





























































GPT-4.5 vs. Claude 3.7 Sonnet vs. Gemini 2.0 Flash: A No-Nonsense Guide
Large Language Models (LLMs) have become increasingly sophisticated, with companies stacking up impressive capabilities through new releases and updates. In the world of AI, advancement is constant, with models accumulating more parameters, training data, and fine-tuning techniques. This rapid evolution adds more value to both the general public and the tech community. But with all these various evolving models, how do we differentiate them from each other? Which one should we use for a particular task? In this article, we will dive into the latest flagship models from the three leading AI companies as of March 2025: OpenAI's GPT-4.5, Anthropic's Claude 3.7 Sonnet, and Google's Gemini 2.0 Flash. Each represents the cutting edge of what their respective developers have to offer. But before we compare them directly, let's clarify how a chatbot interface is a different entity than the underlying AI model powering it. Understanding the Core: Models vs Chatbots It's essential to distinguish between the LLM itself (the "model") and the platform through which we interact with it (the "chatbot"). Think of the LLM as the engine, the sophisticated algorithms and vast datasets that enable AI capabilities. The chatbot is the vehicle, the user interface that allows us to leverage that engine. One LLM can power multiple chatbots, and a single chatbot interface can offer access to various LLMs. According to the Chatbot Statistics 2025, over 987 million people use AI chatbots globally. It has grown quite an enormous number compared to the past years and among the top five are Meta AI, ChatGPT, Google Gemini, Microsoft Copilot, and Claude. Figure 1. Most Popular AI Chatbots Worldwide. Source: DemandSage (2025), '65 Chatbot Statistics for 2025 — New Data Released,' accessed March 18, 2025. Seeing how much the user base has grown, the need to address its key difference in identifying which would better fit for your needs is highly needed. Latest Advancements We'll focus on the core LLMs powering these platforms: OpenAI’s GPT-4o and GPT-4.5: GPT-4o: OpenAI's versatile multimodal model that processes text, audio, and images simultaneously. It offers fast, natural interactions while maintaining strong performance across various tasks. GPT-4.5: OpenAI's most advanced model, available exclusively to Pro users and developers. It features improved reasoning, a broader knowledge base, better alignment with user intent, and enhanced "emotional intelligence." While comprehensive benchmark data is limited, OpenAI claims reduced hallucination rates and more natural interactions. Anthropic’s Claude 3.7 Sonnet: Anthropic’s Sonnet can be categorized as Standard or Extended Thinking. Standard Mode: The latest iteration of Anthropic's Sonnet line, representing their most intelligent model to date. It combines strong reasoning with relatively fast processing. Extended Thinking Mode: An industry-first hybrid reasoning approach that enables visible step-by-step problem-solving. This mode allows Claude to analyze problems methodically, plan solutions, and consider multiple perspectives before responding. Google DeepMind’s Gemini 2.0 Flash: Building on the 1.5 Flash foundation, this model prioritizes speed and efficiency while delivering improvements in multimodal understanding, coding capabilities, complex instruction following, and function calling. It's specifically designed to power responsive, agentic experiences. AI Model Performance Comparison GPT-4o Claude 3.7 Sonnet (Standard) GPT-4.5 (Premium) Claude 3.7 Sonnet (Extended Thinking) Gemini 2.0 Flash Company OpenAI Anthropic OpenAI Anthropic Google DeepMind Released May 13, 2024 February 24, 2025 February 27, 2025 February 24, 2025 February 5, 2025 MMLU-Pro (Reasoning Knowledge) 77% 80% - 84% 78% GPQA Diamond (Scientific Reasoning) 51% 66% 71% 77% 62% MATH-500 (Quantitative Reasoning) 79% 84% - 95% 93% AIME 2024 (Competition Math) 11% 24% 37% (not yet verified) 49% HumanEval (Coding) 94% 92% - 98% 90% Speed (tokens per second) 116 81 13 82 250 Latency (lower is better) 0.48 0.41 0.78 0.38 0.31 Pricing per 1M Tokens (API) $15 $15 $75 $15 $0.4 Table 1. Key metrics comparison. Source of data: [Artificial Analysis (2025)](https://artificialanalysis.ai/), accessed March 18, 2025. Who Has the Best Intelligence Index? When it comes to reasoning capabilities, the data reveals some fascinating insights about today's leading models: Claude 3.7 Sonnet in Extended Thinking emerges as the clear reasoning champion across all benchmarks. This model excels across all reaso

Large Language Models (LLMs) have become increasingly sophisticated, with companies stacking up impressive capabilities through new releases and updates. In the world of AI, advancement is constant, with models accumulating more parameters, training data, and fine-tuning techniques. This rapid evolution adds more value to both the general public and the tech community. But with all these various evolving models, how do we differentiate them from each other? Which one should we use for a particular task?
