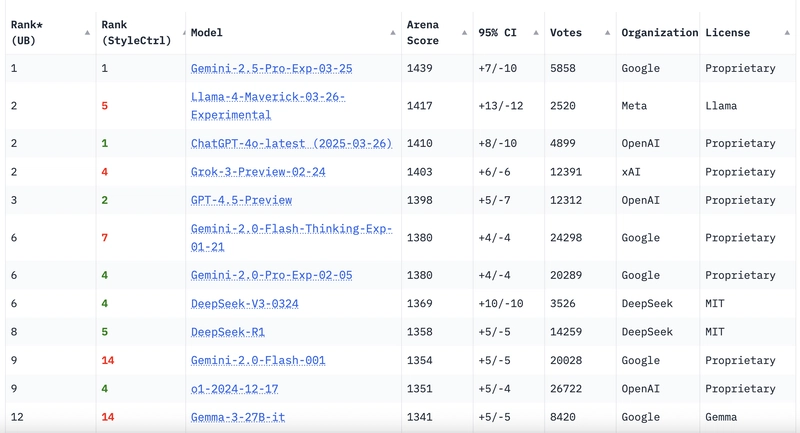
Credits: LMArena
Insights from the LM Arena Leaderboard
- Top Performer: Llama 4 Maverick's performance is unmatched in its class.
- Value Proposition: Offers superior performance at a competitive cost.
- Real-World Applications: Demonstrated effectiveness in diverse scenarios, from coding to enterprise solutions.
Detailed Model Comparisons
A comprehensive comparison of the Llama 4 models reveals distinct strengths and ideal use cases. Understanding these differences helps users select the right model for their specific needs.
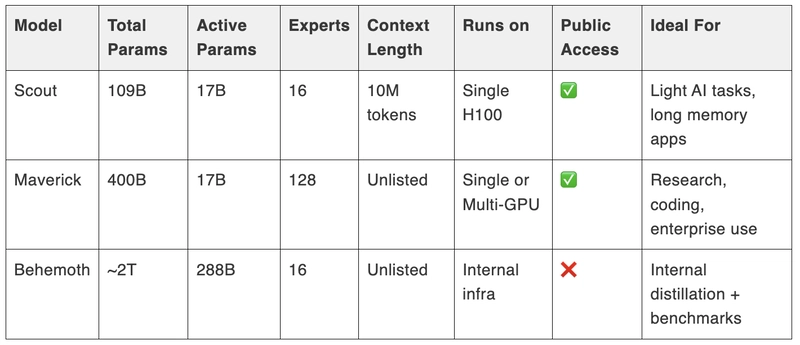
Credits: Analytics Vidhya
Hands-On with Llama 4: Setting Up the RAG System!
Building a RAG (Retrieval-Augmented Generation) system using Llama 4 Maverick is straightforward. This system can efficiently retrieve and generate responses based on user queries.
We will be using LangChain, the open-source LLM framework to build this RAG setup along with SingleStore.
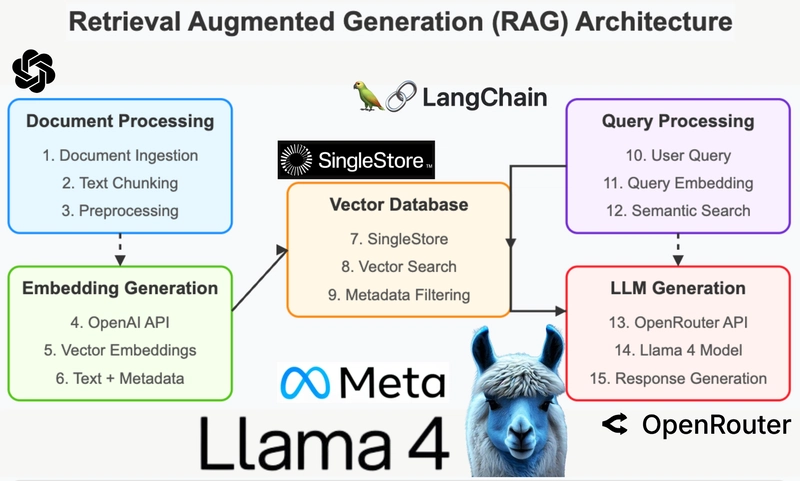
Step-by-Step Guide to Setup
- Choose Your Database: Select a vector database such as SingleStore to store your embeddings.
- Load Your Data: Ingest a document, such as a PDF file, and create text chunks.
- Create Embeddings: Use an embedding model to convert your text chunks into vector embeddings.
- Store Embeddings: Save the vector embeddings in your selected database.
- Query the Model: Convert user queries into vector embeddings and retrieve relevant information from the database.
- Generate Responses: Use Llama 4 Maverick to generate contextually relevant responses based on the retrieved data.
Initializing Llama 4 Maverick via OpenRouter
Setting up Llama 4 Maverick is straightforward with OpenRouter. This platform provides a user-friendly interface for accessing advanced AI models. Begin by signing up at OpenRouter and creating your API key.
Once you have your API key, you'll need to configure the model parameters. Adjust settings like temperature and max tokens according to your application's needs. A higher temperature can generate more creative responses, while a lower temperature produces more deterministic outputs.
After configuration, you can initialize the model. This step involves calling the OpenRouter API with your API key and model parameters, setting the stage for querying and generating responses.
Below is my complete RAG hands-on video
Here is the complete notebook code repo,
RAG Setup Using Llama 4 Maverick & LangChain
Prerequisites
- SingleStore free account - To use it as a vector database
- OpenRouter free account - A unified interface for LLMs
- OpenAI API Key - You can use any other models for embeddings (From Huggingface or Cohere, etc)
Exploring the Database and Hybrid Search Capabilities
One of the standout features of using a vector database like SingleStore is its hybrid search capabilities. This functionality allows you to combine traditional keyword searches with semantic searches, enhancing the retrieval process.
Hybrid search enables you to pull relevant data based on both keyword matches and context relevance. This dual approach ensures that users receive comprehensive results that are both accurate and contextually appropriate.
Understanding how to leverage these capabilities can significantly enhance your RAG system's performance. Regularly experiment with different search strategies to find the most effective combinations for your use case.
Benefits of Hybrid Search using SingleStore
Increased Accuracy: Combines the strengths of keyword and semantic searches for better retrieval.
Enhanced User Experience: Provides users with more relevant results, improving satisfaction and engagement.
Scalability: Adapts to growing datasets and evolving user needs without compromising performance.
Conclusion and Future Prospects
In conclusion, building a RAG system with Llama 4 Maverick is both feasible and rewarding. By effectively ingesting data, creating embeddings, and utilizing advanced querying techniques, you can develop a powerful AI application. The future of RAG systems look promising, with ongoing advancements in AI technology. As models like Llama 4 evolve, they will offer even greater capabilities, making it essential for developers to stay updated with the latest trends and techniques.
By continuously refining your system and embracing new features, you can ensure your RAG application remains at the forefront of AI innovation. The journey of exploration and development in this field is just beginning, and the possibilities are limitless.
Try the tutorial and don't forget to sign up to SingleStore and get your free account.





