























































How to train LLM faster
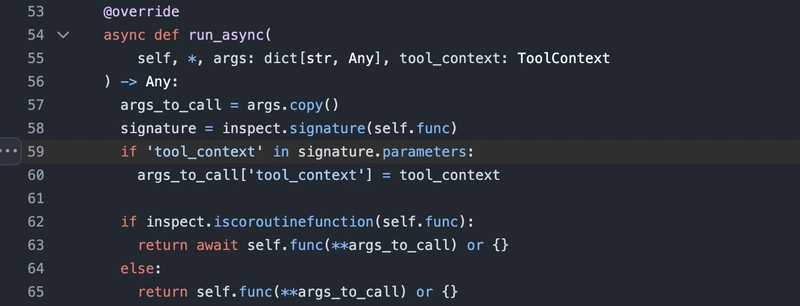
RAG is an architecture where an LLM (Large Language Model) is not asked to answer purely from its own parameters but is given external information at runtime to use while answering. ✅ Goal: Reduce hallucination. Answer based on updated, private, or niche data without re-training the model. Breaking Down RAG — Technical View 1. Retriever Input: A user query (like "What are the side effects of aspirin?") Goal: Find the most relevant information from an external knowledge source (documents, database, etc.) How: The user query is first passed through an embedding model (like OpenAI text-embedding-ada-002) that turns the text into a high-dimensional vector (like a list of 1536 numbers). Stored documents are already embedded beforehand into the same vector space. Use vector similarity search (cosine similarity, Euclidean distance, etc.) to find top k nearest documents. This is exactly like "nearest neighbors search" but in high-dimensional space.

RAG is an architecture where an LLM (Large Language Model) is not asked to answer purely from its own parameters but is given external information at runtime to use while answering.
✅ Goal:
- Reduce hallucination.
- Answer based on updated, private, or niche data without re-training the model.
Breaking Down RAG — Technical View
1. Retriever
- Input: A user query (like "What are the side effects of aspirin?")
- Goal: Find the most relevant information from an external knowledge source (documents, database, etc.)
-
How:
- The user query is first passed through an embedding model (like OpenAI
text-embedding-ada-002) that turns the text into a high-dimensional vector (like a list of 1536 numbers). - Stored documents are already embedded beforehand into the same vector space.
- Use vector similarity search (cosine similarity, Euclidean distance, etc.) to find top
knearest documents.
- The user query is first passed through an embedding model (like OpenAI
This is exactly like "nearest neighbors search" but in high-dimensional space.