In this article, we will dive into the latest flagship models from the three leading AI companies as of March 2025: OpenAI's GPT-4.5, Anthropic's Claude 3.7 Sonnet, and Google's Gemini 2.0 Flash. Each represents the cutting edge of what their respective developers have to offer. But before we compare them directly, let's clarify how a chatbot interface is a different entity than the underlying AI model powering it.
Understanding the Core: Models vs Chatbots
It's essential to distinguish between the LLM itself (the "model") and the platform through which we interact with it (the "chatbot"). Think of the LLM as the engine, the sophisticated algorithms and vast datasets that enable AI capabilities. The chatbot is the vehicle, the user interface that allows us to leverage that engine. One LLM can power multiple chatbots, and a single chatbot interface can offer access to various LLMs.
According to the Chatbot Statistics 2025, over 987 million people use AI chatbots globally. It has grown quite an enormous number compared to the past years and among the top five are Meta AI, ChatGPT, Google Gemini, Microsoft Copilot, and Claude.
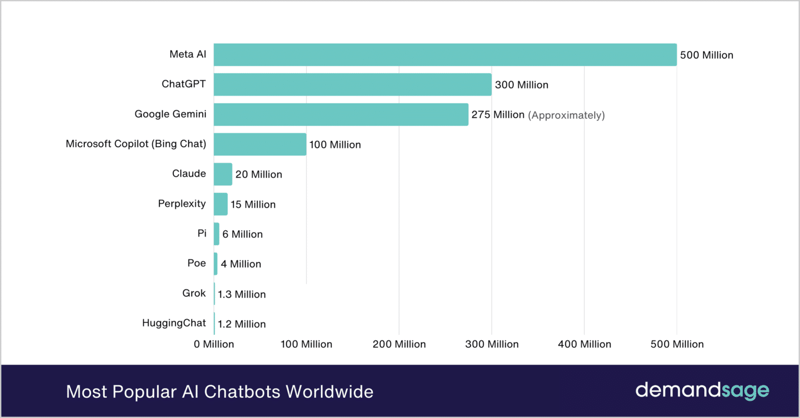
Figure 1. Most Popular AI Chatbots Worldwide. Source: DemandSage (2025), '65 Chatbot Statistics for 2025 — New Data Released,' accessed March 18, 2025.
Seeing how much the user base has grown, the need to address its key difference in identifying which would better fit for your needs is highly needed.
Latest Advancements
We'll focus on the core LLMs powering these platforms:
OpenAI’s GPT-4o and GPT-4.5:
- GPT-4o: OpenAI's versatile multimodal model that processes text, audio, and images simultaneously. It offers fast, natural interactions while maintaining strong performance across various tasks.
- GPT-4.5: OpenAI's most advanced model, available exclusively to Pro users and developers. It features improved reasoning, a broader knowledge base, better alignment with user intent, and enhanced "emotional intelligence." While comprehensive benchmark data is limited, OpenAI claims reduced hallucination rates and more natural interactions.
Anthropic’s Claude 3.7 Sonnet:
Anthropic’s Sonnet can be categorized as Standard or Extended Thinking.
- Standard Mode: The latest iteration of Anthropic's Sonnet line, representing their most intelligent model to date. It combines strong reasoning with relatively fast processing.
- Extended Thinking Mode: An industry-first hybrid reasoning approach that enables visible step-by-step problem-solving. This mode allows Claude to analyze problems methodically, plan solutions, and consider multiple perspectives before responding.
Google DeepMind’s Gemini 2.0 Flash:
Building on the 1.5 Flash foundation, this model prioritizes speed and efficiency while delivering improvements in multimodal understanding, coding capabilities, complex instruction following, and function calling. It's specifically designed to power responsive, agentic experiences.
AI Model Performance Comparison
| GPT-4o | Claude 3.7 Sonnet (Standard) | GPT-4.5 (Premium) | Claude 3.7 Sonnet (Extended Thinking) | Gemini 2.0 Flash | |
|---|---|---|---|---|---|
| Company | OpenAI | Anthropic | OpenAI | Anthropic | Google DeepMind |
| Released | May 13, 2024 | February 24, 2025 | February 27, 2025 | February 24, 2025 | February 5, 2025 |
| MMLU-Pro (Reasoning Knowledge) | 77% | 80% | - | 84% | 78% |
| GPQA Diamond (Scientific Reasoning) | 51% | 66% | 71% | 77% | 62% |
| MATH-500 (Quantitative Reasoning) | 79% | 84% | - | 95% | 93% |
| AIME 2024 (Competition Math) | 11% | 24% | 37% | (not yet verified) | 49% |
| HumanEval (Coding) | 94% | 92% | - | 98% | 90% |
| Speed (tokens per second) | 116 | 81 | 13 | 82 | 250 |
| Latency (lower is better) | 0.48 | 0.41 | 0.78 | 0.38 | 0.31 |
| Pricing per 1M Tokens (API) | $15 | $15 | $75 | $15 | $0.4 |
Who Has the Best Intelligence Index?
When it comes to reasoning capabilities, the data reveals some fascinating insights about today's leading models:
Claude 3.7 Sonnet in Extended Thinking emerges as the clear reasoning champion across all benchmarks. This model excels across all reasoning benchmarks, particularly in complex mathematics where it approaches human expert performance. What makes this achievement remarkable is how Claude can show its work, breaking down problems step-by-step in a way that's both transparent and educational.
OpenAI's GPT-4.5 Premium takes the second spot in the reasoning hierarchy. While OpenAI hasn't released comprehensive benchmark data, the available metrics suggest impressive scientific reasoning capabilities. However, this processing power comes at a cost – GPT-4.5 operates significantly slower than its competitors, reflecting the computational intensity of its advanced reasoning processes.
Surprisingly, Google's speed-focused Gemini 2.0 Flash demonstrates unexpectedly strong reasoning abilities. Despite being designed primarily for efficiency, it performs admirably on mathematical reasoning tasks and knowledge-based assessments. This suggests Google has found ways to optimize both speed and intelligence.
Even in its standard mode, Claude 3.7 Sonnet maintains excellent reasoning capabilities, outperforming GPT-4o across various benchmarks. This is particularly evident in complex mathematical reasoning, where Claude's standard mode still demonstrates sophisticated problem-solving abilities.
While GPT-4o ranks lower in pure reasoning benchmarks, it still offers strong general capabilities. Its multimodal design prioritizes versatility over specialized reasoning, making it better suited for applications requiring balanced performance across different tasks rather than the most complex analytical challenges.
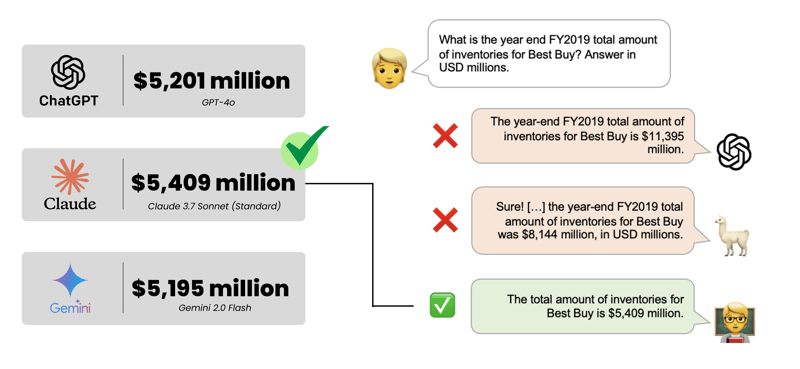
Figure 2. A question from FINANCEBENCH. The
correct answer is given by the human expert on the left.
Which Model is the Most Cost-Effective?
The economics of AI models reveal stark differences in value propositions and cost-effectiveness varies dramatically depending on your needs.
Gemini 2.0 Flash is undeniably the price champion at just $0.4 per million tokens – roughly 37× cheaper than premium models. Combined with its blazing 250 tokens/second processing speed and lowest latency (0.31), it delivers exceptional value for high-volume, time-sensitive applications. Despite its budget pricing, it maintains competitive performance across reasoning benchmarks.
GPT-4o and Claude 3.7 Sonnet (Standard) are identically priced at $15 per million tokens, placing them in the mid-range. GPT-4o offers faster processing (116 tokens/sec vs. 81), while Claude edges ahead in reasoning benchmarks. Both represent strong value propositions for general professional use.
Claude 3.7 Sonnet (Extended Thinking) maintains the same $15 per million token pricing as standard mode, making it an extraordinary value proposition given its superior performance across all reasoning benchmarks. This positions it as perhaps the best overall value for reasoning-intensive tasks despite not being the fastest option.
At the premium end of the spectrum, GPT-4.5 commands a substantial price premium that's difficult to justify for most applications. It represents a significant price premium at $75 per million tokens – 5× the cost of GPT-4o and Claude, and nearly 188× more expensive than Gemini 2.0 Flash. Combined with its slower processing speed (13 tokens/sec), it's difficult to justify for most applications unless its specific reasoning capabilities are mission-critical and budget constraints are secondary considerations.
Intelligence Index vs. Price
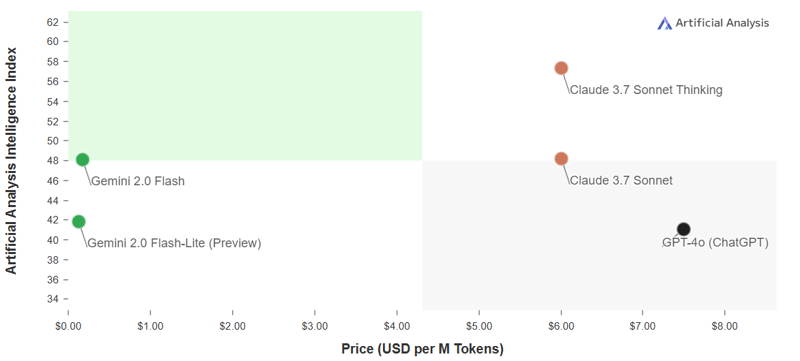
Figure 3. Intelligence Vs Price.
Source: Artificial Analysis (2025), accessed March 18, 2025.
Data, Bias, and Security Considerations
Beyond performance metrics, each of these AI systems represents different philosophical approaches to data, bias, and security – factors that may be just as important as raw capabilities for many organizations.
GPT-4o and GPT-4.5 benefit from OpenAI's extensive data collection practices, including web data, books, and user interactions. However, this raises concerns about data provenance and potential biases. OpenAI has implemented RLHF (Reinforcement Learning from Human Feedback) and red teaming to address these issues, though independent evaluations suggest some political biases remain. Security-wise, OpenAI offers enterprise-grade data encryption and retention controls.
Claude 3.7 Sonnet (Standard and Extended Thinking) reflects Anthropic's “Constitutional AI” approach, which explicitly encodes values and safety principles into the model's training. This methodology has shown advantages in reducing harmful outputs and certain types of biases. Anthropic has been particularly transparent about their data sources and filtering processes, emphasizing high-quality, properly licensed training data. Claude offers strong data privacy guarantees, with options for complete data deletion.
Gemini 2.0 Flash leverages Google's vast data resources and infrastructure advantages. However, this model has faced criticism regarding aggressive data collection practices and has shown inconsistent performance on bias benchmarks, particularly around political neutrality and cultural representations. Its security benefits from Google's extensive enterprise-grade infrastructure and compliance certifications, though organizations should weigh these against potential data governance concerns.
For financial institutions and other organizations working with sensitive information, these considerations extend beyond technical performance. Claude's constitutional approach may offer advantages in highly regulated environments, while Gemini's cost benefits might be offset by potential data governance concerns depending on regulatory requirements.
Side-by-Side Comparison: Key Metrics
Looking at these models side by side reveals distinct performance profiles that translate into different real-world strengths.
| Top Model | |
| Raw Speed | Gemini 2.0 Flash (250 tokens/sec) |
| Reasoning Strength | Claude 3.7 Extended Thinking |
| Coding Ability | Claude 3.7 Extended Thinking (98%) |
| Cost Efficiency | Gemini 2.0 Flash ($0.4) |
- Raw Speed: Gemini 2.0 Flash (250 tokens/sec) > GPT-4o (116 tokens/sec) > Claude 3.7 Sonnet (81-82 tokens/sec) > GPT-4.5 Premium (13 tokens/sec)
- Reasoning Strength: Claude 3.7 Extended Thinking > GPT-4.5 Premium > Gemini 2.0 Flash > Claude 3.7 Standard > GPT-4o
- Coding Ability: Claude 3.7 Extended Thinking (98%) > GPT-4o (94%) > Claude 3.7 Standard (92%) > Gemini 2.0 Flash (90%)
- Cost Efficiency: Gemini 2.0 Flash ($0.4) > Claude models & GPT-4o ($15) > GPT-4.5 Premium ($75)
For financial applications, the choice ultimately depends on specific needs. Time-sensitive trading operations might benefit most from Gemini's speed, while complex financial modeling and risk analysis could justify Claude's superior reasoning capabilities. GPT-4o offers a balanced middle ground, while GPT-4.5 Premium remains appropriate only for the most demanding and budget-insensitive applications.









